 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Ball: Composing Policies for Long-Horizon Basketball Moves
Sep 26, 2025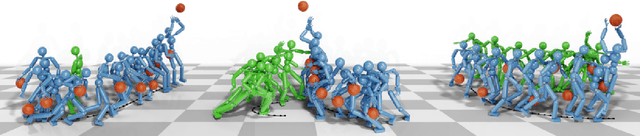

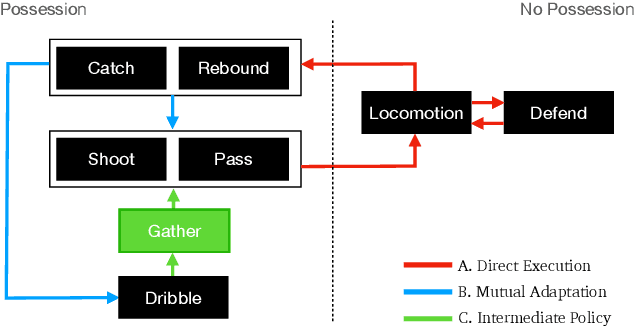

Learning a control policy for a multi-phase, long-horizon task, such as basketball maneuvers, remains challenging for reinforcement learning approaches due to the need for seamless policy composition and transitions between skills. A long-horizon task typically consists of distinct subtasks with well-defined goals, separated by transitional subtasks with unclear goals but critical to the success of the entire task. Existing methods like the mixture of experts and skill chaining struggle with tasks where individual policies do not share significant commonly explored states or lack well-defined initial and terminal states between different phases. In this paper, we introduce a novel policy integration framework to enable the composition of drastically different motor skills in multi-phase long-horizon tasks with ill-defined intermediate states. Based on that, we further introduce a high-level soft router to enable seamless and robust transitions between the subtasks. We evaluate our framework on a set of fundamental basketball skills and challenging transitions. Policies trained by our approach can effectively control the simulated character to interact with the ball and accomplish the long-horizon task specified by real-time user commands, without relying on ball trajectory references.
* ACM Transactions on Graphics (Proceedings of SIGGRAPH Asia 2025). Website: http://pei-xu.github.io/basketball. Video: https://youtu.be/2RBFIjjmR2I. Code: https://github.com/xupei0610/basketball
FürElise: Capturing and Physically Synthesizing Hand Motions of Piano Performance
Oct 08, 2024Piano playing requires agile, precise, and coordinated hand control that stretches the limits of dexterity. Hand motion models with the sophistication to accurately recreate piano playing have a wide range of applications in character animation, embodied AI, biomechanics, and VR/AR. In this paper, we construct a first-of-its-kind large-scale dataset that contains approximately 10 hours of 3D hand motion and audio from 15 elite-level pianists playing 153 pieces of classical music. To capture natural performances, we designed a markerless setup in which motions are reconstructed from multi-view videos using state-of-the-art pose estimation models. The motion data is further refined via inverse kinematics using the high-resolution MIDI key-pressing data obtained from sensors in a specialized Yamaha Disklavier piano. Leveraging the collected dataset, we developed a pipeline that can synthesize physically-plausible hand motions for musical scores outside of the dataset. Our approach employs a combination of imitation learning and reinforcement learning to obtain policies for physics-based bimanual control involving the interaction between hands and piano keys. To solve the sampling efficiency problem with the large motion dataset, we use a diffusion model to generate natural reference motions, which provide high-level trajectory and fingering (finger order and placement) information. However, the generated reference motion alone does not provide sufficient accuracy for piano performance modeling. We then further augmented the data by using musical similarity to retrieve similar motions from the captured dataset to boost the precision of the RL policy. With the proposed method, our model generates natural, dexterous motions that generalize to music from outside the training dataset.
One-Shot Transfer of Long-Horizon Extrinsic Manipulation Through Contact Retargeting
Apr 11, 2024Extrinsic manipulation, the use of environment contacts to achieve manipulation objectives, enables strategies that are otherwise impossible with a parallel jaw gripper. However, orchestrating a long-horizon sequence of contact interactions between the robot, object, and environment is notoriously challenging due to the scene diversity, large action space, and difficult contact dynamics. We observe that most extrinsic manipulation are combinations of short-horizon primitives, each of which depend strongly on initializing from a desirable contact configuration to succeed. Therefore, we propose to generalize one extrinsic manipulation trajectory to diverse objects and environments by retargeting contact requirements. We prepare a single library of robust short-horizon, goal-conditioned primitive policies, and design a framework to compose state constraints stemming from contacts specifications of each primitive. Given a test scene and a single demo prescribing the primitive sequence, our method enforces the state constraints on the test scene and find intermediate goal states using inverse kinematics. The goals are then tracked by the primitive policies. Using a 7+1 DoF robotic arm-gripper system, we achieved an overall success rate of 80.5% on hardware over 4 long-horizon extrinsic manipulation tasks, each with up to 4 primitives. Our experiments cover 10 objects and 6 environment configurations. We further show empirically that our method admits a wide range of demonstrations, and that contact retargeting is indeed the key to successfully combining primitives for long-horizon extrinsic manipulation. Code and additional details are available at stanford-tml.github.io/extrinsic-manipulation.
Hypothesis Search: Inductive Reasoning with Language Models
Sep 11, 2023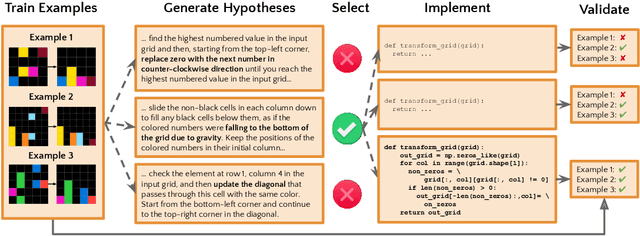

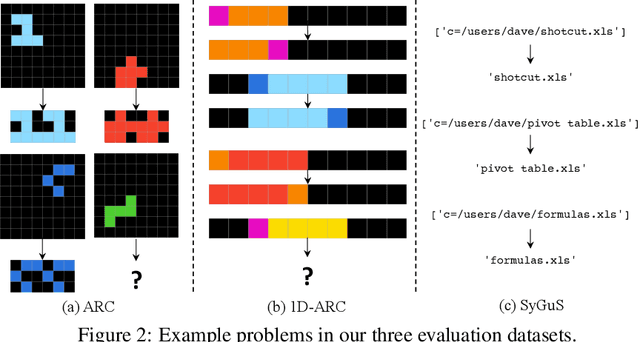
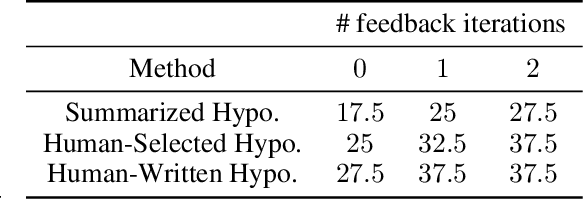
Inductive reasoning is a core problem-solving capacity: humans can identify underlying principles from a few examples, which can then be robustly generalized to novel scenarios. Recent work has evaluated large language models (LLMs) on inductive reasoning tasks by directly prompting them yielding "in context learning." This can work well for straightforward inductive tasks, but performs very poorly on more complex tasks such as the Abstraction and Reasoning Corpus (ARC). In this work, we propose to improve the inductive reasoning ability of LLMs by generating explicit hypotheses at multiple levels of abstraction: we prompt the LLM to propose multiple abstract hypotheses about the problem, in natural language, then implement the natural language hypotheses as concrete Python programs. These programs can be directly verified by running on the observed examples and generalized to novel inputs. Because of the prohibitive cost of generation with state-of-the-art LLMs, we consider a middle step to filter the set of hypotheses that will be implemented into programs: we either ask the LLM to summarize into a smaller set of hypotheses, or ask human annotators to select a subset of the hypotheses. We verify our pipeline's effectiveness on the ARC visual inductive reasoning benchmark, its variant 1D-ARC, and string transformation dataset SyGuS. On a random 40-problem subset of ARC, our automated pipeline using LLM summaries achieves 27.5% accuracy, significantly outperforming the direct prompting baseline (accuracy of 12.5%). With the minimal human input of selecting from LLM-generated candidates, the performance is boosted to 37.5%. (And we argue this is a lower bound on the performance of our approach without filtering.) Our ablation studies show that abstract hypothesis generation and concrete program representations are both beneficial for LLMs to perform inductive reasoning tasks.
IKEA-Manual: Seeing Shape Assembly Step by Step
Feb 03, 2023



Human-designed visual manuals are crucial components in shape assembly activities. They provide step-by-step guidance on how we should move and connect different parts in a convenient and physically-realizable way. While there has been an ongoing effort in building agents that perform assembly tasks, the information in human-design manuals has been largely overlooked. We identify that this is due to 1) a lack of realistic 3D assembly objects that have paired manuals and 2) the difficulty of extracting structured information from purely image-based manuals. Motivated by this observation, we present IKEA-Manual, a dataset consisting of 102 IKEA objects paired with assembly manuals. We provide fine-grained annotations on the IKEA objects and assembly manuals, including decomposed assembly parts, assembly plans, manual segmentation, and 2D-3D correspondence between 3D parts and visual manuals. We illustrate the broad application of our dataset on four tasks related to shape assembly: assembly plan generation, part segmentation, pose estimation, and 3D part assembly.
Translating a Visual LEGO Manual to a Machine-Executable Plan
Jul 25, 2022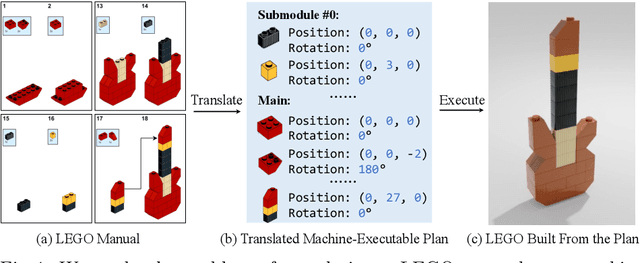
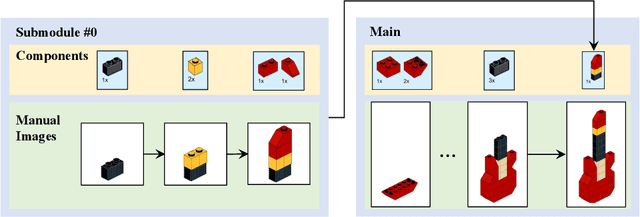
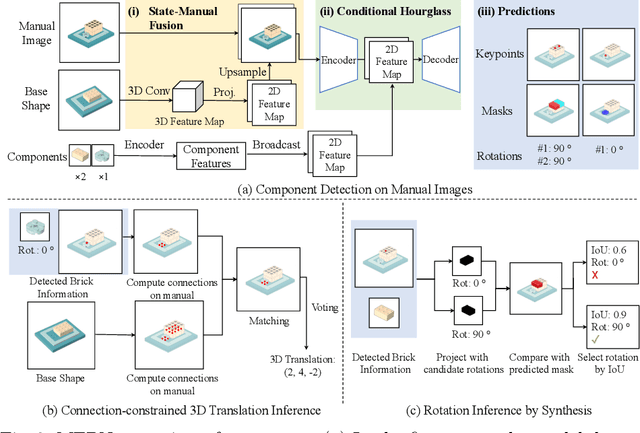
We study the problem of translating an image-based, step-by-step assembly manual created by human designers into machine-interpretable instructions. We formulate this problem as a sequential prediction task: at each step, our model reads the manual, locates the components to be added to the current shape, and infers their 3D poses. This task poses the challenge of establishing a 2D-3D correspondence between the manual image and the real 3D object, and 3D pose estimation for unseen 3D objects, since a new component to be added in a step can be an object built from previous steps. To address these two challenges, we present a novel learning-based framework, the Manual-to-Executable-Plan Network (MEPNet), which reconstructs the assembly steps from a sequence of manual images. The key idea is to integrate neural 2D keypoint detection modules and 2D-3D projection algorithms for high-precision prediction and strong generalization to unseen components. The MEPNet outperforms existing methods on three newly collected LEGO manual datasets and a Minecraft house dataset.
Language-Mediated, Object-Centric Representation Learning
Dec 31, 2020


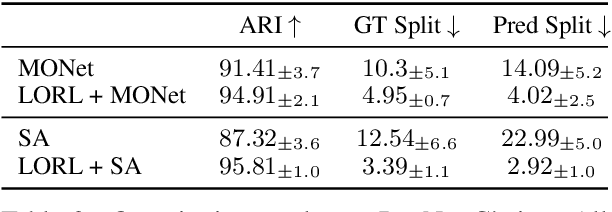
We present Language-mediated, Object-centric Representation Learning (LORL), a paradigm for learning disentangled, object-centric scene representations from vision and language. LORL builds upon recent advances in unsupervised object segmentation, notably MONet and Slot Attention. While these algorithms learn an object-centric representation just by reconstructing the input image, LORL enables them to further learn to associate the learned representations to concepts, i.e., words for object categories, properties, and spatial relationships, from language input. These object-centric concepts derived from language facilitate the learning of object-centric representations. LORL can be integrated with various unsupervised segmentation algorithms that are language-agnostic. Experiments show that the integration of LORL consistently improves the object segmentation performance of MONet and Slot Attention on two datasets via the help of language. We also show that concepts learned by LORL, in conjunction with segmentation algorithms such as MONet, aid downstream tasks such as referring expression comprehension.
On the Relative Expressiveness of Bayesian and Neural Networks
Dec 21, 2018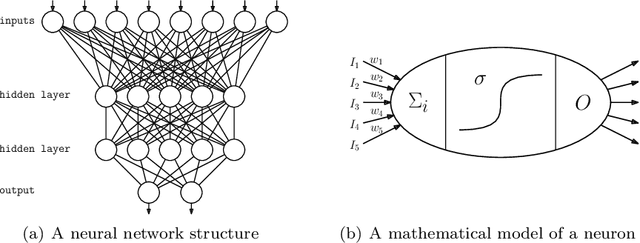
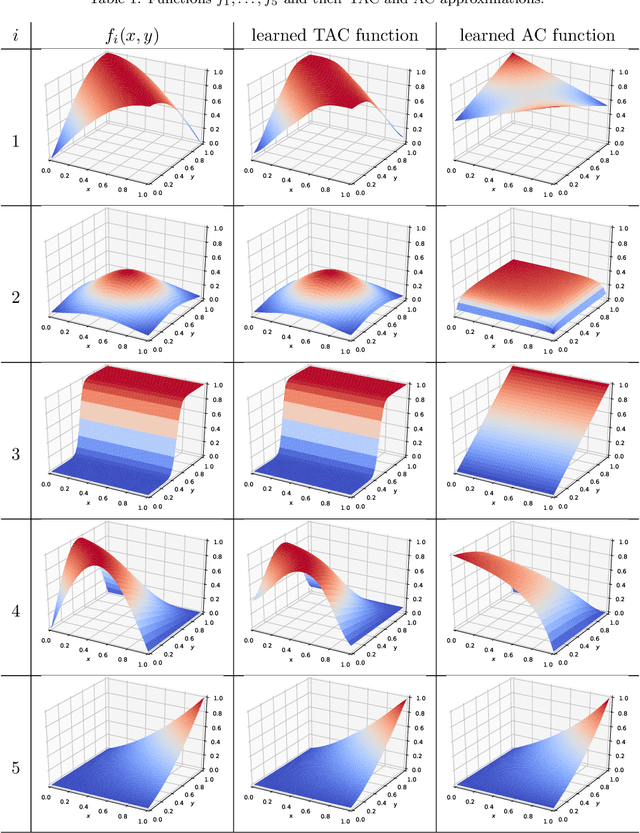
A neural network computes a function. A central property of neural networks is that they are "universal approximators:" for a given continuous function, there exists a neural network that can approximate it arbitrarily well, given enough neurons (and some additional assumptions). In contrast, a Bayesian network is a model, but each of its queries can be viewed as computing a function. In this paper, we identify some key distinctions between the functions computed by neural networks and those by marginal Bayesian network queries, showing that the former are more expressive than the latter. Moreover, we propose a simple augmentation to Bayesian networks (a testing operator), which enables their marginal queries to become "universal approximators."