 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Supervised Alignment with Mutual Information: Learning to Follow Principles without Preference Labels
Apr 22, 2024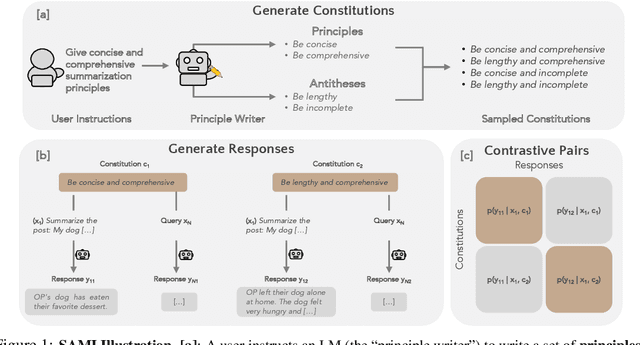
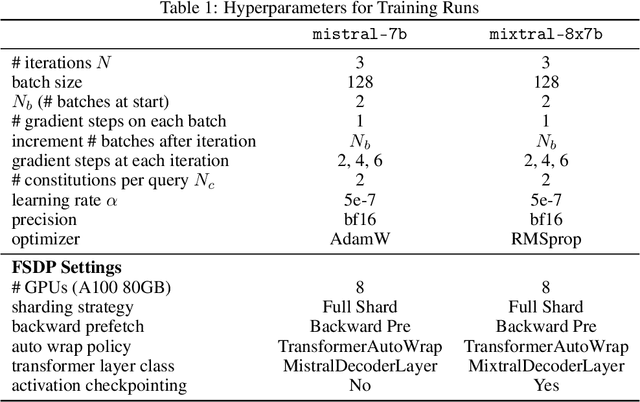
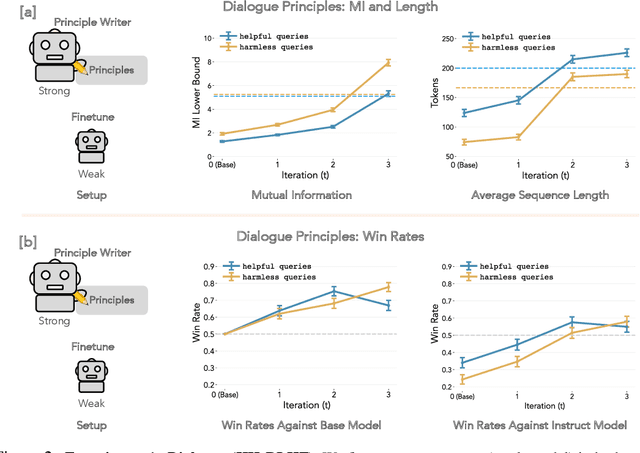

When prompting a language model (LM), users frequently expect the model to adhere to a set of behavioral principles across diverse tasks, such as producing insightful content while avoiding harmful or biased language. Instilling such principles into a model can be resource-intensive and technically challenging, generally requiring human preference labels or examples. We introduce SAMI, a method for teaching a pretrained LM to follow behavioral principles that does not require any preference labels or demonstrations. SAMI is an iterative algorithm that finetunes a pretrained LM to increase the conditional mutual information between constitutions and self-generated responses given queries from a datasest. On single-turn dialogue and summarization, a SAMI-trained mistral-7b outperforms the initial pretrained model, with win rates between 66% and 77%. Strikingly, it also surpasses an instruction-finetuned baseline (mistral-7b-instruct) with win rates between 55% and 57% on single-turn dialogue. SAMI requires a "principle writer" model; to avoid dependence on stronger models, we further evaluate aligning a strong pretrained model (mixtral-8x7b) using constitutions written by a weak instruction-finetuned model (mistral-7b-instruct). The SAMI-trained mixtral-8x7b outperforms both the initial model and the instruction-finetuned model, achieving a 65% win rate on summarization. Our results indicate that a pretrained LM can learn to follow constitutions without using preference labels, demonstrations, or human oversight.
Quiet-STaR: Language Models Can Teach Themselves to Think Before Speaking
Mar 18, 2024



When writing and talking, people sometimes pause to think. Although reasoning-focused works have often framed reasoning as a method of answering questions or completing agentic tasks, reasoning is implicit in almost all written text. For example, this applies to the steps not stated between the lines of a proof or to the theory of mind underlying a conversation. In the Self-Taught Reasoner (STaR, Zelikman et al. 2022), useful thinking is learned by inferring rationales from few-shot examples in question-answering and learning from those that lead to a correct answer. This is a highly constrained setting -- ideally, a language model could instead learn to infer unstated rationales in arbitrary text. We present Quiet-STaR, a generalization of STaR in which LMs learn to generate rationales at each token to explain future text, improving their predictions. We address key challenges, including 1) the computational cost of generating continuations, 2) the fact that the LM does not initially know how to generate or use internal thoughts, and 3) the need to predict beyond individual next tokens. To resolve these, we propose a tokenwise parallel sampling algorithm, using learnable tokens indicating a thought's start and end, and an extended teacher-forcing technique. Encouragingly, generated rationales disproportionately help model difficult-to-predict tokens and improve the LM's ability to directly answer difficult questions. In particular, after continued pretraining of an LM on a corpus of internet text with Quiet-STaR, we find zero-shot improvements on GSM8K (5.9%$\rightarrow$10.9%) and CommonsenseQA (36.3%$\rightarrow$47.2%) and observe a perplexity improvement of difficult tokens in natural text. Crucially, these improvements require no fine-tuning on these tasks. Quiet-STaR marks a step towards LMs that can learn to reason in a more general and scalable way.
Generating and Evaluating Tests for K-12 Students with Language Model Simulations: A Case Study on Sentence Reading Efficiency
Oct 10, 2023Developing an educational test can be expensive and time-consuming, as each item must be written by experts and then evaluated by collecting hundreds of student responses. Moreover, many tests require multiple distinct sets of questions administered throughout the school year to closely monitor students' progress, known as parallel tests. In this study, we focus on tests of silent sentence reading efficiency, used to assess students' reading ability over time. To generate high-quality parallel tests, we propose to fine-tune large language models (LLMs) to simulate how previous students would have responded to unseen items. With these simulated responses, we can estimate each item's difficulty and ambiguity. We first use GPT-4 to generate new test items following a list of expert-developed rules and then apply a fine-tuned LLM to filter the items based on criteria from psychological measurements. We also propose an optimal-transport-inspired technique for generating parallel tests and show the generated tests closely correspond to the original test's difficulty and reliability based on crowdworker responses. Our evaluation of a generated test with 234 students from grades 2 to 8 produces test scores highly correlated (r=0.93) to those of a standard test form written by human experts and evaluated across thousands of K-12 students.
Self-Taught Optimizer (STOP): Recursively Self-Improving Code Generation
Oct 03, 2023Several recent advances in AI systems (e.g., Tree-of-Thoughts and Program-Aided Language Models) solve problems by providing a "scaffolding" program that structures multiple calls to language models to generate better outputs. A scaffolding program is written in a programming language such as Python. In this work, we use a language-model-infused scaffolding program to improve itself. We start with a seed "improver" that improves an input program according to a given utility function by querying a language model several times and returning the best solution. We then run this seed improver to improve itself. Across a small set of downstream tasks, the resulting improved improver generates programs with significantly better performance than its seed improver. Afterward, we analyze the variety of self-improvement strategies proposed by the language model, including beam search, genetic algorithms, and simulated annealing. Since the language models themselves are not altered, this is not full recursive self-improvement. Nonetheless, it demonstrates that a modern language model, GPT-4 in our proof-of-concept experiments, is capable of writing code that can call itself to improve itself. We critically consider concerns around the development of self-improving technologies and evaluate the frequency with which the generated code bypasses a sandbox.
ContextRef: Evaluating Referenceless Metrics For Image Description Generation
Sep 21, 2023



Referenceless metrics (e.g., CLIPScore) use pretrained vision--language models to assess image descriptions directly without costly ground-truth reference texts. Such methods can facilitate rapid progress, but only if they truly align with human preference judgments. In this paper, we introduce ContextRef, a benchmark for assessing referenceless metrics for such alignment. ContextRef has two components: human ratings along a variety of established quality dimensions, and ten diverse robustness checks designed to uncover fundamental weaknesses. A crucial aspect of ContextRef is that images and descriptions are presented in context, reflecting prior work showing that context is important for description quality. Using ContextRef, we assess a variety of pretrained models, scoring functions, and techniques for incorporating context. None of the methods is successful with ContextRef, but we show that careful fine-tuning yields substantial improvements. ContextRef remains a challenging benchmark though, in large part due to the challenge of context dependence.
Hypothesis Search: Inductive Reasoning with Language Models
Sep 11, 2023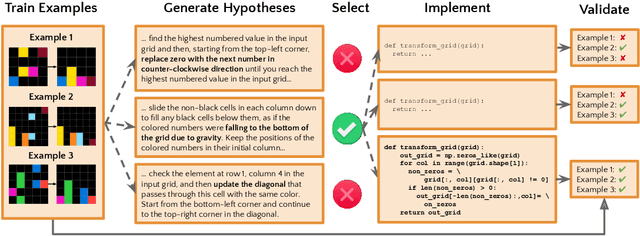

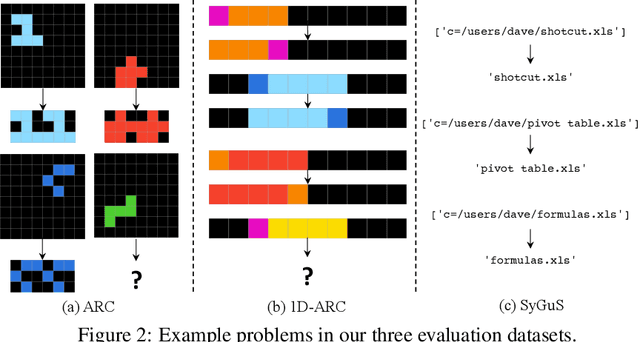
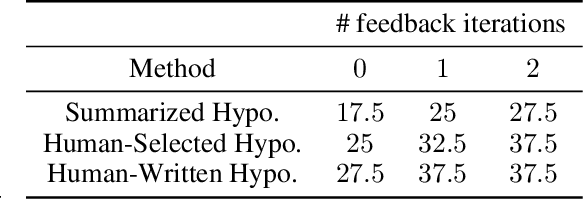
Inductive reasoning is a core problem-solving capacity: humans can identify underlying principles from a few examples, which can then be robustly generalized to novel scenarios. Recent work has evaluated large language models (LLMs) on inductive reasoning tasks by directly prompting them yielding "in context learning." This can work well for straightforward inductive tasks, but performs very poorly on more complex tasks such as the Abstraction and Reasoning Corpus (ARC). In this work, we propose to improve the inductive reasoning ability of LLMs by generating explicit hypotheses at multiple levels of abstraction: we prompt the LLM to propose multiple abstract hypotheses about the problem, in natural language, then implement the natural language hypotheses as concrete Python programs. These programs can be directly verified by running on the observed examples and generalized to novel inputs. Because of the prohibitive cost of generation with state-of-the-art LLMs, we consider a middle step to filter the set of hypotheses that will be implemented into programs: we either ask the LLM to summarize into a smaller set of hypotheses, or ask human annotators to select a subset of the hypotheses. We verify our pipeline's effectiveness on the ARC visual inductive reasoning benchmark, its variant 1D-ARC, and string transformation dataset SyGuS. On a random 40-problem subset of ARC, our automated pipeline using LLM summaries achieves 27.5% accuracy, significantly outperforming the direct prompting baseline (accuracy of 12.5%). With the minimal human input of selecting from LLM-generated candidates, the performance is boosted to 37.5%. (And we argue this is a lower bound on the performance of our approach without filtering.) Our ablation studies show that abstract hypothesis generation and concrete program representations are both beneficial for LLMs to perform inductive reasoning tasks.
SkyGPT: Probabilistic Short-term Solar Forecasting Using Synthetic Sky Videos from Physics-constrained VideoGPT
Jun 20, 2023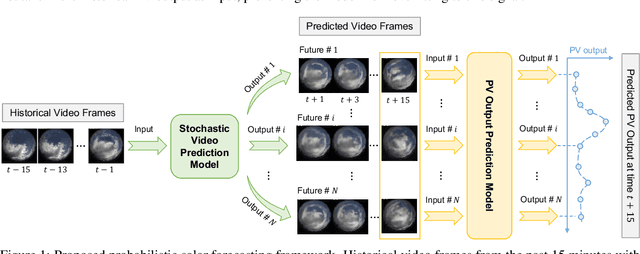
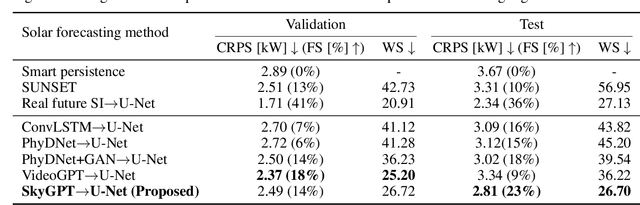
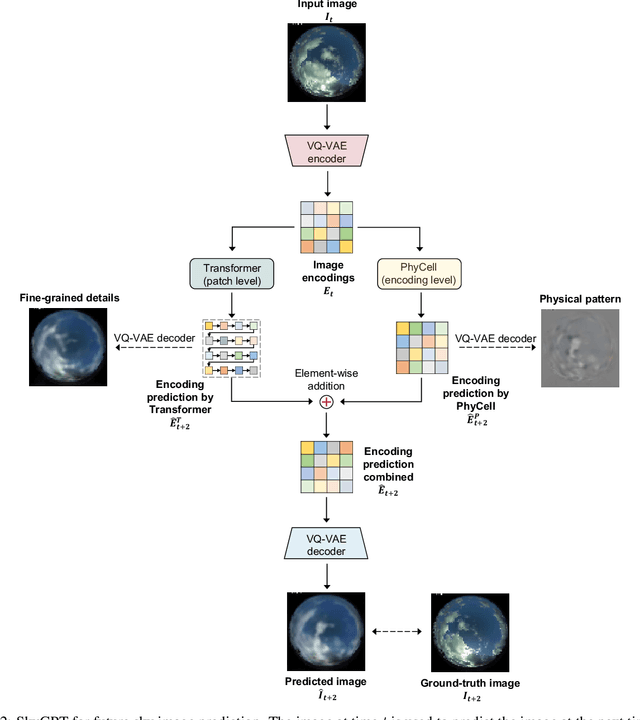
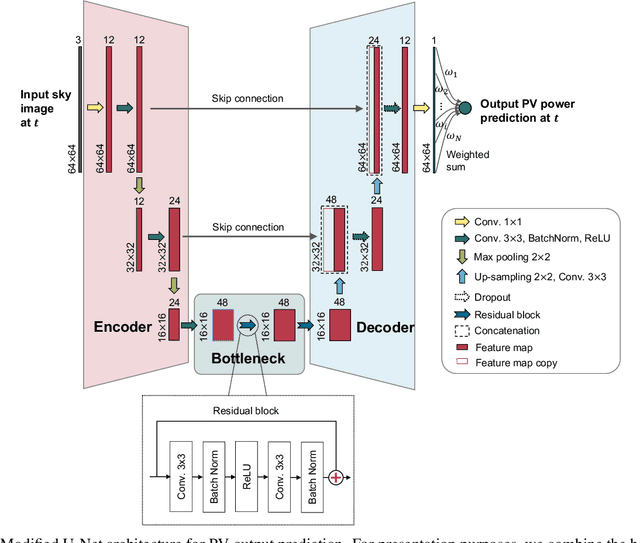
In recent years, deep learning-based solar forecasting using all-sky images has emerged as a promising approach for alleviating uncertainty in PV power generation. However, the stochastic nature of cloud movement remains a major challenge for accurate and reliable solar forecasting. With the recent advances in generative artificial intelligence, the synthesis of visually plausible yet diversified sky videos has potential for aiding in forecasts. In this study, we introduce \emph{SkyGPT}, a physics-informed stochastic video prediction model that is able to generate multiple possible future images of the sky with diverse cloud motion patterns, by using past sky image sequences as input. Extensive experiments and comparison with benchmark video prediction models demonstrate the effectiveness of the proposed model in capturing cloud dynamics and generating future sky images with high realism and diversity. Furthermore, we feed the generated future sky images from the video prediction models for 15-minute-ahead probabilistic solar forecasting for a 30-kW roof-top PV system, and compare it with an end-to-end deep learning baseline model SUNSET and a smart persistence model. Better PV output prediction reliability and sharpness is observed by using the predicted sky images generated with SkyGPT compared with other benchmark models, achieving a continuous ranked probability score (CRPS) of 2.81 (13\% better than SUNSET and 23\% better than smart persistence) and a Winkler score of 26.70 for the test set. Although an arbitrary number of futures can be generated from a historical sky image sequence, the results suggest that 10 future scenarios is a good choice that balances probabilistic solar forecasting performance and computational cost.
Just One Byte : A Note on Low-Bandwidth Decentralized Language Model Finetuning Using Shared Randomness
Jun 16, 2023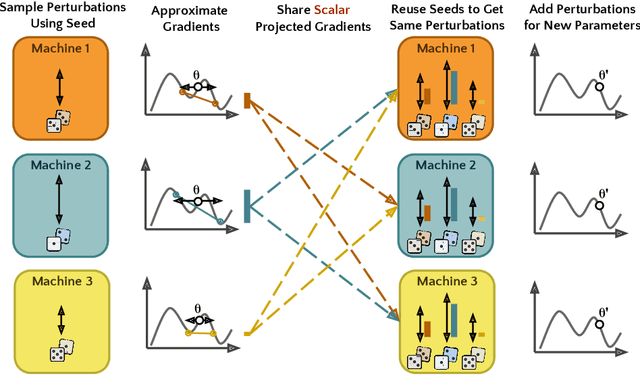
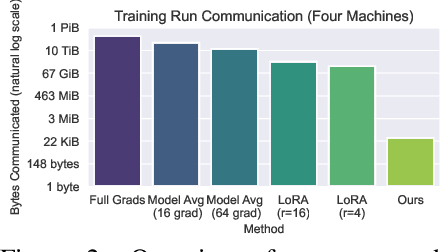
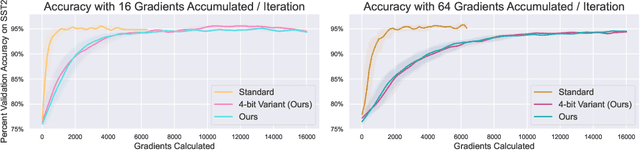
Language model training in distributed settings is limited by the communication cost of gradient exchanges. In this short note, we extend recent work from Malladi et al. (2023), using shared randomness to perform distributed fine-tuning with low bandwidth. The method is a natural decentralized extension of memory-efficient Simultaneous Perturbation Stochastic Approximation (SPSA). Each iteration, each machine seeds a Random Number Generator (RNG) to perform local reproducible perturbations on model weights and calculate and exchange scalar projected gradients, which are then used to update each model. By using a (machine, sample) identifier as the random seed, each model can regenerate one another's perturbations. As machines only exchange single-byte projected gradients, this is highly communication efficient. There are also potential privacy benefits, as projected gradients may be calculated on different training data, and models never access the other's data. Our approach not only drastically reduces communication bandwidth requirements but also accommodates dynamic addition or removal of machines during the training process and retains the memory-efficient and inference-only advantages of recent work. We perform proof-of-concept experiments to demonstrate the potential usefulness of this method, building off of rich literature on distributed optimization and memory-efficient training.
Certified Reasoning with Language Models
Jun 06, 2023Language models often achieve higher accuracy when reasoning step-by-step in complex tasks. However, their reasoning can be unsound, inconsistent, or rely on undesirable prior assumptions. To tackle these issues, we introduce a class of tools for language models called guides that use state and incremental constraints to guide generation. A guide can be invoked by the model to constrain its own generation to a set of valid statements given by the tool. In turn, the model's choices can change the guide's state. We show how a general system for logical reasoning can be used as a guide, which we call LogicGuide. Given a reasoning problem in natural language, a model can formalize its assumptions for LogicGuide and then guarantee that its reasoning steps are sound. In experiments with the PrOntoQA and ProofWriter reasoning datasets, LogicGuide significantly improves the performance of GPT-3, GPT-3.5 Turbo and LLaMA (accuracy gains up to 35%). LogicGuide also drastically reduces content effects: the interference of prior and current assumptions that both humans and language models have been shown to suffer from. Finally, we explore bootstrapping LLaMA 13B from its own reasoning and find that LogicGuide is critical: by training only on certified self-generated reasoning, LLaMA can self-improve, avoiding learning from its own hallucinations.
Lexinvariant Language Models
May 24, 2023



Token embeddings, a mapping from discrete lexical symbols to continuous vectors, are at the heart of any language model (LM). However, lexical symbol meanings can also be determined and even redefined by their structural role in a long context. In this paper, we ask: is it possible for a language model to be performant without \emph{any} fixed token embeddings? Such a language model would have to rely entirely on the co-occurence and repetition of tokens in the context rather than the \textit{a priori} identity of any token. To answer this, we study \textit{lexinvariant}language models that are invariant to lexical symbols and therefore do not need fixed token embeddings in practice. First, we prove that we can construct a lexinvariant LM to converge to the true language model at a uniform rate that is polynomial in terms of the context length, with a constant factor that is sublinear in the vocabulary size. Second, to build a lexinvariant LM, we simply encode tokens using random Gaussian vectors, such that each token maps to the same representation within each sequence but different representations across sequences. Empirically, we demonstrate that it can indeed attain perplexity comparable to that of a standard language model, given a sufficiently long context. We further explore two properties of the lexinvariant language models: First, given text generated from a substitution cipher of English, it implicitly implements Bayesian in-context deciphering and infers the mapping to the underlying real tokens with high accuracy. Second, it has on average 4X better accuracy over synthetic in-context reasoning tasks. Finally, we discuss regularizing standard language models towards lexinvariance and potential practical applications.