 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive maximization of social welfare
Oct 14, 2023



We consider the problem of repeatedly choosing policies to maximize social welfare. Welfare is a weighted sum of private utility and public revenue. Earlier outcomes inform later policies. Utility is not observed, but indirectly inferred. Response functions are learned through experimentation. We derive a lower bound on regret, and a matching adversarial upper bound for a variant of the Exp3 algorithm. Cumulative regret grows at a rate of $T^{2/3}$. This implies that (i) welfare maximization is harder than the multi-armed bandit problem (with a rate of $T^{1/2}$ for finite policy sets), and (ii) our algorithm achieves the optimal rate. For the stochastic setting, if social welfare is concave, we can achieve a rate of $T^{1/2}$ (for continuous policy sets), using a dyadic search algorithm. We analyze an extension to nonlinear income taxation, and sketch an extension to commodity taxation. We compare our setting to monopoly pricing (which is easier), and price setting for bilateral trade (which is harder).
Adaptive Combinatorial Allocation
Nov 04, 2020
We consider settings where an allocation has to be chosen repeatedly, returns are unknown but can be learned, and decisions are subject to constraints. Our model covers two-sided and one-sided matching, even with complex constraints. We propose an approach based on Thompson sampling. Our main result is a prior-independent finite-sample bound on the expected regret for this algorithm. Although the number of allocations grows exponentially in the number of participants, the bound does not depend on this number. We illustrate the performance of our algorithm using data on refugee resettlement in the United States.
Approximate Cross-validation: Guarantees for Model Assessment and Selection
Mar 02, 2020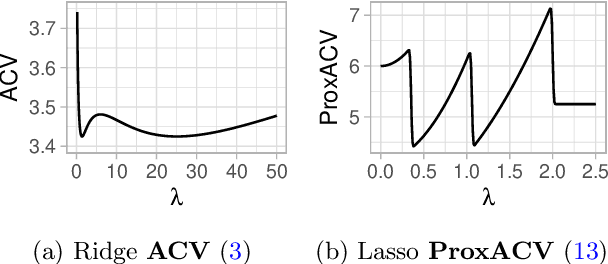

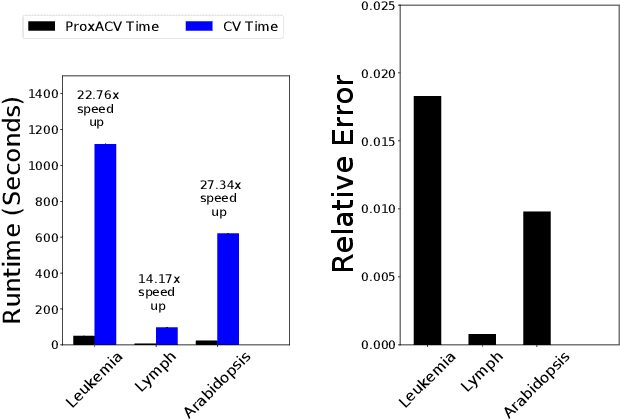
Cross-validation (CV) is a popular approach for assessing and selecting predictive models. However, when the number of folds is large, CV suffers from a need to repeatedly refit a learning procedure on a large number of training datasets. Recent work in empirical risk minimization (ERM) approximates the expensive refitting with a single Newton step warm-started from the full training set optimizer. While this can greatly reduce runtime, several open questions remain including whether these approximations lead to faithful model selection and whether they are suitable for non-smooth objectives. We address these questions with three main contributions: (i) we provide uniform non-asymptotic, deterministic model assessment guarantees for approximate CV; (ii) we show that (roughly) the same conditions also guarantee model selection performance comparable to CV; (iii) we provide a proximal Newton extension of the approximate CV framework for non-smooth prediction problems and develop improved assessment guarantees for problems such as l1-regularized ERM.
The Risk of Machine Learning
Mar 31, 2017
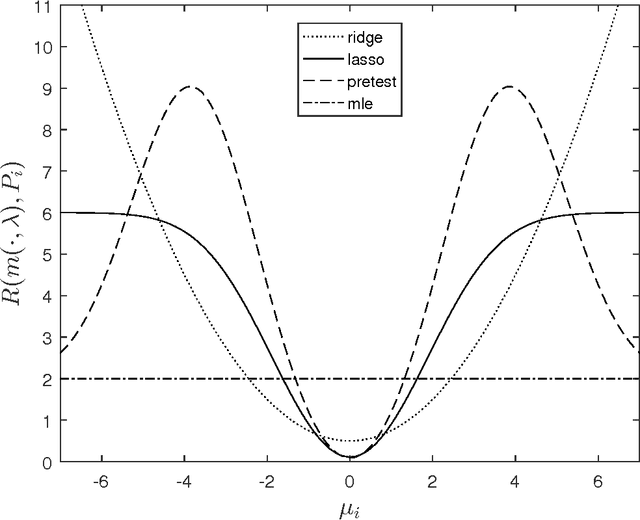
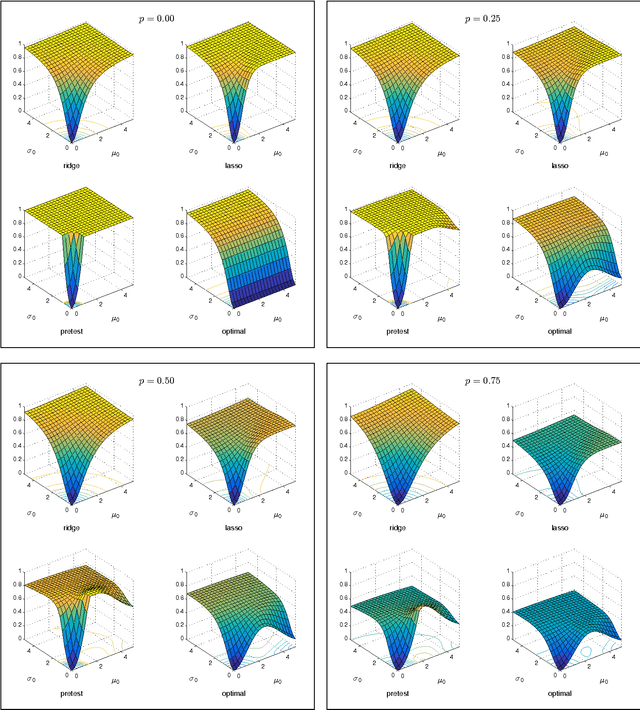
Many applied settings in empirical economics involve simultaneous estimation of a large number of parameters. In particular, applied economists are often interested in estimating the effects of many-valued treatments (like teacher effects or location effects), treatment effects for many groups, and prediction models with many regressors. In these settings, machine learning methods that combine regularized estimation and data-driven choices of regularization parameters are useful to avoid over-fitting. In this article, we analyze the performance of a class of machine learning estimators that includes ridge, lasso and pretest in contexts that require simultaneous estimation of many parameters. Our analysis aims to provide guidance to applied researchers on (i) the choice between regularized estimators in practice and (ii) data-driven selection of regularization parameters. To address (i), we characterize the risk (mean squared error) of regularized estimators and derive their relative performance as a function of simple features of the data generating process. To address (ii), we show that data-driven choices of regularization parameters, based on Stein's unbiased risk estimate or on cross-validation, yield estimators with risk uniformly close to the risk attained under the optimal (unfeasible) choice of regularization parameters. We use data from recent examples in the empirical economics literature to illustrate the practical applicability of our results.