 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGOPO: Policy Optimization using Ranked Rewards
Feb 01, 2026Standard reinforcement learning from human feedback (RLHF) trains a reward model on pairwise preference data and then uses it for policy optimization. However, while reward models are optimized to capture relative preferences, existing policy optimization techniques rely on absolute reward magnitudes during training. In settings where the rewards are non-verifiable such as summarization, instruction following, and chat completion, this misalignment often leads to suboptimal performance. We introduce Group Ordinal Policy Optimization (GOPO), a policy optimization method that uses only the ranking of the rewards and discards their magnitudes. Our rank-based transformation of rewards provides several gains, compared to Group Relative Policy Optimization (GRPO), in settings with non-verifiable rewards: (1) consistently higher training/validation reward trajectories, (2) improved LLM-as-judge evaluations across most intermediate training steps, and (3) reaching a policy of comparable quality in substantially less training steps than GRPO. We demonstrate consistent improvements across a range of tasks and model sizes.
N$^2$: A Unified Python Package and Test Bench for Nearest Neighbor-Based Matrix Completion
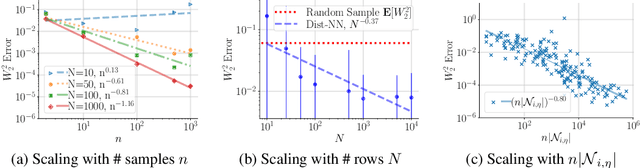
Jun 04, 2025Nearest neighbor (NN) methods have re-emerged as competitive tools for matrix completion, offering strong empirical performance and recent theoretical guarantees, including entry-wise error bounds, confidence intervals, and minimax optimality. Despite their simplicity, recent work has shown that NN approaches are robust to a range of missingness patterns and effective across diverse applications. This paper introduces N$^2$, a unified Python package and testbed that consolidates a broad class of NN-based methods through a modular, extensible interface. Built for both researchers and practitioners, N$^2$ supports rapid experimentation and benchmarking. Using this framework, we introduce a new NN variant that achieves state-of-the-art results in several settings. We also release a benchmark suite of real-world datasets, from healthcare and recommender systems to causal inference and LLM evaluation, designed to stress-test matrix completion methods beyond synthetic scenarios. Our experiments demonstrate that while classical methods excel on idealized data, NN-based techniques consistently outperform them in real-world settings.
A Causal Inference Framework for Data Rich Environments
Apr 02, 2025We propose a formal model for counterfactual estimation with unobserved confounding in "data-rich" settings, i.e., where there are a large number of units and a large number of measurements per unit. Our model provides a bridge between the structural causal model view of causal inference common in the graphical models literature with that of the latent factor model view common in the potential outcomes literature. We show how classic models for potential outcomes and treatment assignments fit within our framework. We provide an identification argument for the average treatment effect, the average treatment effect on the treated, and the average treatment effect on the untreated. For any estimator that has a fast enough estimation error rate for a certain nuisance parameter, we establish it is consistent for these various causal parameters. We then show principal component regression is one such estimator that leads to consistent estimation, and we analyze the minimal smoothness required of the potential outcomes function for consistency.
Learning Counterfactual Distributions via Kernel Nearest Neighbors
Oct 17, 2024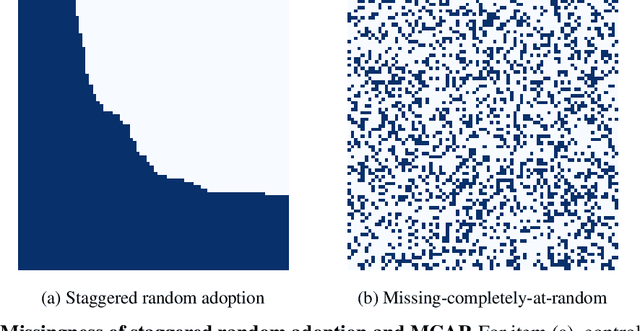
Consider a setting with multiple units (e.g., individuals, cohorts, geographic locations) and outcomes (e.g., treatments, times, items), where the goal is to learn a multivariate distribution for each unit-outcome entry, such as the distribution of a user's weekly spend and engagement under a specific mobile app version. A common challenge is the prevalence of missing not at random data, where observations are available only for certain unit-outcome combinations and the observation availability can be correlated with the properties of distributions themselves, i.e., there is unobserved confounding. An additional challenge is that for any observed unit-outcome entry, we only have a finite number of samples from the underlying distribution. We tackle these two challenges by casting the problem into a novel distributional matrix completion framework and introduce a kernel based distributional generalization of nearest neighbors to estimate the underlying distributions. By leveraging maximum mean discrepancies and a suitable factor model on the kernel mean embeddings of the underlying distributions, we establish consistent recovery of the underlying distributions even when data is missing not at random and positivity constraints are violated. Furthermore, we demonstrate that our nearest neighbors approach is robust to heteroscedastic noise, provided we have access to two or more measurements for the observed unit-outcome entries, a robustness not present in prior works on nearest neighbors with single measurements.
Distributional Matrix Completion via Nearest Neighbors in the Wasserstein Space
Oct 17, 2024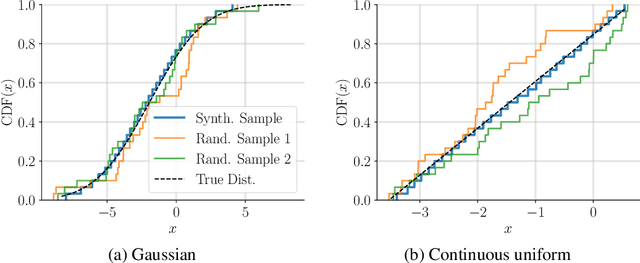
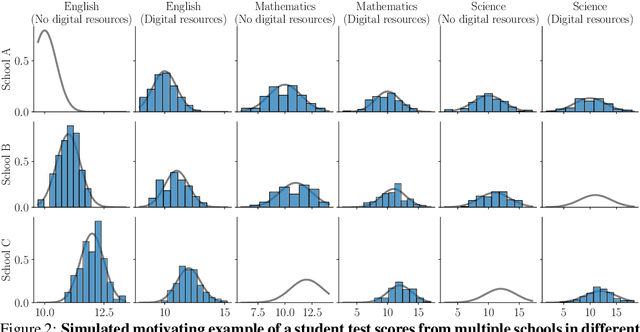
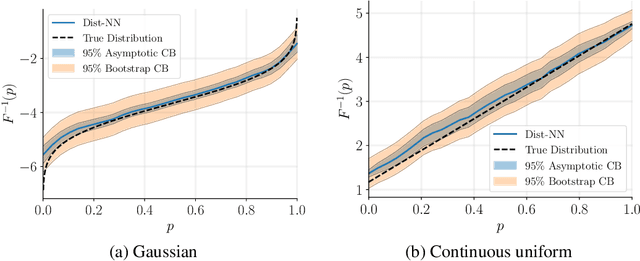
We introduce the problem of distributional matrix completion: Given a sparsely observed matrix of empirical distributions, we seek to impute the true distributions associated with both observed and unobserved matrix entries. This is a generalization of traditional matrix completion where the observations per matrix entry are scalar valued. To do so, we utilize tools from optimal transport to generalize the nearest neighbors method to the distributional setting. Under a suitable latent factor model on probability distributions, we establish that our method recovers the distributions in the Wasserstein norm. We demonstrate through simulations that our method is able to (i) provide better distributional estimates for an entry compared to using observed samples for that entry alone, (ii) yield accurate estimates of distributional quantities such as standard deviation and value-at-risk, and (iii) inherently support heteroscedastic noise. We also prove novel asymptotic results for Wasserstein barycenters over one-dimensional distributions.
Multi-Armed Bandits with Network Interference
May 28, 2024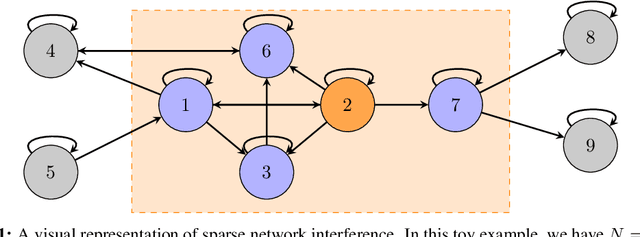
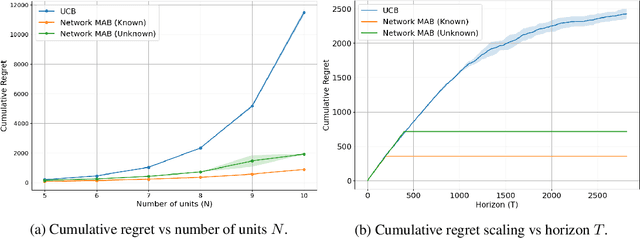
Online experimentation with interference is a common challenge in modern applications such as e-commerce and adaptive clinical trials in medicine. For example, in online marketplaces, the revenue of a good depends on discounts applied to competing goods. Statistical inference with interference is widely studied in the offline setting, but far less is known about how to adaptively assign treatments to minimize regret. We address this gap by studying a multi-armed bandit (MAB) problem where a learner (e-commerce platform) sequentially assigns one of possible $\mathcal{A}$ actions (discounts) to $N$ units (goods) over $T$ rounds to minimize regret (maximize revenue). Unlike traditional MAB problems, the reward of each unit depends on the treatments assigned to other units, i.e., there is interference across the underlying network of units. With $\mathcal{A}$ actions and $N$ units, minimizing regret is combinatorially difficult since the action space grows as $\mathcal{A}^N$. To overcome this issue, we study a sparse network interference model, where the reward of a unit is only affected by the treatments assigned to $s$ neighboring units. We use tools from discrete Fourier analysis to develop a sparse linear representation of the unit-specific reward $r_n: [\mathcal{A}]^N \rightarrow \mathbb{R} $, and propose simple, linear regression-based algorithms to minimize regret. Importantly, our algorithms achieve provably low regret both when the learner observes the interference neighborhood for all units and when it is unknown. This significantly generalizes other works on this topic which impose strict conditions on the strength of interference on a known network, and also compare regret to a markedly weaker optimal action. Empirically, we corroborate our theoretical findings via numerical simulations.
Doubly Robust Inference in Causal Latent Factor Models
Feb 18, 2024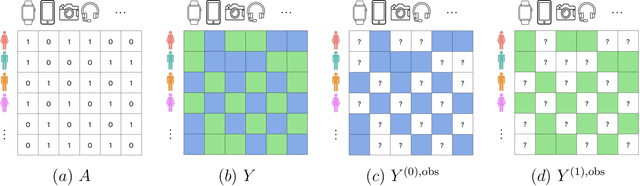
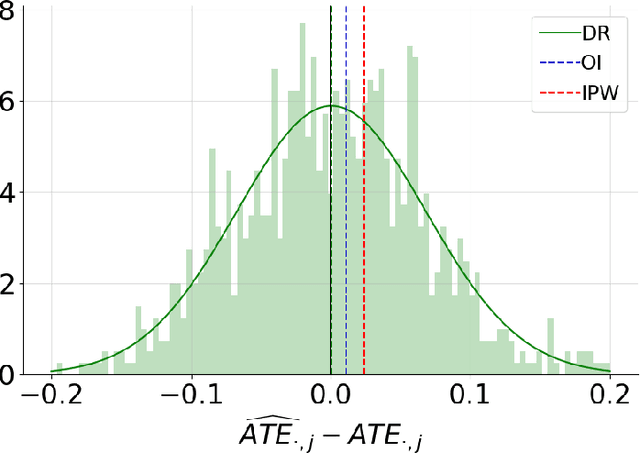
This article introduces a new framework for estimating average treatment effects under unobserved confounding in modern data-rich environments featuring large numbers of units and outcomes. The proposed estimator is doubly robust, combining outcome imputation, inverse probability weighting, and a novel cross-fitting procedure for matrix completion. We derive finite-sample and asymptotic guarantees, and show that the error of the new estimator converges to a mean-zero Gaussian distribution at a parametric rate. Simulation results demonstrate the practical relevance of the formal properties of the estimators analyzed in this article.
Incentive-Aware Synthetic Control: Accurate Counterfactual Estimation via Incentivized Exploration
Dec 26, 2023
We consider a panel data setting in which one observes measurements of units over time, under different interventions. Our focus is on the canonical family of synthetic control methods (SCMs) which, after a pre-intervention time period when all units are under control, estimate counterfactual outcomes for test units in the post-intervention time period under control by using data from donor units who have remained under control for the entire post-intervention period. In order for the counterfactual estimate produced by synthetic control for a test unit to be accurate, there must be sufficient overlap between the outcomes of the donor units and the outcomes of the test unit. As a result, a canonical assumption in the literature on SCMs is that the outcomes for the test units lie within either the convex hull or the linear span of the outcomes for the donor units. However despite their ubiquity, such overlap assumptions may not always hold, as is the case when, e.g., units select their own interventions and different subpopulations of units prefer different interventions a priori. We shed light on this typically overlooked assumption, and we address this issue by incentivizing units with different preferences to take interventions they would not normally consider. Specifically, we provide a SCM for incentivizing exploration in panel data settings which provides incentive-compatible intervention recommendations to units by leveraging tools from information design and online learning. Using our algorithm, we show how to obtain valid counterfactual estimates using SCMs without the need for an explicit overlap assumption on the unit outcomes.
Adaptive Principal Component Regression with Applications to Panel Data
Jul 03, 2023Principal component regression (PCR) is a popular technique for fixed-design error-in-variables regression, a generalization of the linear regression setting in which the observed covariates are corrupted with random noise. We provide the first time-uniform finite sample guarantees for online (regularized) PCR whenever data is collected adaptively. Since the proof techniques for analyzing PCR in the fixed design setting do not readily extend to the online setting, our results rely on adapting tools from modern martingale concentration to the error-in-variables setting. As an application of our bounds, we provide a framework for experiment design in panel data settings when interventions are assigned adaptively. Our framework may be thought of as a generalization of the synthetic control and synthetic interventions frameworks, where data is collected via an adaptive intervention assignment policy.
Estimating the Value of Evidence-Based Decision Making
Jun 21, 2023

Business/policy decisions are often based on evidence from randomized experiments and observational studies. In this article we propose an empirical framework to estimate the value of evidence-based decision making (EBDM) and the return on the investment in statistical precision.