 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLED: LLM Enhanced Open-Vocabulary Object Detection without Human Curated Data Generation
Paper and Code
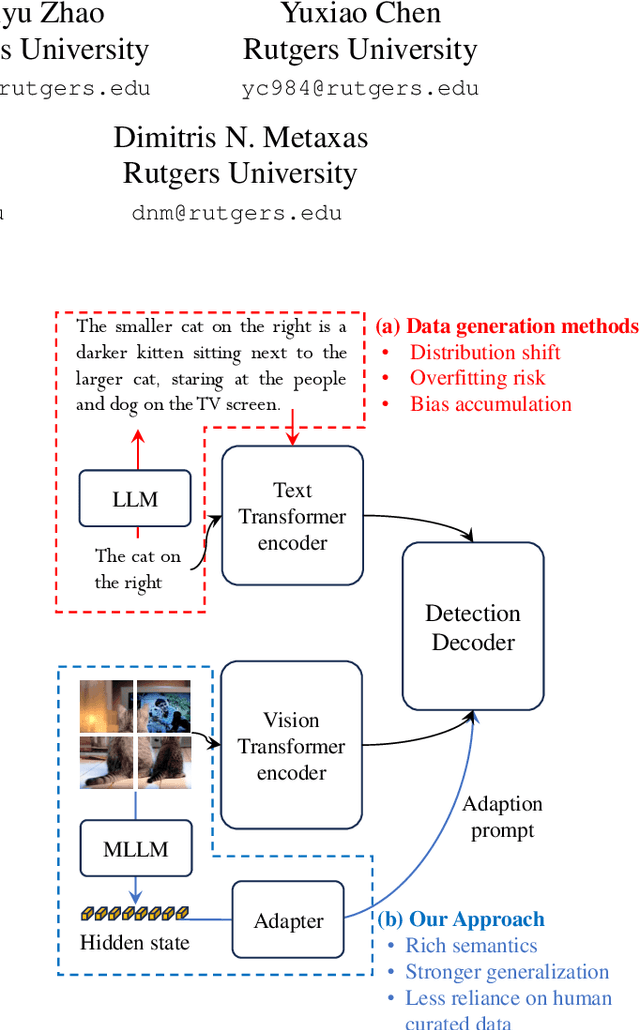
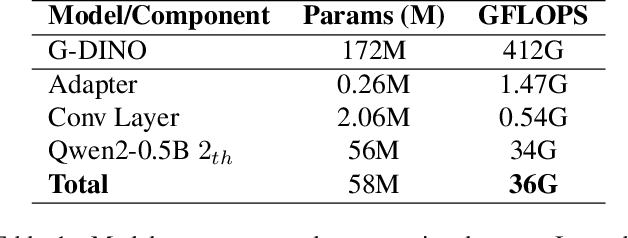
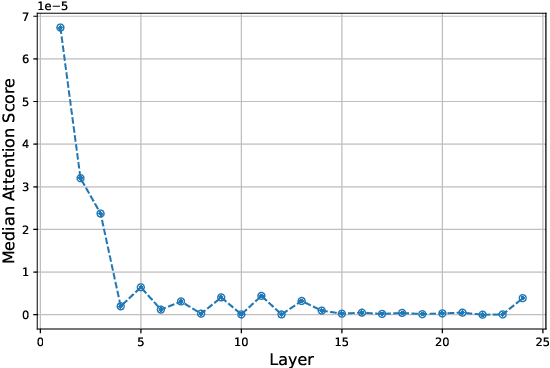
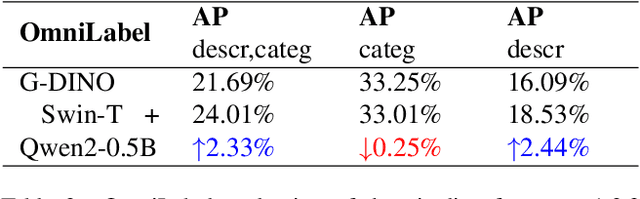
Large foundation models trained on large-scale visual-text data can significantly enhance Open Vocabulary Object Detection (OVD) through data generation. However, this may lead to biased synthetic data and overfitting to specific configurations. It can sidestep biases of manually curated data generation by directly leveraging hidden states of Large Language Models (LLMs), which is surprisingly rarely explored. This paper presents a systematic method to enhance visual grounding by utilizing decoder layers of the LLM of a MLLM. We introduce a zero-initialized cross-attention adapter to enable efficient knowledge transfer from LLMs to object detectors, an new approach called LED (LLM Enhanced Open-Vocabulary Object Detection). We demonstrate that intermediate hidden states from early LLM layers retain strong spatial-semantic correlations that are beneficial to grounding tasks. Experiments show that our adaptation strategy significantly enhances the performance on complex free-form text queries while remaining the same on plain categories. With our adaptation, Qwen2-0.5B with Swin-T as the vision encoder improves GroundingDINO by 2.33% on Omnilabel, at the overhead of 8.7% more GFLOPs. Qwen2-0.5B with a larger vision encoder can further boost the performance by 6.22%. We further validate our design by ablating on varied adapter architectures, sizes of LLMs, and which layers to add adaptation.