 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraspGen: A Diffusion-based Framework for 6-DOF Grasping with On-Generator Training
Jul 17, 2025Grasping is a fundamental robot skill, yet despite significant research advancements, learning-based 6-DOF grasping approaches are still not turnkey and struggle to generalize across different embodiments and in-the-wild settings. We build upon the recent success on modeling the object-centric grasp generation process as an iterative diffusion process. Our proposed framework, GraspGen, consists of a DiffusionTransformer architecture that enhances grasp generation, paired with an efficient discriminator to score and filter sampled grasps. We introduce a novel and performant on-generator training recipe for the discriminator. To scale GraspGen to both objects and grippers, we release a new simulated dataset consisting of over 53 million grasps. We demonstrate that GraspGen outperforms prior methods in simulations with singulated objects across different grippers, achieves state-of-the-art performance on the FetchBench grasping benchmark, and performs well on a real robot with noisy visual observations.
3D-Generalist: Self-Improving Vision-Language-Action Models for Crafting 3D Worlds
Jul 09, 2025Despite large-scale pretraining endowing models with language and vision reasoning capabilities, improving their spatial reasoning capability remains challenging due to the lack of data grounded in the 3D world. While it is possible for humans to manually create immersive and interactive worlds through 3D graphics, as seen in applications such as VR, gaming, and robotics, this process remains highly labor-intensive. In this paper, we propose a scalable method for generating high-quality 3D environments that can serve as training data for foundation models. We recast 3D environment building as a sequential decision-making problem, employing Vision-Language-Models (VLMs) as policies that output actions to jointly craft a 3D environment's layout, materials, lighting, and assets. Our proposed framework, 3D-Generalist, trains VLMs to generate more prompt-aligned 3D environments via self-improvement fine-tuning. We demonstrate the effectiveness of 3D-Generalist and the proposed training strategy in generating simulation-ready 3D environments. Furthermore, we demonstrate its quality and scalability in synthetic data generation by pretraining a vision foundation model on the generated data. After fine-tuning the pre-trained model on downstream tasks, we show that it surpasses models pre-trained on meticulously human-crafted synthetic data and approaches results achieved with real data orders of magnitude larger.
One-Shot Transfer of Long-Horizon Extrinsic Manipulation Through Contact Retargeting
Apr 11, 2024



Extrinsic manipulation, the use of environment contacts to achieve manipulation objectives, enables strategies that are otherwise impossible with a parallel jaw gripper. However, orchestrating a long-horizon sequence of contact interactions between the robot, object, and environment is notoriously challenging due to the scene diversity, large action space, and difficult contact dynamics. We observe that most extrinsic manipulation are combinations of short-horizon primitives, each of which depend strongly on initializing from a desirable contact configuration to succeed. Therefore, we propose to generalize one extrinsic manipulation trajectory to diverse objects and environments by retargeting contact requirements. We prepare a single library of robust short-horizon, goal-conditioned primitive policies, and design a framework to compose state constraints stemming from contacts specifications of each primitive. Given a test scene and a single demo prescribing the primitive sequence, our method enforces the state constraints on the test scene and find intermediate goal states using inverse kinematics. The goals are then tracked by the primitive policies. Using a 7+1 DoF robotic arm-gripper system, we achieved an overall success rate of 80.5% on hardware over 4 long-horizon extrinsic manipulation tasks, each with up to 4 primitives. Our experiments cover 10 objects and 6 environment configurations. We further show empirically that our method admits a wide range of demonstrations, and that contact retargeting is indeed the key to successfully combining primitives for long-horizon extrinsic manipulation. Code and additional details are available at stanford-tml.github.io/extrinsic-manipulation.
DiMSam: Diffusion Models as Samplers for Task and Motion Planning under Partial Observability
Jun 22, 2023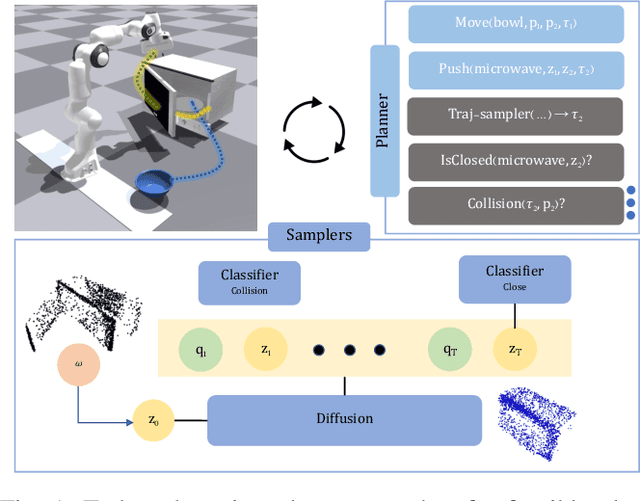

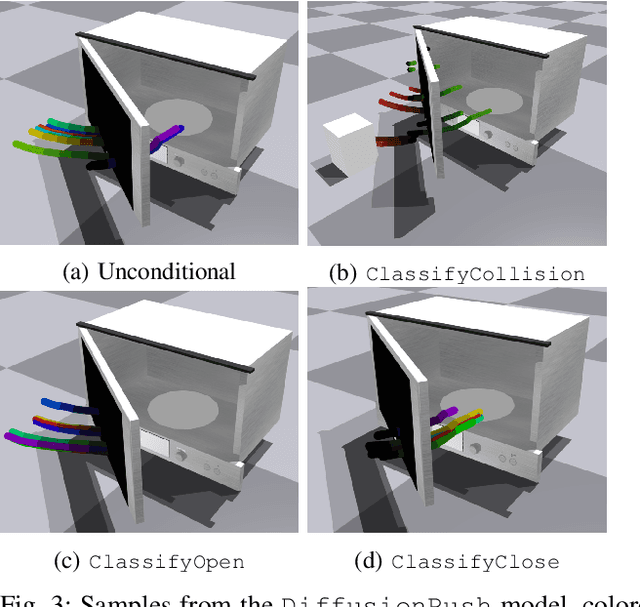

Task and Motion Planning (TAMP) approaches are effective at planning long-horizon autonomous robot manipulation. However, because they require a planning model, it can be difficult to apply them to domains where the environment and its dynamics are not fully known. We propose to overcome these limitations by leveraging deep generative modeling, specifically diffusion models, to learn constraints and samplers that capture these difficult-to-engineer aspects of the planning model. These learned samplers are composed and combined within a TAMP solver in order to find action parameter values jointly that satisfy the constraints along a plan. To tractably make predictions for unseen objects in the environment, we define these samplers on low-dimensional learned latent embeddings of changing object state. We evaluate our approach in an articulated object manipulation domain and show how the combination of classical TAMP, generative learning, and latent embeddings enables long-horizon constraint-based reasoning.
CabiNet: Scaling Neural Collision Detection for Object Rearrangement with Procedural Scene Generation
Apr 18, 2023
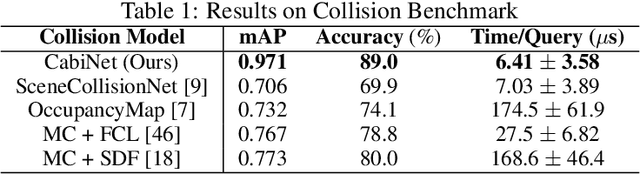
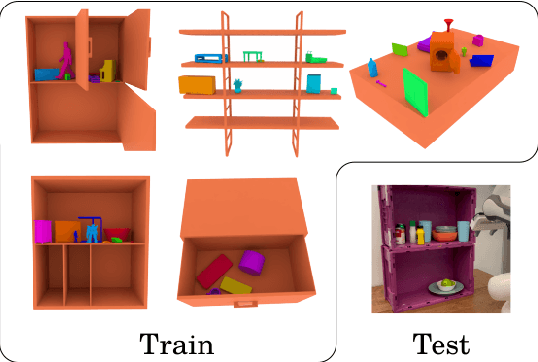
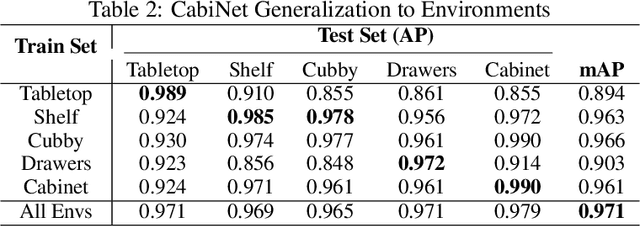
We address the important problem of generalizing robotic rearrangement to clutter without any explicit object models. We first generate over 650K cluttered scenes - orders of magnitude more than prior work - in diverse everyday environments, such as cabinets and shelves. We render synthetic partial point clouds from this data and use it to train our CabiNet model architecture. CabiNet is a collision model that accepts object and scene point clouds, captured from a single-view depth observation, and predicts collisions for SE(3) object poses in the scene. Our representation has a fast inference speed of 7 microseconds per query with nearly 20% higher performance than baseline approaches in challenging environments. We use this collision model in conjunction with a Model Predictive Path Integral (MPPI) planner to generate collision-free trajectories for picking and placing in clutter. CabiNet also predicts waypoints, computed from the scene's signed distance field (SDF), that allows the robot to navigate tight spaces during rearrangement. This improves rearrangement performance by nearly 35% compared to baselines. We systematically evaluate our approach, procedurally generate simulated experiments, and demonstrate that our approach directly transfers to the real world, despite training exclusively in simulation. Robot experiment demos in completely unknown scenes and objects can be found at this http https://cabinet-object-rearrangement.github.io
Deep Learning Approaches to Grasp Synthesis: A Review
Jul 06, 2022


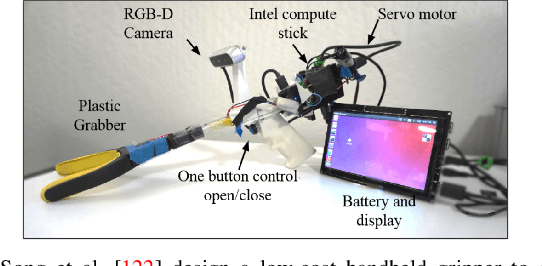
Grasping is the process of picking an object by applying forces and torques at a set of contacts. Recent advances in deep-learning methods have allowed rapid progress in robotic object grasping. We systematically surveyed the publications over the last decade, with a particular interest in grasping an object using all 6 degrees of freedom of the end-effector pose. Our review found four common methodologies for robotic grasping: sampling-based approaches, direct regression, reinforcement learning, and exemplar approaches. Furthermore, we found two 'supporting methods' around grasping that use deep-learning to support the grasping process, shape approximation, and affordances. We have distilled the publications found in this systematic review (85 papers) into ten key takeaways we consider crucial for future robotic grasping and manipulation research. An online version of the survey is available at https://rhys-newbury.github.io/projects/6dof/
DefGraspSim: Physics-based simulation of grasp outcomes for 3D deformable objects
Mar 21, 2022
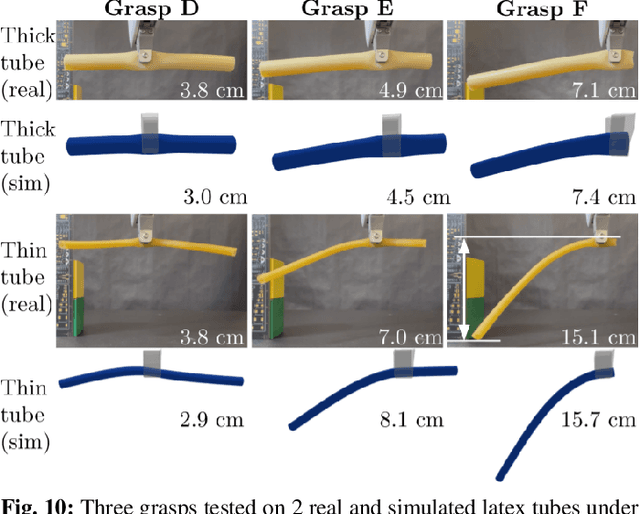


Robotic grasping of 3D deformable objects (e.g., fruits/vegetables, internal organs, bottles/boxes) is critical for real-world applications such as food processing, robotic surgery, and household automation. However, developing grasp strategies for such objects is uniquely challenging. Unlike rigid objects, deformable objects have infinite degrees of freedom and require field quantities (e.g., deformation, stress) to fully define their state. As these quantities are not easily accessible in the real world, we propose studying interaction with deformable objects through physics-based simulation. As such, we simulate grasps on a wide range of 3D deformable objects using a GPU-based implementation of the corotational finite element method (FEM). To facilitate future research, we open-source our simulated dataset (34 objects, 1e5 Pa elasticity range, 6800 grasp evaluations, 1.1M grasp measurements), as well as a code repository that allows researchers to run our full FEM-based grasp evaluation pipeline on arbitrary 3D object models of their choice. Finally, we demonstrate good correspondence between grasp outcomes on simulated objects and their real counterparts.
DefGraspSim: Simulation-based grasping of 3D deformable objects
Jul 12, 2021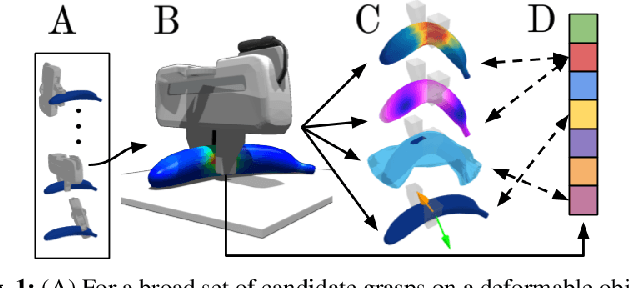
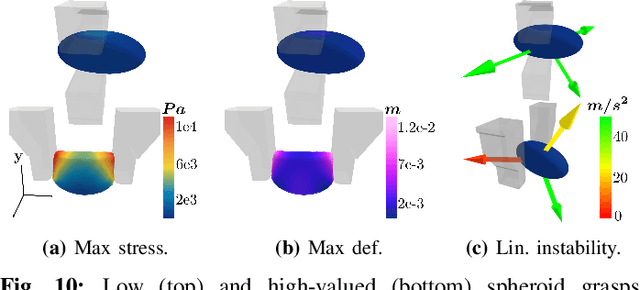

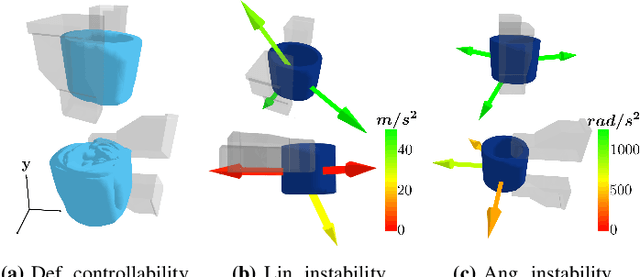
Robotic grasping of 3D deformable objects (e.g., fruits/vegetables, internal organs, bottles/boxes) is critical for real-world applications such as food processing, robotic surgery, and household automation. However, developing grasp strategies for such objects is uniquely challenging. In this work, we efficiently simulate grasps on a wide range of 3D deformable objects using a GPU-based implementation of the corotational finite element method (FEM). To facilitate future research, we open-source our simulated dataset (34 objects, 1e5 Pa elasticity range, 6800 grasp evaluations, 1.1M grasp measurements), as well as a code repository that allows researchers to run our full FEM-based grasp evaluation pipeline on arbitrary 3D object models of their choice. We also provide a detailed analysis on 6 object primitives. For each primitive, we methodically describe the effects of different grasp strategies, compute a set of performance metrics (e.g., deformation, stress) that fully capture the object response, and identify simple grasp features (e.g., gripper displacement, contact area) measurable by robots prior to pickup and predictive of these performance metrics. Finally, we demonstrate good correspondence between grasps on simulated objects and their real-world counterparts.
Alternative Paths Planner (APP) for Provably Fixed-time Manipulation Planning in Semi-structured Environments
Dec 29, 2020
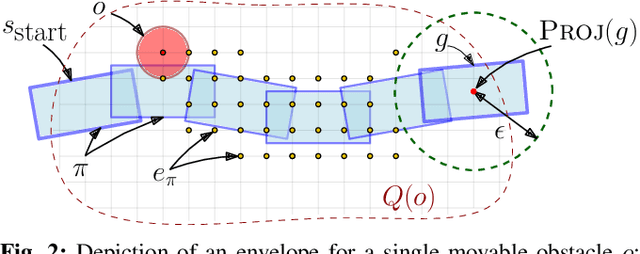
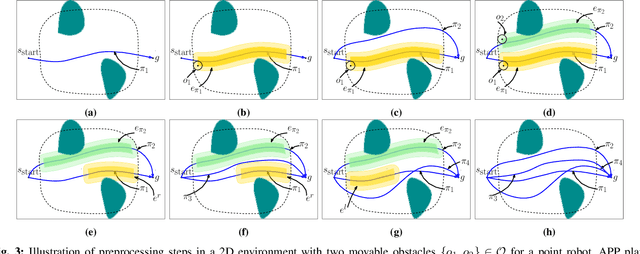
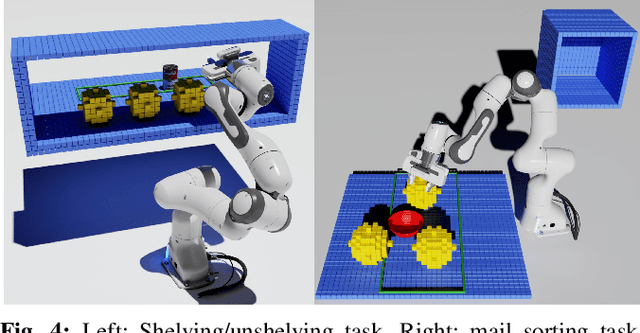
In many applications, including logistics and manufacturing, robot manipulators operate in semi-structured environments alongside humans or other robots. These environments are largely static, but they may contain some movable obstacles that the robot must avoid. Manipulation tasks in these applications are often highly repetitive, but require fast and reliable motion planning capabilities, often under strict time constraints. Existing preprocessing-based approaches are beneficial when the environments are highly-structured, but their performance degrades in the presence of movable obstacles, since these are not modelled a priori. We propose a novel preprocessing-based method called Alternative Paths Planner (APP) that provides provably fixed-time planning guarantees in semi-structured environments. APP plans a set of alternative paths offline such that, for any configuration of the movable obstacles, at least one of the paths from this set is collision-free. During online execution, a collision-free path can be looked up efficiently within a few microseconds. We evaluate APP on a 7 DoF robot arm in semi-structured domains of varying complexity and demonstrate that APP is several orders of magnitude faster than state-of-the-art motion planners for each domain. We further validate this approach with real-time experiments on a robotic manipulator.
Object Rearrangement Using Learned Implicit Collision Functions
Nov 21, 2020
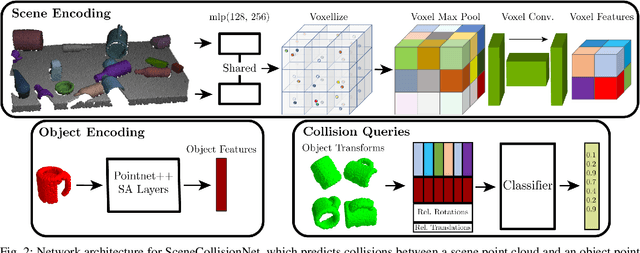
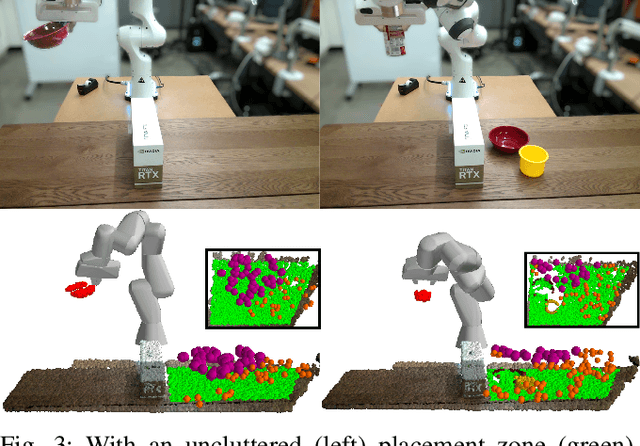
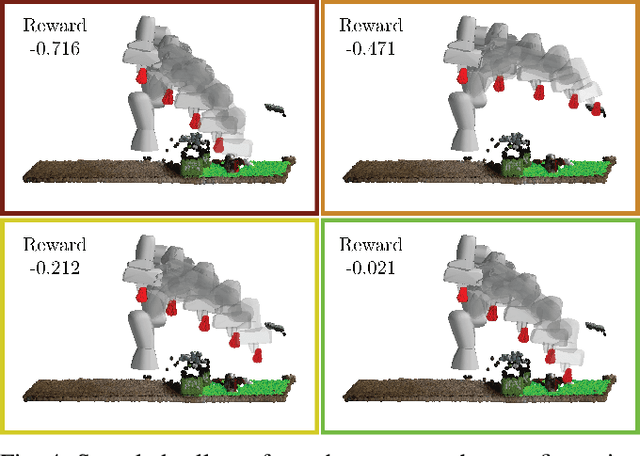
Robotic object rearrangement combines the skills of picking and placing objects. When object models are unavailable, typical collision-checking models may be unable to predict collisions in partial point clouds with occlusions, making generation of collision-free grasping or placement trajectories challenging. We propose a learned collision model that accepts scene and query object point clouds and predicts collisions for 6DOF object poses within the scene. We train the model on a synthetic set of 1 million scene/object point cloud pairs and 2 billion collision queries. We leverage the learned collision model as part of a model predictive path integral (MPPI) policy in a tabletop rearrangement task and show that the policy can plan collision-free grasps and placements for objects unseen in training in both simulated and physical cluttered scenes with a Franka Panda robot. The learned model outperforms both traditional pipelines and learned ablations by 9.8% in accuracy on a dataset of simulated collision queries and is 75x faster than the best-performing baseline. Videos and supplementary material are available at https://sites.google.com/nvidia.com/scenecollisionnet.