 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePainted Heart Beats
Nov 19, 2025
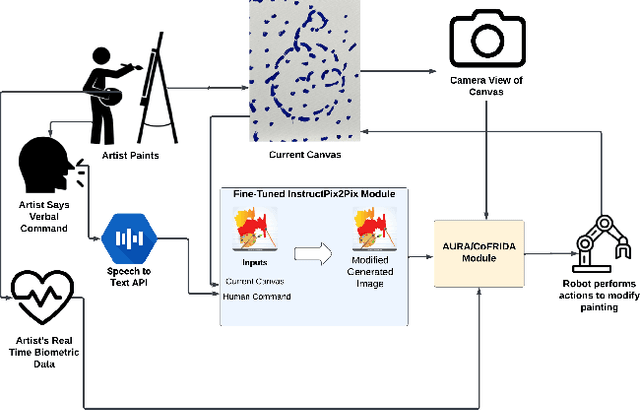
In this work we present AURA, a framework for synergistic human-artist painting. We developed a robot arm that collaboratively paints with a human artist. The robot has an awareness of the artist's heartbeat through the EmotiBit sensor, which provides the arousal levels of the painter. Given the heartbeat detected, the robot decides to increase proximity to the artist's workspace or retract. If a higher heartbeat is detected, which is associated with increased arousal in human artists, the robot will move away from that area of the canvas. If the artist's heart rate is detected as neutral, indicating the human artist's baseline state, the robot will continue its painting actions across the entire canvas. We also demonstrate and propose alternative robot-artist interactions using natural language and physical touch. This work combines the biometrics of a human artist to inform fluent artistic interactions.
VisionGPT-3D: A Generalized Multimodal Agent for Enhanced 3D Vision Understanding
Mar 22, 2024



The evolution of text to visual components facilitates people's daily lives, such as generating image, videos from text and identifying the desired elements within the images. Computer vision models involving the multimodal abilities in the previous days are focused on image detection, classification based on well-defined objects. Large language models (LLMs) introduces the transformation from nature language to visual objects, which present the visual layout for text contexts. OpenAI GPT-4 has emerged as the pinnacle in LLMs, while the computer vision (CV) domain boasts a plethora of state-of-the-art (SOTA) models and algorithms to convert 2D images to their 3D representations. However, the mismatching between the algorithms with the problem could lead to undesired results. In response to this challenge, we propose an unified VisionGPT-3D framework to consolidate the state-of-the-art vision models, thereby facilitating the development of vision-oriented AI. VisionGPT-3D provides a versatile multimodal framework building upon the strengths of multimodal foundation models. It seamlessly integrates various SOTA vision models and brings the automation in the selection of SOTA vision models, identifies the suitable 3D mesh creation algorithms corresponding to 2D depth maps analysis, generates optimal results based on diverse multimodal inputs such as text prompts. Keywords: VisionGPT-3D, 3D vision understanding, Multimodal agent
VisionGPT: Vision-Language Understanding Agent Using Generalized Multimodal Framework
Mar 14, 2024

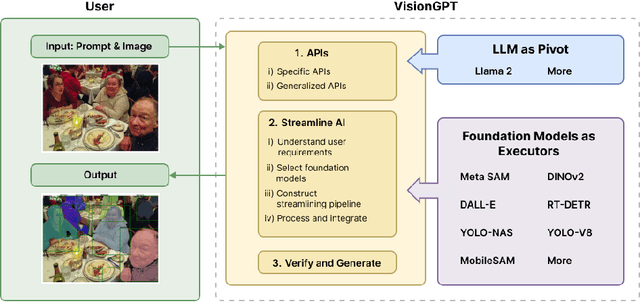

With the emergence of large language models (LLMs) and vision foundation models, how to combine the intelligence and capacity of these open-sourced or API-available models to achieve open-world visual perception remains an open question. In this paper, we introduce VisionGPT to consolidate and automate the integration of state-of-the-art foundation models, thereby facilitating vision-language understanding and the development of vision-oriented AI. VisionGPT builds upon a generalized multimodal framework that distinguishes itself through three key features: (1) utilizing LLMs (e.g., LLaMA-2) as the pivot to break down users' requests into detailed action proposals to call suitable foundation models; (2) integrating multi-source outputs from foundation models automatically and generating comprehensive responses for users; (3) adaptable to a wide range of applications such as text-conditioned image understanding/generation/editing and visual question answering. This paper outlines the architecture and capabilities of VisionGPT, demonstrating its potential to revolutionize the field of computer vision through enhanced efficiency, versatility, and generalization, and performance. Our code and models will be made publicly available. Keywords: VisionGPT, Open-world visual perception, Vision-language understanding, Large language model, and Foundation model
WorldGPT: A Sora-Inspired Video AI Agent as Rich World Models from Text and Image Inputs
Mar 10, 2024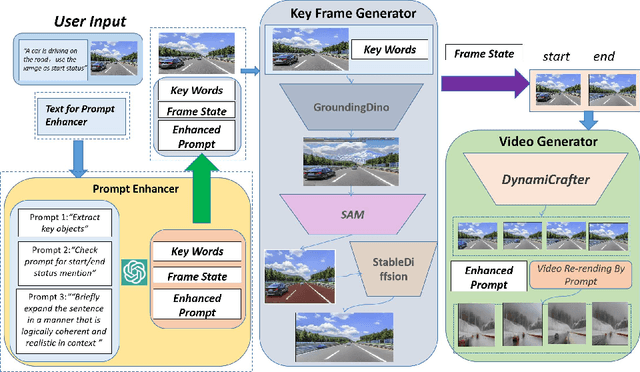
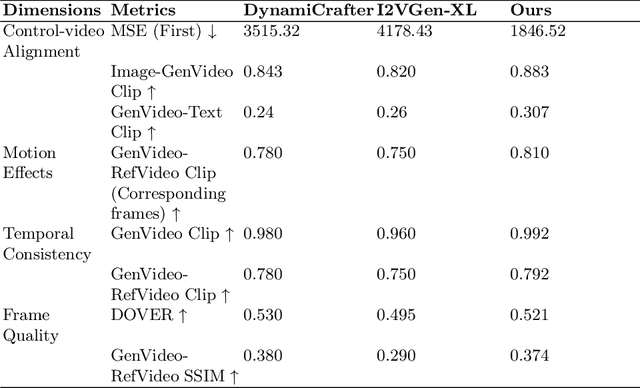


Several text-to-video diffusion models have demonstrated commendable capabilities in synthesizing high-quality video content. However, it remains a formidable challenge pertaining to maintaining temporal consistency and ensuring action smoothness throughout the generated sequences. In this paper, we present an innovative video generation AI agent that harnesses the power of Sora-inspired multimodal learning to build skilled world models framework based on textual prompts and accompanying images. The framework includes two parts: prompt enhancer and full video translation. The first part employs the capabilities of ChatGPT to meticulously distill and proactively construct precise prompts for each subsequent step, thereby guaranteeing the utmost accuracy in prompt communication and accurate execution in following model operations. The second part employ compatible with existing advanced diffusion techniques to expansively generate and refine the key frame at the conclusion of a video. Then we can expertly harness the power of leading and trailing key frames to craft videos with enhanced temporal consistency and action smoothness. The experimental results confirm that our method has strong effectiveness and novelty in constructing world models from text and image inputs over the other methods.
UnifiedVisionGPT: Streamlining Vision-Oriented AI through Generalized Multimodal Framework
Nov 16, 2023


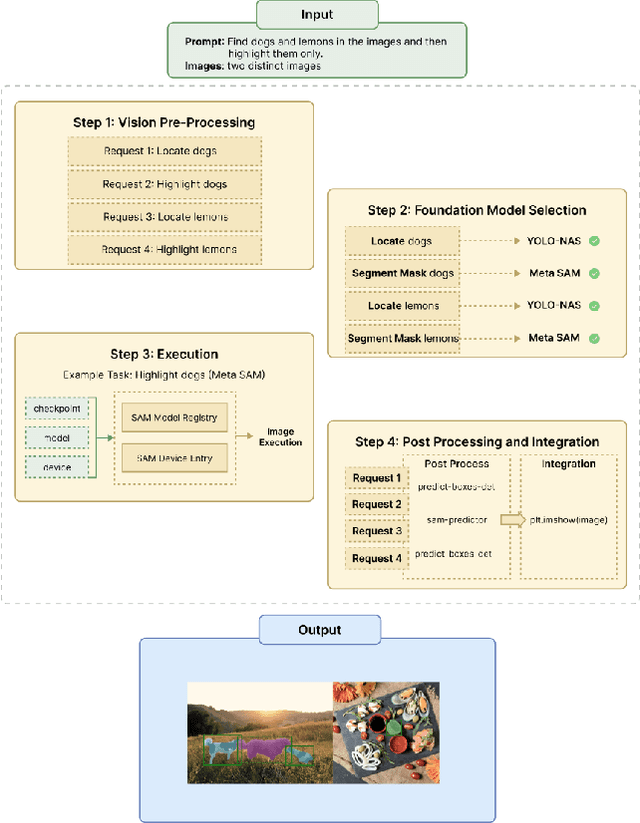
In the current landscape of artificial intelligence, foundation models serve as the bedrock for advancements in both language and vision domains. OpenAI GPT-4 has emerged as the pinnacle in large language models (LLMs), while the computer vision (CV) domain boasts a plethora of state-of-the-art (SOTA) models such as Meta's SAM and DINO, and YOLOS. However, the financial and computational burdens of training new models from scratch remain a significant barrier to progress. In response to this challenge, we introduce UnifiedVisionGPT, a novel framework designed to consolidate and automate the integration of SOTA vision models, thereby facilitating the development of vision-oriented AI. UnifiedVisionGPT distinguishes itself through four key features: (1) provides a versatile multimodal framework adaptable to a wide range of applications, building upon the strengths of multimodal foundation models; (2) seamlessly integrates various SOTA vision models to create a comprehensive multimodal platform, capitalizing on the best components of each model; (3) prioritizes vision-oriented AI, ensuring a more rapid progression in the CV domain compared to the current trajectory of LLMs; and (4) introduces automation in the selection of SOTA vision models, generating optimal results based on diverse multimodal inputs such as text prompts and images. This paper outlines the architecture and capabilities of UnifiedVisionGPT, demonstrating its potential to revolutionize the field of computer vision through enhanced efficiency, versatility, generalization, and performance. Our implementation, along with the unified multimodal framework and comprehensive dataset, is made publicly available at https://github.com/LHBuilder/SA-Segment-Anything.
PerSim: Data-Efficient Offline Reinforcement Learning with Heterogeneous Agents via Personalized Simulators
Mar 17, 2021

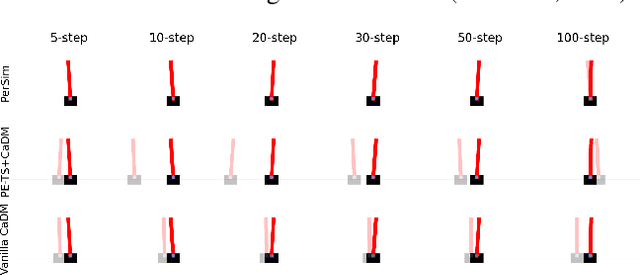
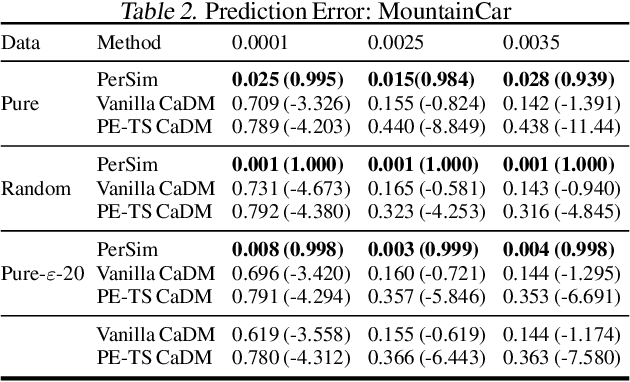
We consider offline reinforcement learning (RL) with heterogeneous agents under severe data scarcity, i.e., we only observe a single historical trajectory for every agent under an unknown, potentially sub-optimal policy. We find that the performance of state-of-the-art offline and model-based RL methods degrade significantly given such limited data availability, even for commonly perceived "solved" benchmark settings such as "MountainCar" and "CartPole". To address this challenge, we propose a model-based offline RL approach, called PerSim, where we first learn a personalized simulator for each agent by collectively using the historical trajectories across all agents prior to learning a policy. We do so by positing that the transition dynamics across agents can be represented as a latent function of latent factors associated with agents, states, and actions; subsequently, we theoretically establish that this function is well-approximated by a "low-rank" decomposition of separable agent, state, and action latent functions. This representation suggests a simple, regularized neural network architecture to effectively learn the transition dynamics per agent, even with scarce, offline data.We perform extensive experiments across several benchmark environments and RL methods. The consistent improvement of our approach, measured in terms of state dynamics prediction and eventual reward, confirms the efficacy of our framework in leveraging limited historical data to simultaneously learn personalized policies across agents.
Two Burning Questions on COVID-19: Did shutting down the economy help? Can we reopen the economy without risking the second wave?
May 10, 2020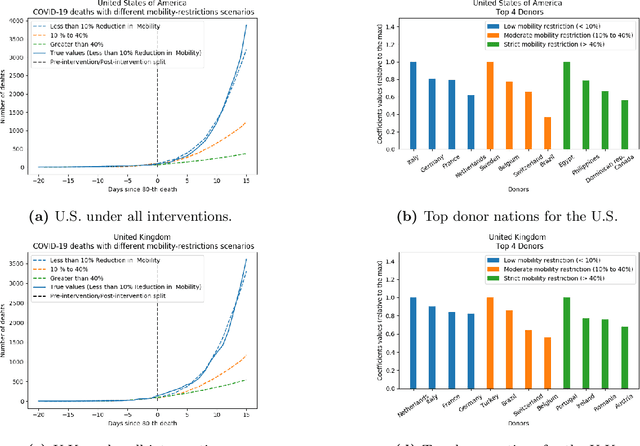
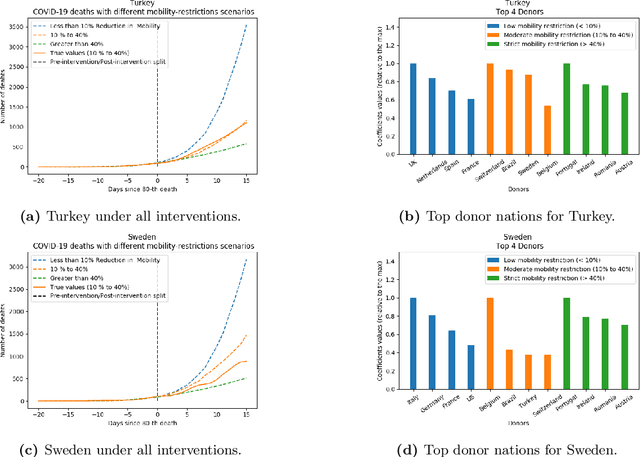
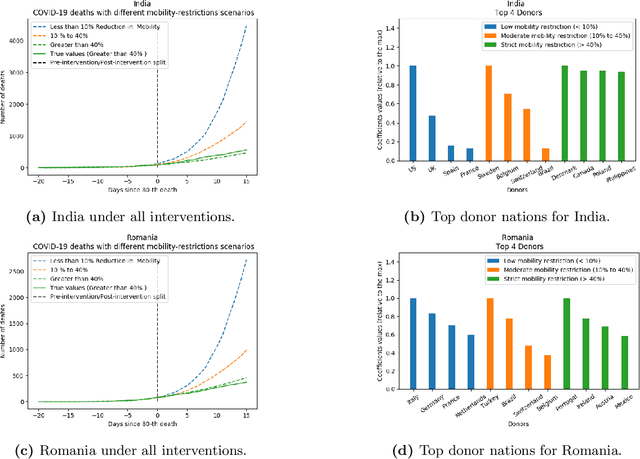
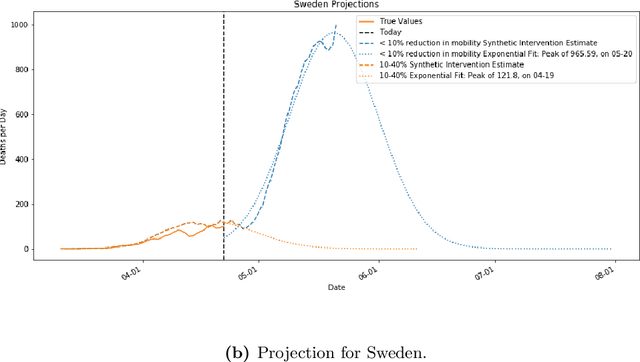
As we reach the apex of the COVID-19 pandemic, the most pressing question facing us is: can we even partially reopen the economy without risking a second wave? We first need to understand if shutting down the economy helped. And if it did, is it possible to achieve similar gains in the war against the pandemic while partially opening up the economy? To do so, it is critical to understand the effects of the various interventions that can be put into place and their corresponding health and economic implications. Since many interventions exist, the key challenge facing policy makers is understanding the potential trade-offs between them, and choosing the particular set of interventions that works best for their circumstance. In this memo, we provide an overview of Synthetic Interventions (a natural generalization of Synthetic Control), a data-driven and statistically principled method to perform what-if scenario planning, i.e., for policy makers to understand the trade-offs between different interventions before having to actually enact them. In essence, the method leverages information from different interventions that have already been enacted across the world and fits it to a policy maker's setting of interest, e.g., to estimate the effect of mobility-restricting interventions on the U.S., we use daily death data from countries that enforced severe mobility restrictions to create a "synthetic low mobility U.S." and predict the counterfactual trajectory of the U.S. if it had indeed applied a similar intervention. Using Synthetic Interventions, we find that lifting severe mobility restrictions and only retaining moderate mobility restrictions (at retail and transit locations), seems to effectively flatten the curve. We hope this provides guidance on weighing the trade-offs between the safety of the population, strain on the healthcare system, and impact on the economy.