 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTime-Aware Synthetic Control
Jan 06, 2026The synthetic control (SC) framework is widely used for observational causal inference with time-series panel data. SC has been successful in diverse applications, but existing methods typically treat the ordering of pre-intervention time indices interchangeable. This invariance means they may not fully take advantage of temporal structure when strong trends are present. We propose Time-Aware Synthetic Control (TASC), which employs a state-space model with a constant trend while preserving a low-rank structure of the signal. TASC uses the Kalman filter and Rauch-Tung-Striebel smoother: it first fits a generative time-series model with expectation-maximization and then performs counterfactual inference. We evaluate TASC on both simulated and real-world datasets, including policy evaluation and sports prediction. Our results suggest that TASC offers advantages in settings with strong temporal trends and high levels of observation noise.
Efficiently Learning Synthetic Control Models for High-dimensional Disaggregated Data
Oct 26, 2025The Synthetic Control method (SC) has become a valuable tool for estimating causal effects. Originally designed for single-treated unit scenarios, it has recently found applications in high-dimensional disaggregated settings with multiple treated units. However, challenges in practical implementation and computational efficiency arise in such scenarios. To tackle these challenges, we propose a novel approach that integrates the Multivariate Square-root Lasso method into the synthetic control framework. We rigorously establish the estimation error bounds for fitting the Synthetic Control weights using Multivariate Square-root Lasso, accommodating high-dimensionality and time series dependencies. Additionally, we quantify the estimation error for the Average Treatment Effect on the Treated (ATT). Through simulation studies, we demonstrate that our method offers superior computational efficiency without compromising estimation accuracy. We apply our method to assess the causal impact of COVID-19 Stay-at-Home Orders on the monthly unemployment rate in the United States at the county level.
A Causal Inference Framework for Data Rich Environments
Apr 02, 2025We propose a formal model for counterfactual estimation with unobserved confounding in "data-rich" settings, i.e., where there are a large number of units and a large number of measurements per unit. Our model provides a bridge between the structural causal model view of causal inference common in the graphical models literature with that of the latent factor model view common in the potential outcomes literature. We show how classic models for potential outcomes and treatment assignments fit within our framework. We provide an identification argument for the average treatment effect, the average treatment effect on the treated, and the average treatment effect on the untreated. For any estimator that has a fast enough estimation error rate for a certain nuisance parameter, we establish it is consistent for these various causal parameters. We then show principal component regression is one such estimator that leads to consistent estimation, and we analyze the minimal smoothness required of the potential outcomes function for consistency.
Doubly Robust Inference in Causal Latent Factor Models
Feb 18, 2024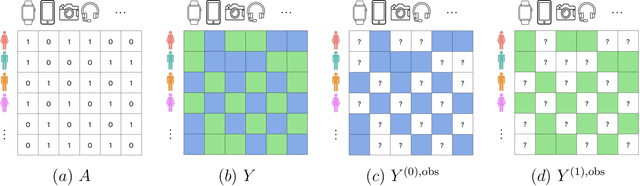
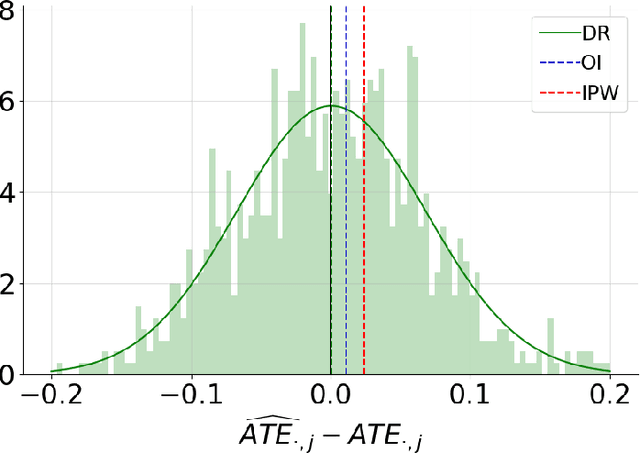
This article introduces a new framework for estimating average treatment effects under unobserved confounding in modern data-rich environments featuring large numbers of units and outcomes. The proposed estimator is doubly robust, combining outcome imputation, inverse probability weighting, and a novel cross-fitting procedure for matrix completion. We derive finite-sample and asymptotic guarantees, and show that the error of the new estimator converges to a mean-zero Gaussian distribution at a parametric rate. Simulation results demonstrate the practical relevance of the formal properties of the estimators analyzed in this article.
Estimating the Value of Evidence-Based Decision Making
Jun 21, 2023

Business/policy decisions are often based on evidence from randomized experiments and observational studies. In this article we propose an empirical framework to estimate the value of evidence-based decision making (EBDM) and the return on the investment in statistical precision.
The Risk of Machine Learning
Mar 31, 2017
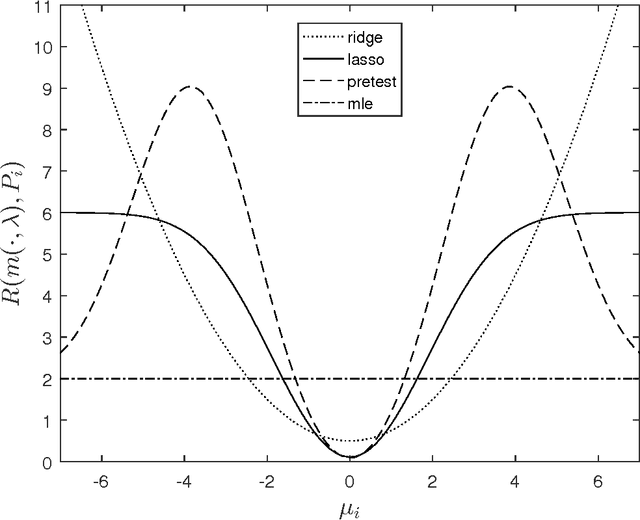
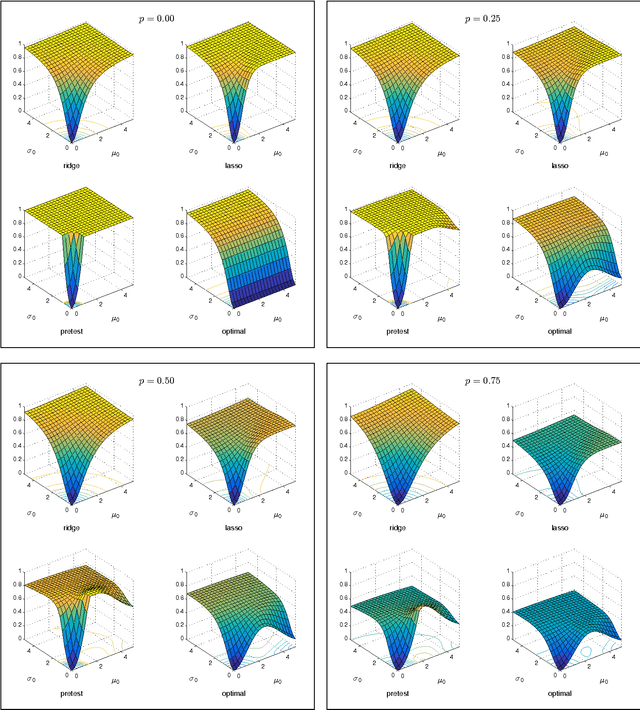
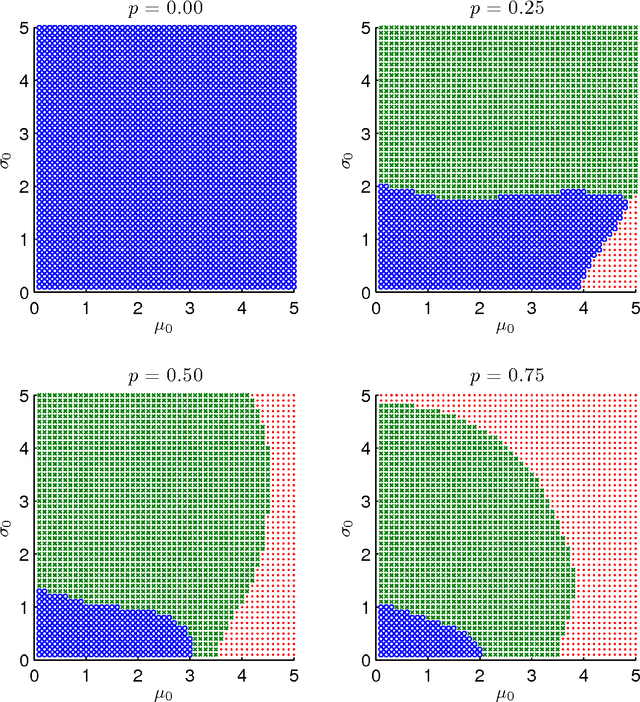
Many applied settings in empirical economics involve simultaneous estimation of a large number of parameters. In particular, applied economists are often interested in estimating the effects of many-valued treatments (like teacher effects or location effects), treatment effects for many groups, and prediction models with many regressors. In these settings, machine learning methods that combine regularized estimation and data-driven choices of regularization parameters are useful to avoid over-fitting. In this article, we analyze the performance of a class of machine learning estimators that includes ridge, lasso and pretest in contexts that require simultaneous estimation of many parameters. Our analysis aims to provide guidance to applied researchers on (i) the choice between regularized estimators in practice and (ii) data-driven selection of regularization parameters. To address (i), we characterize the risk (mean squared error) of regularized estimators and derive their relative performance as a function of simple features of the data generating process. To address (ii), we show that data-driven choices of regularization parameters, based on Stein's unbiased risk estimate or on cross-validation, yield estimators with risk uniformly close to the risk attained under the optimal (unfeasible) choice of regularization parameters. We use data from recent examples in the empirical economics literature to illustrate the practical applicability of our results.