 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEBT-Policy: Energy Unlocks Emergent Physical Reasoning Capabilities
Oct 31, 2025Implicit policies parameterized by generative models, such as Diffusion Policy, have become the standard for policy learning and Vision-Language-Action (VLA) models in robotics. However, these approaches often suffer from high computational cost, exposure bias, and unstable inference dynamics, which lead to divergence under distribution shifts. Energy-Based Models (EBMs) address these issues by learning energy landscapes end-to-end and modeling equilibrium dynamics, offering improved robustness and reduced exposure bias. Yet, policies parameterized by EBMs have historically struggled to scale effectively. Recent work on Energy-Based Transformers (EBTs) demonstrates the scalability of EBMs to high-dimensional spaces, but their potential for solving core challenges in physically embodied models remains underexplored. We introduce a new energy-based architecture, EBT-Policy, that solves core issues in robotic and real-world settings. Across simulated and real-world tasks, EBT-Policy consistently outperforms diffusion-based policies, while requiring less training and inference computation. Remarkably, on some tasks it converges within just two inference steps, a 50x reduction compared to Diffusion Policy's 100. Moreover, EBT-Policy exhibits emergent capabilities not seen in prior models, such as zero-shot recovery from failed action sequences using only behavior cloning and without explicit retry training. By leveraging its scalar energy for uncertainty-aware inference and dynamic compute allocation, EBT-Policy offers a promising path toward robust, generalizable robot behavior under distribution shifts.
Spatial RoboGrasp: Generalized Robotic Grasping Control Policy
May 27, 2025



Achieving generalizable and precise robotic manipulation across diverse environments remains a critical challenge, largely due to limitations in spatial perception. While prior imitation-learning approaches have made progress, their reliance on raw RGB inputs and handcrafted features often leads to overfitting and poor 3D reasoning under varied lighting, occlusion, and object conditions. In this paper, we propose a unified framework that couples robust multimodal perception with reliable grasp prediction. Our architecture fuses domain-randomized augmentation, monocular depth estimation, and a depth-aware 6-DoF Grasp Prompt into a single spatial representation for downstream action planning. Conditioned on this encoding and a high-level task prompt, our diffusion-based policy yields precise action sequences, achieving up to 40% improvement in grasp success and 45% higher task success rates under environmental variation. These results demonstrate that spatially grounded perception, paired with diffusion-based imitation learning, offers a scalable and robust solution for general-purpose robotic grasping.
CoinRobot: Generalized End-to-end Robotic Learning for Physical Intelligence
Mar 07, 2025Physical intelligence holds immense promise for advancing embodied intelligence, enabling robots to acquire complex behaviors from demonstrations. However, achieving generalization and transfer across diverse robotic platforms and environments requires careful design of model architectures, training strategies, and data diversity. Meanwhile existing systems often struggle with scalability, adaptability to heterogeneous hardware, and objective evaluation in real-world settings. We present a generalized end-to-end robotic learning framework designed to bridge this gap. Our framework introduces a unified architecture that supports cross-platform adaptability, enabling seamless deployment across industrial-grade robots, collaborative arms, and novel embodiments without task-specific modifications. By integrating multi-task learning with streamlined network designs, it achieves more robust performance than conventional approaches, while maintaining compatibility with varying sensor configurations and action spaces. We validate our framework through extensive experiments on seven manipulation tasks. Notably, Diffusion-based models trained in our framework demonstrated superior performance and generalizability compared to the LeRobot framework, achieving performance improvements across diverse robotic platforms and environmental conditions.
STRIDE: Automating Reward Design, Deep Reinforcement Learning Training and Feedback Optimization in Humanoid Robotics Locomotion
Feb 10, 2025



Humanoid robotics presents significant challenges in artificial intelligence, requiring precise coordination and control of high-degree-of-freedom systems. Designing effective reward functions for deep reinforcement learning (DRL) in this domain remains a critical bottleneck, demanding extensive manual effort, domain expertise, and iterative refinement. To overcome these challenges, we introduce STRIDE, a novel framework built on agentic engineering to automate reward design, DRL training, and feedback optimization for humanoid robot locomotion tasks. By combining the structured principles of agentic engineering with large language models (LLMs) for code-writing, zero-shot generation, and in-context optimization, STRIDE generates, evaluates, and iteratively refines reward functions without relying on task-specific prompts or templates. Across diverse environments featuring humanoid robot morphologies, STRIDE outperforms the state-of-the-art reward design framework EUREKA, achieving significant improvements in efficiency and task performance. Using STRIDE-generated rewards, simulated humanoid robots achieve sprint-level locomotion across complex terrains, highlighting its ability to advance DRL workflows and humanoid robotics research.
RoboGrasp: A Universal Grasping Policy for Robust Robotic Control
Feb 05, 2025



Imitation learning and world models have shown significant promise in advancing generalizable robotic learning, with robotic grasping remaining a critical challenge for achieving precise manipulation. Existing methods often rely heavily on robot arm state data and RGB images, leading to overfitting to specific object shapes or positions. To address these limitations, we propose RoboGrasp, a universal grasping policy framework that integrates pretrained grasp detection models with robotic learning. By leveraging robust visual guidance from object detection and segmentation tasks, RoboGrasp significantly enhances grasp precision, stability, and generalizability, achieving up to 34% higher success rates in few-shot learning and grasping box prompt tasks. Built on diffusion-based methods, RoboGrasp is adaptable to various robotic learning paradigms, enabling precise and reliable manipulation across diverse and complex scenarios. This framework represents a scalable and versatile solution for tackling real-world challenges in robotic grasping.
Spatially Visual Perception for End-to-End Robotic Learning
Nov 26, 2024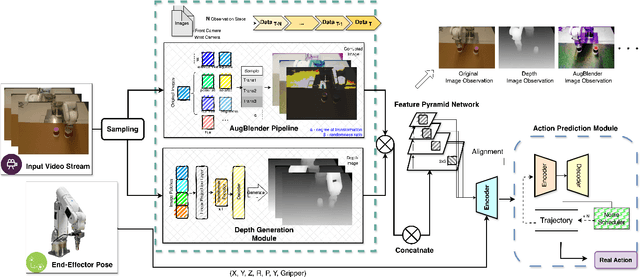
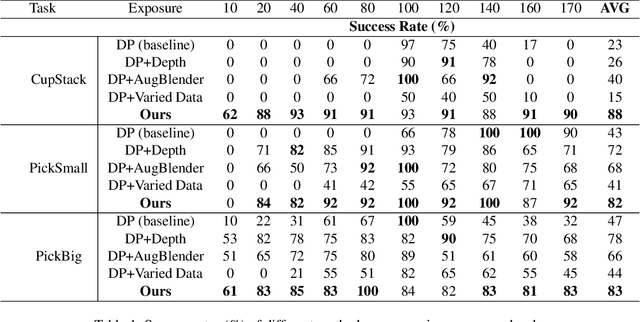


Recent advances in imitation learning have shown significant promise for robotic control and embodied intelligence. However, achieving robust generalization across diverse mounted camera observations remains a critical challenge. In this paper, we introduce a video-based spatial perception framework that leverages 3D spatial representations to address environmental variability, with a focus on handling lighting changes. Our approach integrates a novel image augmentation technique, AugBlender, with a state-of-the-art monocular depth estimation model trained on internet-scale data. Together, these components form a cohesive system designed to enhance robustness and adaptability in dynamic scenarios. Our results demonstrate that our approach significantly boosts the success rate across diverse camera exposures, where previous models experience performance collapse. Our findings highlight the potential of video-based spatial perception models in advancing robustness for end-to-end robotic learning, paving the way for scalable, low-cost solutions in embodied intelligence.
Generalized Robot Learning Framework
Sep 18, 2024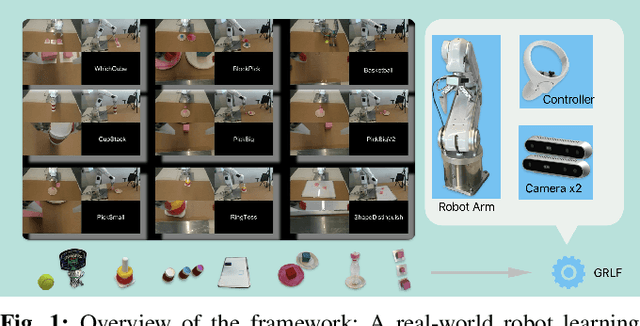
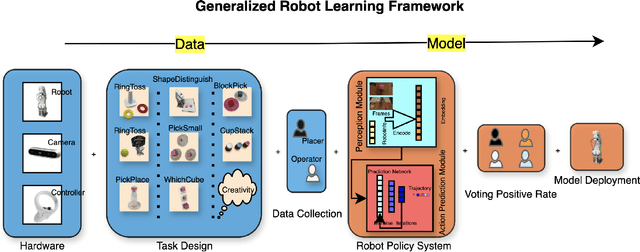

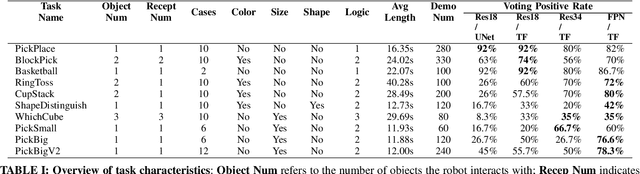
Imitation based robot learning has recently gained significant attention in the robotics field due to its theoretical potential for transferability and generalizability. However, it remains notoriously costly, both in terms of hardware and data collection, and deploying it in real-world environments demands meticulous setup of robots and precise experimental conditions. In this paper, we present a low-cost robot learning framework that is both easily reproducible and transferable to various robots and environments. We demonstrate that deployable imitation learning can be successfully applied even to industrial-grade robots, not just expensive collaborative robotic arms. Furthermore, our results show that multi-task robot learning is achievable with simple network architectures and fewer demonstrations than previously thought necessary. As the current evaluating method is almost subjective when it comes to real-world manipulation tasks, we propose Voting Positive Rate (VPR) - a novel evaluation strategy that provides a more objective assessment of performance. We conduct an extensive comparison of success rates across various self-designed tasks to validate our approach. To foster collaboration and support the robot learning community, we have open-sourced all relevant datasets and model checkpoints, available at huggingface.co/ZhiChengAI.
VisionGPT-3D: A Generalized Multimodal Agent for Enhanced 3D Vision Understanding
Mar 22, 2024



The evolution of text to visual components facilitates people's daily lives, such as generating image, videos from text and identifying the desired elements within the images. Computer vision models involving the multimodal abilities in the previous days are focused on image detection, classification based on well-defined objects. Large language models (LLMs) introduces the transformation from nature language to visual objects, which present the visual layout for text contexts. OpenAI GPT-4 has emerged as the pinnacle in LLMs, while the computer vision (CV) domain boasts a plethora of state-of-the-art (SOTA) models and algorithms to convert 2D images to their 3D representations. However, the mismatching between the algorithms with the problem could lead to undesired results. In response to this challenge, we propose an unified VisionGPT-3D framework to consolidate the state-of-the-art vision models, thereby facilitating the development of vision-oriented AI. VisionGPT-3D provides a versatile multimodal framework building upon the strengths of multimodal foundation models. It seamlessly integrates various SOTA vision models and brings the automation in the selection of SOTA vision models, identifies the suitable 3D mesh creation algorithms corresponding to 2D depth maps analysis, generates optimal results based on diverse multimodal inputs such as text prompts. Keywords: VisionGPT-3D, 3D vision understanding, Multimodal agent
VisionGPT: Vision-Language Understanding Agent Using Generalized Multimodal Framework
Mar 14, 2024

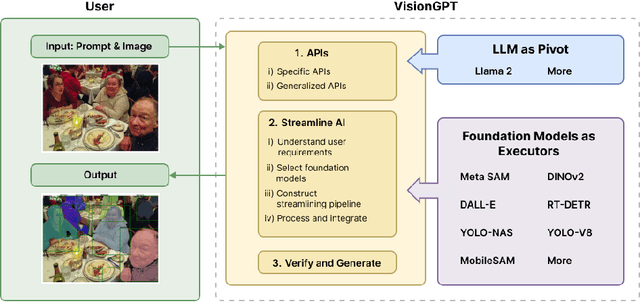

With the emergence of large language models (LLMs) and vision foundation models, how to combine the intelligence and capacity of these open-sourced or API-available models to achieve open-world visual perception remains an open question. In this paper, we introduce VisionGPT to consolidate and automate the integration of state-of-the-art foundation models, thereby facilitating vision-language understanding and the development of vision-oriented AI. VisionGPT builds upon a generalized multimodal framework that distinguishes itself through three key features: (1) utilizing LLMs (e.g., LLaMA-2) as the pivot to break down users' requests into detailed action proposals to call suitable foundation models; (2) integrating multi-source outputs from foundation models automatically and generating comprehensive responses for users; (3) adaptable to a wide range of applications such as text-conditioned image understanding/generation/editing and visual question answering. This paper outlines the architecture and capabilities of VisionGPT, demonstrating its potential to revolutionize the field of computer vision through enhanced efficiency, versatility, and generalization, and performance. Our code and models will be made publicly available. Keywords: VisionGPT, Open-world visual perception, Vision-language understanding, Large language model, and Foundation model
WorldGPT: A Sora-Inspired Video AI Agent as Rich World Models from Text and Image Inputs
Mar 10, 2024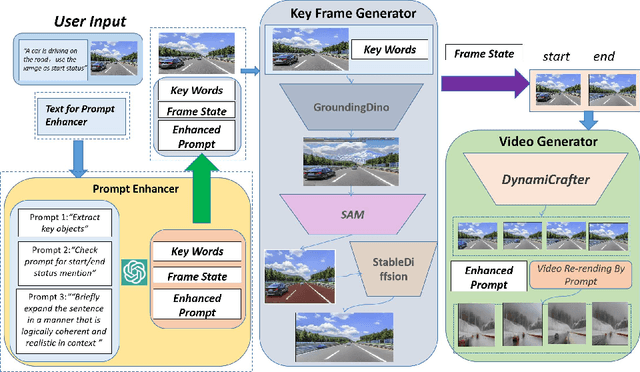
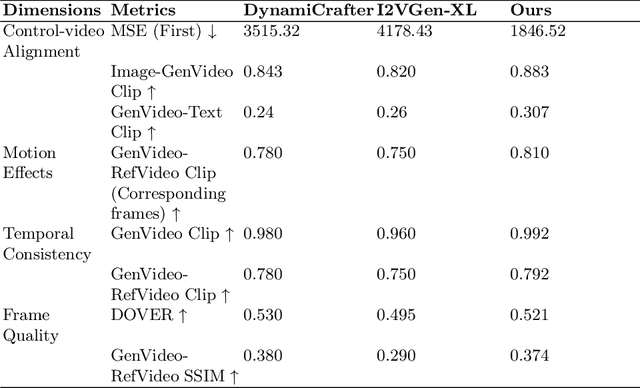


Several text-to-video diffusion models have demonstrated commendable capabilities in synthesizing high-quality video content. However, it remains a formidable challenge pertaining to maintaining temporal consistency and ensuring action smoothness throughout the generated sequences. In this paper, we present an innovative video generation AI agent that harnesses the power of Sora-inspired multimodal learning to build skilled world models framework based on textual prompts and accompanying images. The framework includes two parts: prompt enhancer and full video translation. The first part employs the capabilities of ChatGPT to meticulously distill and proactively construct precise prompts for each subsequent step, thereby guaranteeing the utmost accuracy in prompt communication and accurate execution in following model operations. The second part employ compatible with existing advanced diffusion techniques to expansively generate and refine the key frame at the conclusion of a video. Then we can expertly harness the power of leading and trailing key frames to craft videos with enhanced temporal consistency and action smoothness. The experimental results confirm that our method has strong effectiveness and novelty in constructing world models from text and image inputs over the other methods.