 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCascaded Diffusion Models for Neural Motion Planning
May 21, 2025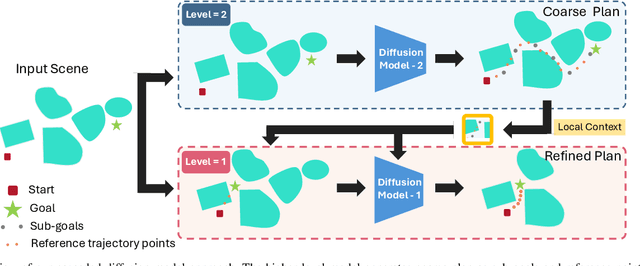

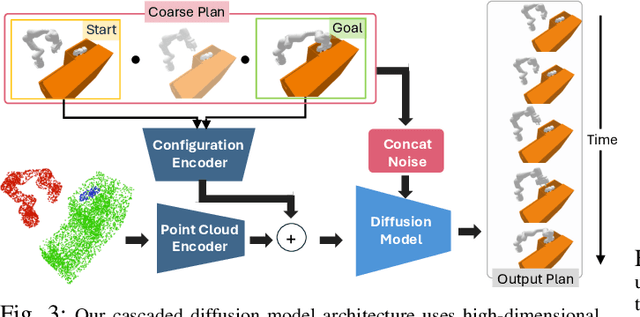
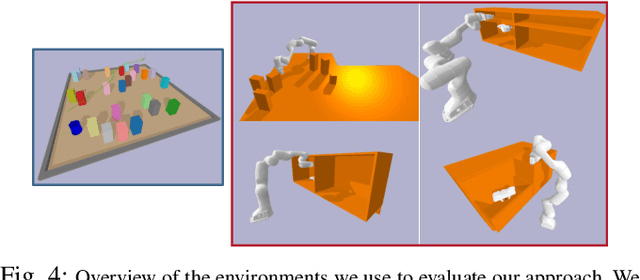
Robots in the real world need to perceive and move to goals in complex environments without collisions. Avoiding collisions is especially difficult when relying on sensor perception and when goals are among clutter. Diffusion policies and other generative models have shown strong performance in solving local planning problems, but often struggle at avoiding all of the subtle constraint violations that characterize truly challenging global motion planning problems. In this work, we propose an approach for learning global motion planning using diffusion policies, allowing the robot to generate full trajectories through complex scenes and reasoning about multiple obstacles along the path. Our approach uses cascaded hierarchical models which unify global prediction and local refinement together with online plan repair to ensure the trajectories are collision free. Our method outperforms (by ~5%) a wide variety of baselines on challenging tasks in multiple domains including navigation and manipulation.
Learning to Build by Building Your Own Instructions
Oct 01, 2024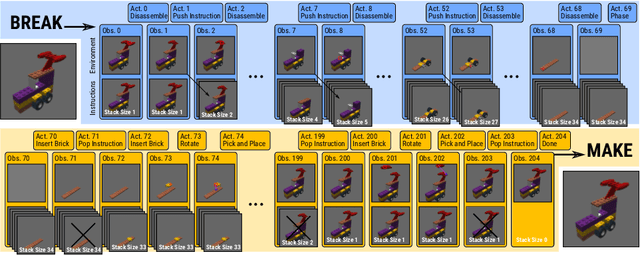
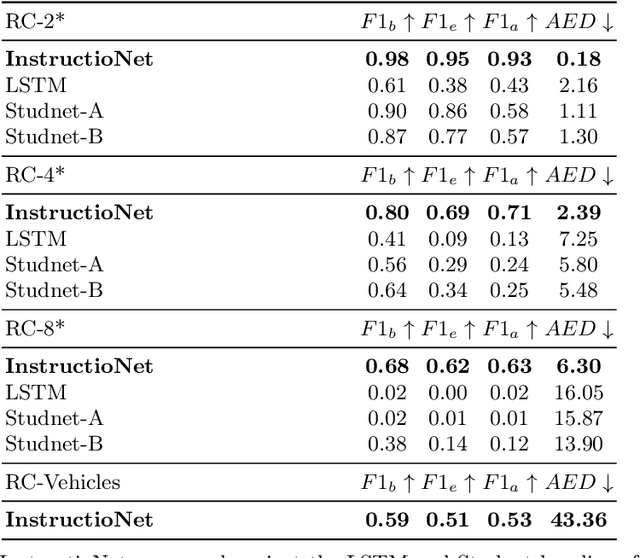

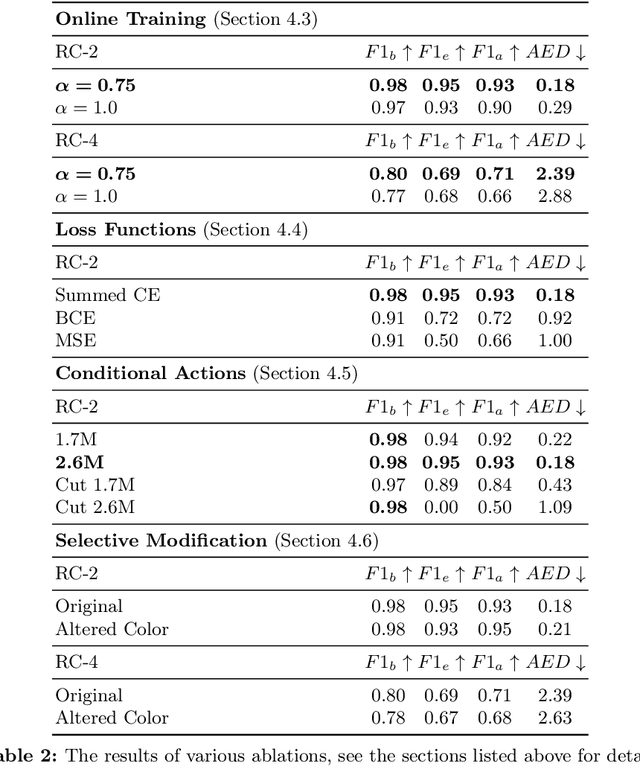
Structural understanding of complex visual objects is an important unsolved component of artificial intelligence. To study this, we develop a new technique for the recently proposed Break-and-Make problem in LTRON where an agent must learn to build a previously unseen LEGO assembly using a single interactive session to gather information about its components and their structure. We attack this problem by building an agent that we call \textbf{\ours} that is able to make its own visual instruction book. By disassembling an unseen assembly and periodically saving images of it, the agent is able to create a set of instructions so that it has the information necessary to rebuild it. These instructions form an explicit memory that allows the model to reason about the assembly process one step at a time, avoiding the need for long-term implicit memory. This in turn allows us to train on much larger LEGO assemblies than has been possible in the past. To demonstrate the power of this model, we release a new dataset of procedurally built LEGO vehicles that contain an average of 31 bricks each and require over one hundred steps to disassemble and reassemble. We train these models using online imitation learning which allows the model to learn from its own mistakes. Finally, we also provide some small improvements to LTRON and the Break-and-Make problem that simplify the learning environment and improve usability.
This&That: Language-Gesture Controlled Video Generation for Robot Planning
Jul 08, 2024We propose a robot learning method for communicating, planning, and executing a wide range of tasks, dubbed This&That. We achieve robot planning for general tasks by leveraging the power of video generative models trained on internet-scale data containing rich physical and semantic context. In this work, we tackle three fundamental challenges in video-based planning: 1) unambiguous task communication with simple human instructions, 2) controllable video generation that respects user intents, and 3) translating visual planning into robot actions. We propose language-gesture conditioning to generate videos, which is both simpler and clearer than existing language-only methods, especially in complex and uncertain environments. We then suggest a behavioral cloning design that seamlessly incorporates the video plans. This&That demonstrates state-of-the-art effectiveness in addressing the above three challenges, and justifies the use of video generation as an intermediate representation for generalizable task planning and execution. Project website: https://cfeng16.github.io/this-and-that/.
cuRobo: Parallelized Collision-Free Minimum-Jerk Robot Motion Generation
Nov 03, 2023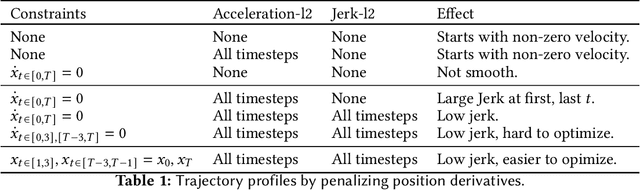
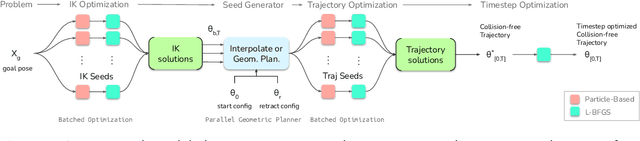
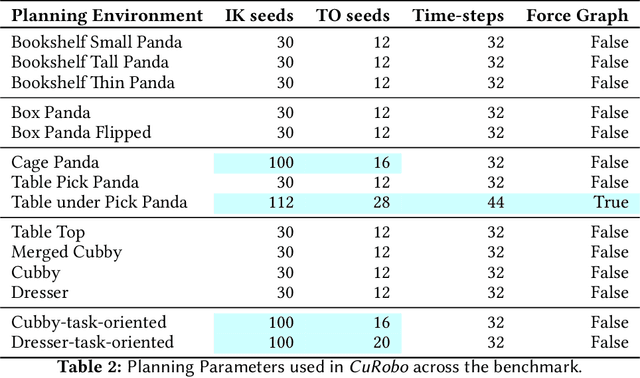
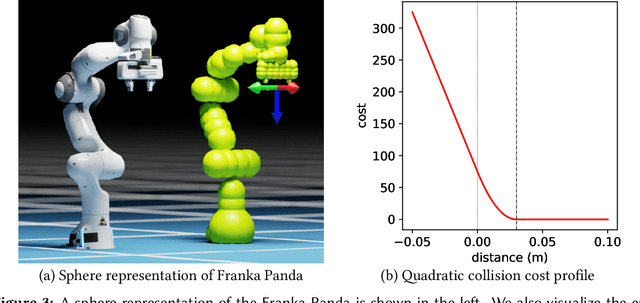
This paper explores the problem of collision-free motion generation for manipulators by formulating it as a global motion optimization problem. We develop a parallel optimization technique to solve this problem and demonstrate its effectiveness on massively parallel GPUs. We show that combining simple optimization techniques with many parallel seeds leads to solving difficult motion generation problems within 50ms on average, 60x faster than state-of-the-art (SOTA) trajectory optimization methods. We achieve SOTA performance by combining L-BFGS step direction estimation with a novel parallel noisy line search scheme and a particle-based optimization solver. To further aid trajectory optimization, we develop a parallel geometric planner that plans within 20ms and also introduce a collision-free IK solver that can solve over 7000 queries/s. We package our contributions into a state of the art GPU accelerated motion generation library, cuRobo and release it to enrich the robotics community. Additional details are available at https://curobo.org
CabiNet: Scaling Neural Collision Detection for Object Rearrangement with Procedural Scene Generation
Apr 18, 2023
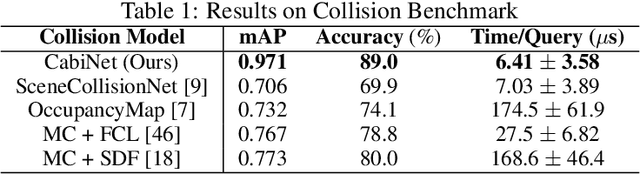
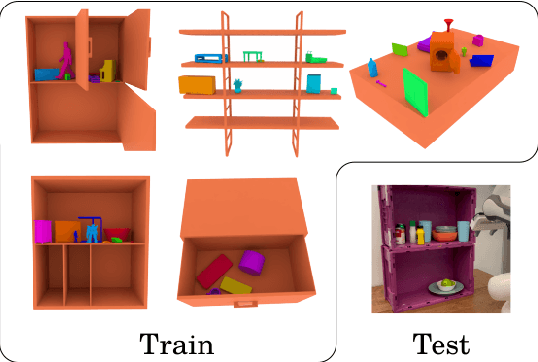
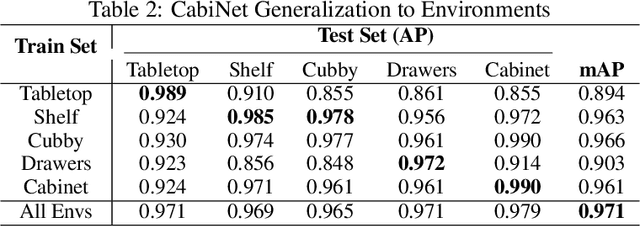
We address the important problem of generalizing robotic rearrangement to clutter without any explicit object models. We first generate over 650K cluttered scenes - orders of magnitude more than prior work - in diverse everyday environments, such as cabinets and shelves. We render synthetic partial point clouds from this data and use it to train our CabiNet model architecture. CabiNet is a collision model that accepts object and scene point clouds, captured from a single-view depth observation, and predicts collisions for SE(3) object poses in the scene. Our representation has a fast inference speed of 7 microseconds per query with nearly 20% higher performance than baseline approaches in challenging environments. We use this collision model in conjunction with a Model Predictive Path Integral (MPPI) planner to generate collision-free trajectories for picking and placing in clutter. CabiNet also predicts waypoints, computed from the scene's signed distance field (SDF), that allows the robot to navigate tight spaces during rearrangement. This improves rearrangement performance by nearly 35% compared to baselines. We systematically evaluate our approach, procedurally generate simulated experiments, and demonstrate that our approach directly transfers to the real world, despite training exclusively in simulation. Robot experiment demos in completely unknown scenes and objects can be found at this http https://cabinet-object-rearrangement.github.io
Stein Variational Model Predictive Control
Dec 09, 2020


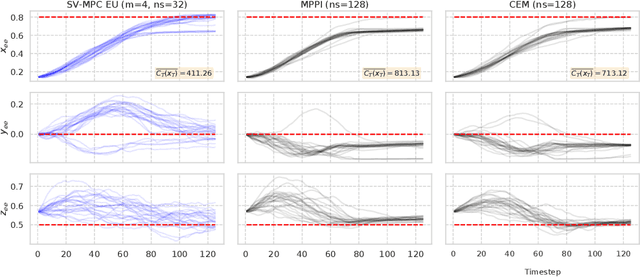
Decision making under uncertainty is critical to real-world, autonomous systems. Model Predictive Control (MPC) methods have demonstrated favorable performance in practice, but remain limited when dealing with complex probability distributions. In this paper, we propose a generalization of MPC that represents a multitude of solutions as posterior distributions. By casting MPC as a Bayesian inference problem, we employ variational methods for posterior computation, naturally encoding the complexity and multi-modality of the decision making problem. We propose a Stein variational gradient descent method to estimate the posterior directly over control parameters, given a cost function and observed state trajectories. We show that this framework leads to successful planning in challenging, non-convex optimal control problems.
Sim-to-Real Task Planning and Execution from Perception via Reactivity and Recovery
Nov 17, 2020
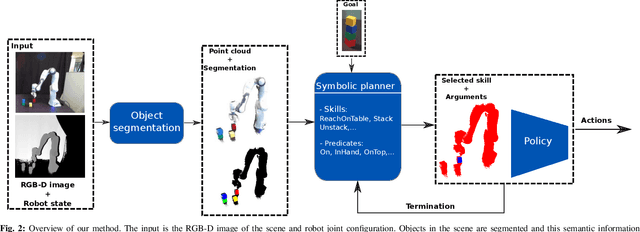

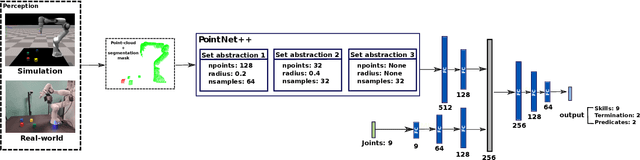
Zero-shot execution of unseen robotic tasks is an important problem in robotics. One potential approach is through task planning: combining known skills based on their preconditions and effects to achieve a user-specified goal. In this work, we propose such a task planning approach to build a reactive system for multi-step manipulation tasks that can be trained on simulation data and applied in the real-world. We explore a block-stacking task because it has a clear structure, where multiple skills must be chained together: pick up a block, place it on top of another block, etc. We learn these skills, along with a set of predicate preconditions and termination conditions, entirely in simulation. All components are learned as PointNet++ models, parameterized by the masks of relevant objects. The predicates allow us to create high-level plans combining different skills. They also serve as precondition functions for the skills, which enables the system to recognize failures and accomplish long-horizon tasks from perceptual input, which is critical for real-world execution. We evaluate our proposed approach in both simulation and in the real-world, showing an increase in success rate from 91.6% to 98% in simulation and from 10% to 80% success rate in the real-world as compared with naive baselines.
Trajectory Optimization for Coordinated Human-Robot Collaboration
Oct 10, 2019
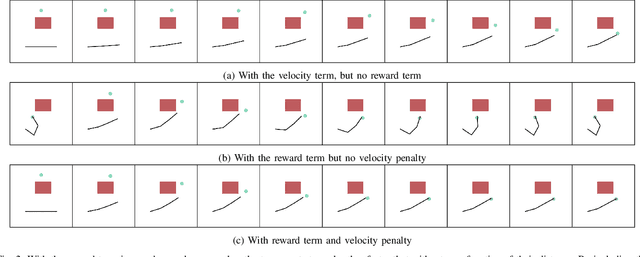
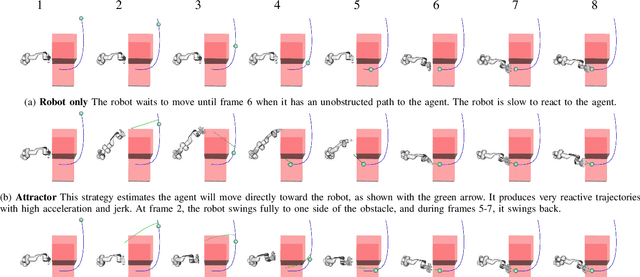
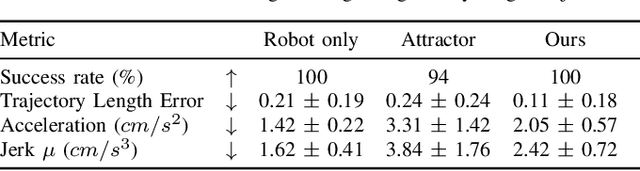
Effective human-robot collaboration requires informed anticipation. The robot must simultaneously anticipate what the human will do and react both instantaneously and fluidly when its predictions are wrong. Even more, the robot must plan its own actions in a way that accounts for the human predictions but also with the knowledge that the human's own behavior will change based on what the robot does. This back-and-forth game of prediction and planning is extremely difficult to model well using standard techniques. In this work, we exploit the duality between behavior prediction and control explored in the Inverse Optimal Control (IOC) literature to design a novel Model Predictive Control (MPC) algorithm that simultaneously plans the robot's behavior and predicts the human's behavior in a joint optimal control model. In the process, we develop a novel technique for bridging finite-horizon motion optimizers to the problem of spatially consistent continuous optimization using explicit sparse reward terms, i.e., negative cost. We demonstrate the framework on a collection of cooperative human-robot handover experiments in both simulation and with a real-world handover scenario.