 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKerJEPA: Kernel Discrepancies for Euclidean Self-Supervised Learning
Dec 22, 2025Recent breakthroughs in self-supervised Joint-Embedding Predictive Architectures (JEPAs) have established that regularizing Euclidean representations toward isotropic Gaussian priors yields provable gains in training stability and downstream generalization. We introduce a new, flexible family of KerJEPAs, self-supervised learning algorithms with kernel-based regularizers. One instance of this family corresponds to the recently-introduced LeJEPA Epps-Pulley regularizer which approximates a sliced maximum mean discrepancy (MMD) with a Gaussian prior and Gaussian kernel. By expanding the class of viable kernels and priors and computing the closed-form high-dimensional limit of sliced MMDs, we develop alternative KerJEPAs with a number of favorable properties including improved training stability and design flexibility.
Estimating Treatment Effects with Independent Component Analysis
Jul 22, 2025The field of causal inference has developed a variety of methods to accurately estimate treatment effects in the presence of nuisance. Meanwhile, the field of identifiability theory has developed methods like Independent Component Analysis (ICA) to identify latent sources and mixing weights from data. While these two research communities have developed largely independently, they aim to achieve similar goals: the accurate and sample-efficient estimation of model parameters. In the partially linear regression (PLR) setting, Mackey et al. (2018) recently found that estimation consistency can be improved with non-Gaussian treatment noise. Non-Gaussianity is also a crucial assumption for identifying latent factors in ICA. We provide the first theoretical and empirical insights into this connection, showing that ICA can be used for causal effect estimation in the PLR model. Surprisingly, we find that linear ICA can accurately estimate multiple treatment effects even in the presence of Gaussian confounders or nonlinear nuisance.
It's Hard to Be Normal: The Impact of Noise on Structure-agnostic Estimation
Jul 03, 2025Structure-agnostic causal inference studies how well one can estimate a treatment effect given black-box machine learning estimates of nuisance functions (like the impact of confounders on treatment and outcomes). Here, we find that the answer depends in a surprising way on the distribution of the treatment noise. Focusing on the partially linear model of \citet{robinson1988root}, we first show that the widely adopted double machine learning (DML) estimator is minimax rate-optimal for Gaussian treatment noise, resolving an open problem of \citet{mackey2018orthogonal}. Meanwhile, for independent non-Gaussian treatment noise, we show that DML is always suboptimal by constructing new practical procedures with higher-order robustness to nuisance errors. These \emph{ACE} procedures use structure-agnostic cumulant estimators to achieve $r$-th order insensitivity to nuisance errors whenever the $(r+1)$-st treatment cumulant is non-zero. We complement these core results with novel minimax guarantees for binary treatments in the partially linear model. Finally, using synthetic demand estimation experiments, we demonstrate the practical benefits of our higher-order robust estimators.
Causal integration of chemical structures improves representations of microscopy images for morphological profiling
Apr 13, 2025Recent advances in self-supervised deep learning have improved our ability to quantify cellular morphological changes in high-throughput microscopy screens, a process known as morphological profiling. However, most current methods only learn from images, despite many screens being inherently multimodal, as they involve both a chemical or genetic perturbation as well as an image-based readout. We hypothesized that incorporating chemical compound structure during self-supervised pre-training could improve learned representations of images in high-throughput microscopy screens. We introduce a representation learning framework, MICON (Molecular-Image Contrastive Learning), that models chemical compounds as treatments that induce counterfactual transformations of cell phenotypes. MICON significantly outperforms classical hand-crafted features such as CellProfiler and existing deep-learning-based representation learning methods in challenging evaluation settings where models must identify reproducible effects of drugs across independent replicates and data-generating centers. We demonstrate that incorporating chemical compound information into the learning process provides consistent improvements in our evaluation setting and that modeling compounds specifically as treatments in a causal framework outperforms approaches that directly align images and compounds in a single representation space. Our findings point to a new direction for representation learning in morphological profiling, suggesting that methods should explicitly account for the multimodal nature of microscopy screening data.
Low-Rank Thinning
Feb 17, 2025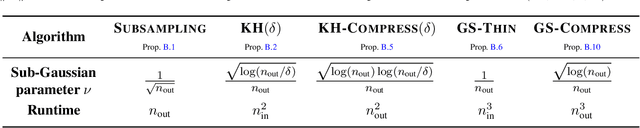

The goal in thinning is to summarize a dataset using a small set of representative points. Remarkably, sub-Gaussian thinning algorithms like Kernel Halving and Compress can match the quality of uniform subsampling while substantially reducing the number of summary points. However, existing guarantees cover only a restricted range of distributions and kernel-based quality measures and suffer from pessimistic dimension dependence. To address these deficiencies, we introduce a new low-rank analysis of sub-Gaussian thinning that applies to any distribution and any kernel, guaranteeing high-quality compression whenever the kernel or data matrix is approximately low-rank. To demonstrate the broad applicability of the techniques, we design practical sub-Gaussian thinning approaches that improve upon the best known guarantees for approximating attention in transformers, accelerating stochastic gradient training through reordering, and distinguishing distributions in near-linear time.
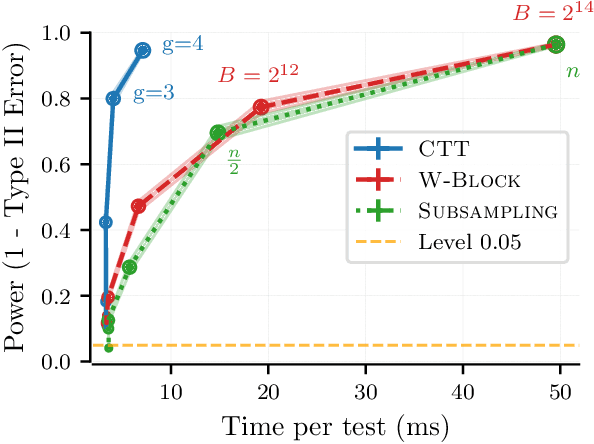
Cheap Permutation Testing
Feb 11, 2025Permutation tests are a popular choice for distinguishing distributions and testing independence, due to their exact, finite-sample control of false positives and their minimax optimality when paired with U-statistics. However, standard permutation tests are also expensive, requiring a test statistic to be computed hundreds or thousands of times to detect a separation between distributions. In this work, we offer a simple approach to accelerate testing: group your datapoints into bins and permute only those bins. For U and V-statistics, we prove that these cheap permutation tests have two remarkable properties. First, by storing appropriate sufficient statistics, a cheap test can be run in time comparable to evaluating a single test statistic. Second, cheap permutation power closely approximates standard permutation power. As a result, cheap tests inherit the exact false positive control and minimax optimality of standard permutation tests while running in a fraction of the time. We complement these findings with improved power guarantees for standard permutation testing and experiments demonstrating the benefits of cheap permutations over standard maximum mean discrepancy (MMD), Hilbert-Schmidt independence criterion (HSIC), random Fourier feature, Wilcoxon-Mann-Whitney, cross-MMD, and cross-HSIC tests.
SureMap: Simultaneous Mean Estimation for Single-Task and Multi-Task Disaggregated Evaluation
Nov 14, 2024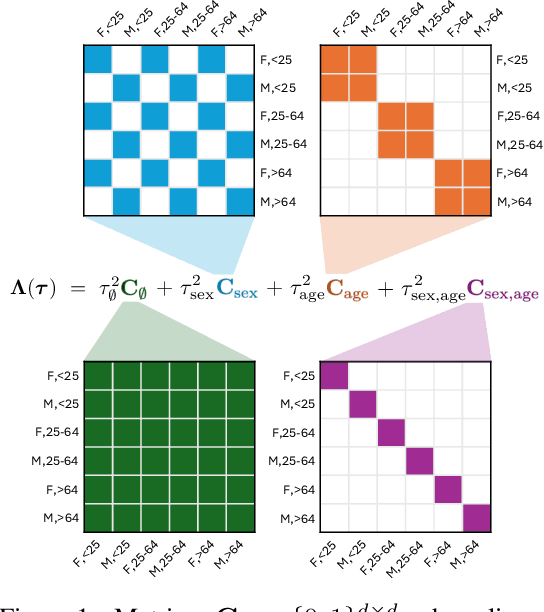


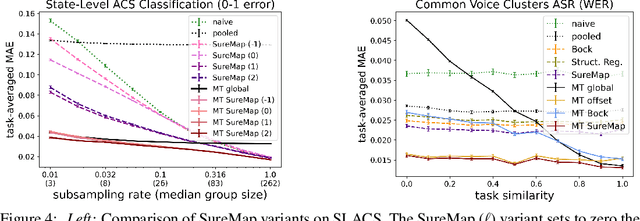
Disaggregated evaluation -- estimation of performance of a machine learning model on different subpopulations -- is a core task when assessing performance and group-fairness of AI systems. A key challenge is that evaluation data is scarce, and subpopulations arising from intersections of attributes (e.g., race, sex, age) are often tiny. Today, it is common for multiple clients to procure the same AI model from a model developer, and the task of disaggregated evaluation is faced by each customer individually. This gives rise to what we call the multi-task disaggregated evaluation problem, wherein multiple clients seek to conduct a disaggregated evaluation of a given model in their own data setting (task). In this work we develop a disaggregated evaluation method called SureMap that has high estimation accuracy for both multi-task and single-task disaggregated evaluations of blackbox models. SureMap's efficiency gains come from (1) transforming the problem into structured simultaneous Gaussian mean estimation and (2) incorporating external data, e.g., from the AI system creator or from their other clients. Our method combines maximum a posteriori (MAP) estimation using a well-chosen prior together with cross-validation-free tuning via Stein's unbiased risk estimate (SURE). We evaluate SureMap on disaggregated evaluation tasks in multiple domains, observing significant accuracy improvements over several strong competitors.
Adapting Language Models via Token Translation
Nov 01, 2024Modern large language models use a fixed tokenizer to effectively compress text drawn from a source domain. However, applying the same tokenizer to a new target domain often leads to inferior compression, more costly inference, and reduced semantic alignment. To address this deficiency, we introduce Sparse Sinkhorn Token Translation (S2T2). S2T2 trains a tailored tokenizer for the target domain and learns to translate between target and source tokens, enabling more effective reuse of the pre-trained next-source-token predictor. In our experiments with finetuned English language models, S2T2 improves both the perplexity and the compression of out-of-domain protein sequences, outperforming direct finetuning with either the source or target tokenizer. In addition, we find that token translations learned for smaller, less expensive models can be directly transferred to larger, more powerful models to reap the benefits of S2T2 at lower cost.
Informed Correctors for Discrete Diffusion Models
Jul 30, 2024Discrete diffusion modeling is a promising framework for modeling and generating data in discrete spaces. To sample from these models, different strategies present trade-offs between computation and sample quality. A predominant sampling strategy is predictor-corrector $\tau$-leaping, which simulates the continuous time generative process with discretized predictor steps and counteracts the accumulation of discretization error via corrector steps. However, for absorbing state diffusion, an important class of discrete diffusion models, the standard forward-backward corrector can be ineffective in fixing such errors, resulting in subpar sample quality. To remedy this problem, we propose a family of informed correctors that more reliably counteracts discretization error by leveraging information learned by the model. For further efficiency gains, we also propose $k$-Gillespie's, a sampling algorithm that better utilizes each model evaluation, while still enjoying the speed and flexibility of $\tau$-leaping. Across several real and synthetic datasets, we show that $k$-Gillespie's with informed correctors reliably produces higher quality samples at lower computational cost.
Debiased Distribution Compression
Apr 18, 2024



Modern compression methods can summarize a target distribution $\mathbb{P}$ more succinctly than i.i.d. sampling but require access to a low-bias input sequence like a Markov chain converging quickly to $\mathbb{P}$. We introduce a new suite of compression methods suitable for compression with biased input sequences. Given $n$ points targeting the wrong distribution and quadratic time, Stein Kernel Thinning (SKT) returns $\sqrt{n}$ equal-weighted points with $\widetilde{O}(n^{-1/2})$ maximum mean discrepancy (MMD) to $\mathbb {P}$. For larger-scale compression tasks, Low-rank SKT achieves the same feat in sub-quadratic time using an adaptive low-rank debiasing procedure that may be of independent interest. For downstream tasks that support simplex or constant-preserving weights, Stein Recombination and Stein Cholesky achieve even greater parsimony, matching the guarantees of SKT with as few as $\operatorname{poly-log}(n)$ weighted points. Underlying these advances are new guarantees for the quality of simplex-weighted coresets, the spectral decay of kernel matrices, and the covering numbers of Stein kernel Hilbert spaces. In our experiments, our techniques provide succinct and accurate posterior summaries while overcoming biases due to burn-in, approximate Markov chain Monte Carlo, and tempering.