 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgecuRobo: Parallelized Collision-Free Minimum-Jerk Robot Motion Generation
Nov 03, 2023
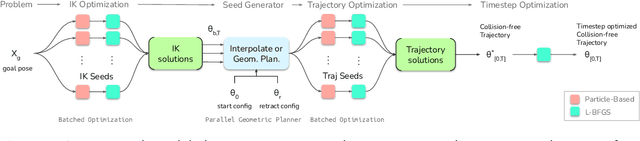
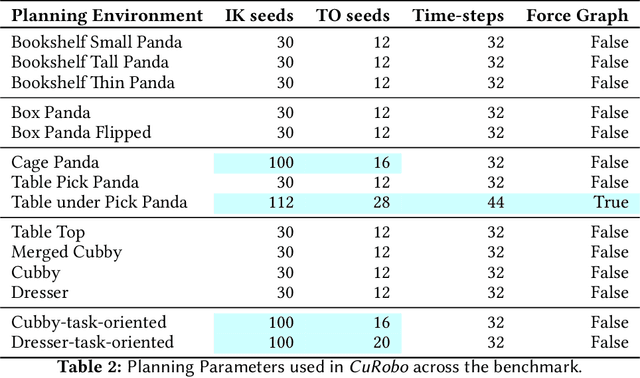
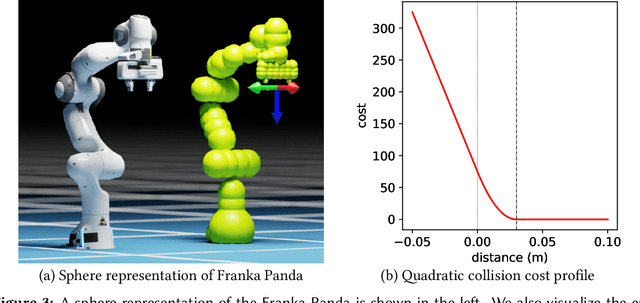
This paper explores the problem of collision-free motion generation for manipulators by formulating it as a global motion optimization problem. We develop a parallel optimization technique to solve this problem and demonstrate its effectiveness on massively parallel GPUs. We show that combining simple optimization techniques with many parallel seeds leads to solving difficult motion generation problems within 50ms on average, 60x faster than state-of-the-art (SOTA) trajectory optimization methods. We achieve SOTA performance by combining L-BFGS step direction estimation with a novel parallel noisy line search scheme and a particle-based optimization solver. To further aid trajectory optimization, we develop a parallel geometric planner that plans within 20ms and also introduce a collision-free IK solver that can solve over 7000 queries/s. We package our contributions into a state of the art GPU accelerated motion generation library, cuRobo and release it to enrich the robotics community. Additional details are available at https://curobo.org
VaPr: Variable-Precision Tensors to Accelerate Robot Motion Planning
Oct 11, 2023



High-dimensional motion generation requires numerical precision for smooth, collision-free solutions. Typically, double-precision or single-precision floating-point (FP) formats are utilized. Using these for big tensors imposes a strain on the memory bandwidth provided by the devices and alters the memory footprint, hence limiting their applicability to low-power edge devices needed for mobile robots. The uniform application of reduced precision can be advantageous but severely degrades solutions. Using decreased precision data types for important tensors, we propose to accelerate motion generation by removing memory bottlenecks. We propose variable-precision (VaPr) search optimization to determine the appropriate precision for large tensors from a vast search space of approximately 4 million unique combinations for FP data types across the tensors. To obtain the efficiency gains, we exploit existing platform support for an out-of-the-box GPU speedup and evaluate prospective precision converter units for GPU types that are not currently supported. Our experimental results on 800 planning problems for the Franka Panda robot on the MotionBenchmaker dataset across 8 environments show that a 4-bit FP format is sufficient for the largest set of tensors in the motion generation stack. With the software-only solution, VaPr achieves 6.3% and 6.3% speedups on average for a significant portion of motion generation over the SOTA solution (CuRobo) on Jetson Orin and RTX2080 Ti GPU, respectively, and 9.9%, 17.7% speedups with the FP converter.
Safety-Critical Scenario Generation Via Reinforcement Learning Based Editing
Jun 25, 2023



Generating safety-critical scenarios is essential for testing and verifying the safety of autonomous vehicles. Traditional optimization techniques suffer from the curse of dimensionality and limit the search space to fixed parameter spaces. To address these challenges, we propose a deep reinforcement learning approach that generates scenarios by sequential editing, such as adding new agents or modifying the trajectories of the existing agents. Our framework employs a reward function consisting of both risk and plausibility objectives. The plausibility objective leverages generative models, such as a variational autoencoder, to learn the likelihood of the generated parameters from the training datasets; It penalizes the generation of unlikely scenarios. Our approach overcomes the dimensionality challenge and explores a wide range of safety-critical scenarios. Our evaluation demonstrates that the proposed method generates safety-critical scenarios of higher quality compared with previous approaches.
Zhuyi: Perception Processing Rate Estimation for Safety in Autonomous Vehicles
May 06, 2022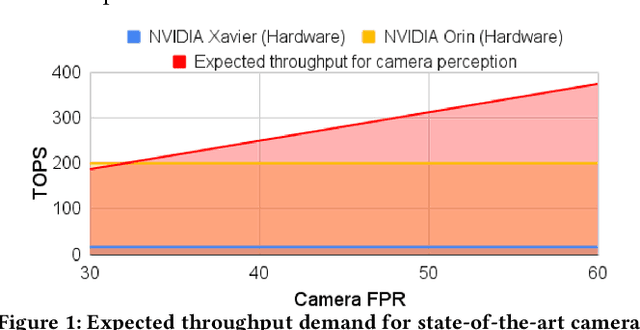
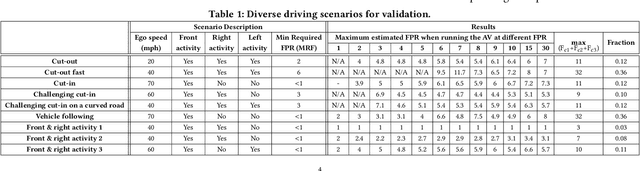
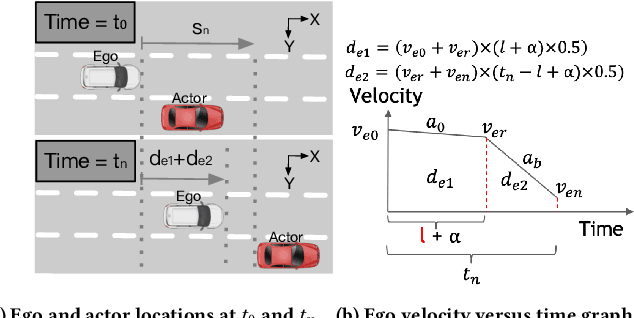
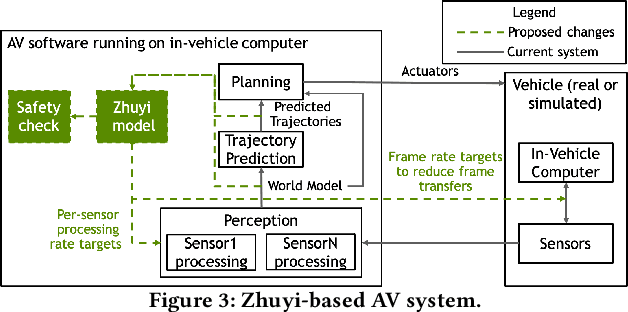
The processing requirement of autonomous vehicles (AVs) for high-accuracy perception in complex scenarios can exceed the resources offered by the in-vehicle computer, degrading safety and comfort. This paper proposes a sensor frame processing rate (FPR) estimation model, Zhuyi, that quantifies the minimum safe FPR continuously in a driving scenario. Zhuyi can be employed post-deployment as an online safety check and to prioritize work. Experiments conducted using a multi-camera state-of-the-art industry AV system show that Zhuyi's estimated FPRs are conservative, yet the system can maintain safety by processing only 36% or fewer frames compared to a default 30-FPR system in the tested scenarios.
Generating and Characterizing Scenarios for Safety Testing of Autonomous Vehicles
Mar 12, 2021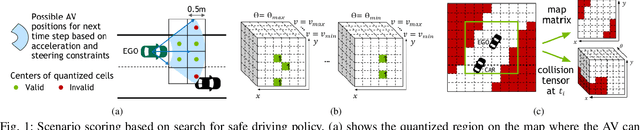
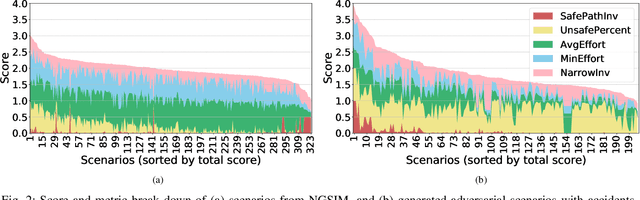
Extracting interesting scenarios from real-world data as well as generating failure cases is important for the development and testing of autonomous systems. We propose efficient mechanisms to both characterize and generate testing scenarios using a state-of-the-art driving simulator. For any scenario, our method generates a set of possible driving paths and identifies all the possible safe driving trajectories that can be taken starting at different times, to compute metrics that quantify the complexity of the scenario. We use our method to characterize real driving data from the Next Generation Simulation (NGSIM) project, as well as adversarial scenarios generated in simulation. We rank the scenarios by defining metrics based on the complexity of avoiding accidents and provide insights into how the AV could have minimized the probability of incurring an accident. We demonstrate a strong correlation between the proposed metrics and human intuition.
Making Convolutions Resilient via Algorithm-Based Error Detection Techniques
Jun 08, 2020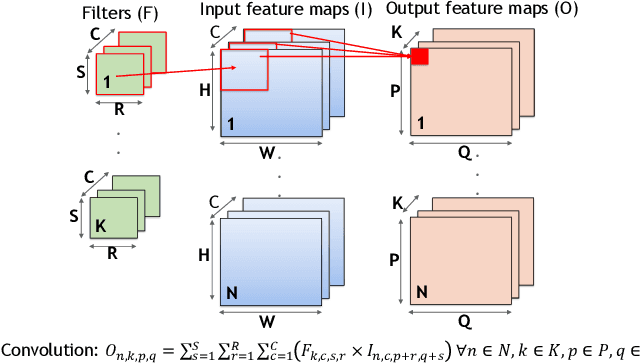
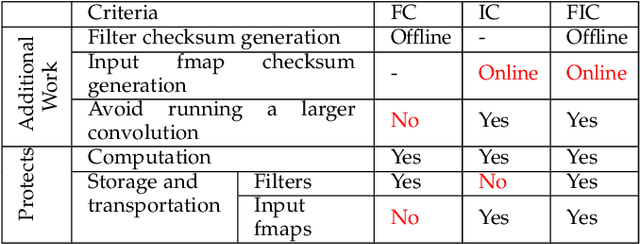
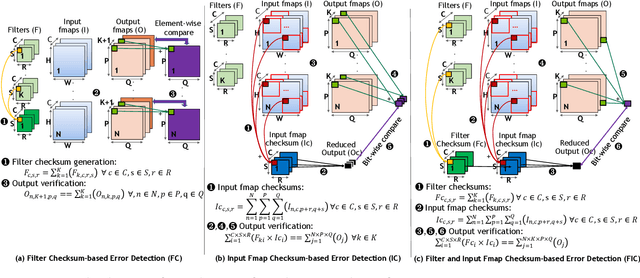

The ability of Convolutional Neural Networks (CNNs) to accurately process real-time telemetry has boosted their use in safety-critical and high-performance computing systems. As such systems require high levels of resilience to errors, CNNs must execute correctly in the presence of hardware faults. Full duplication provides the needed assurance but incurs a prohibitive 100% overhead. Algorithmic techniques are known to offer low-cost solutions, but the practical feasibility and performance of such techniques have never been studied for CNN deployment platforms (e.g., TensorFlow or TensorRT on GPUs). In this paper, we focus on algorithmically verifying Convolutions, which are the most resource-demanding operations in CNNs. We use checksums to verify convolutions, adding a small amount of redundancy, far less than full-duplication. We first identify the challenges that arise in employing Algorithm-Based Error Detection (ABED) for Convolutions in optimized inference platforms that fuse multiple network layers and use reduced-precision operations, and demonstrate how to overcome them. We propose and evaluate variations of ABED techniques that offer implementation complexity, runtime overhead, and coverage trade-offs. Results show that ABED can detect all transient hardware errors that might otherwise corrupt output and does so while incurring low runtime overheads (6-23%), offering at least 1.6X throughput to workloads compared to full duplication.
HarDNN: Feature Map Vulnerability Evaluation in CNNs
Feb 25, 2020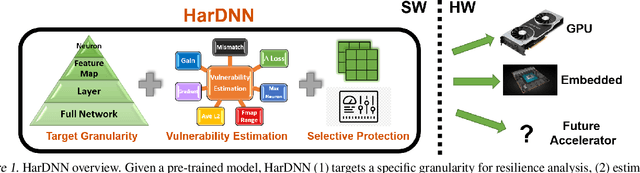
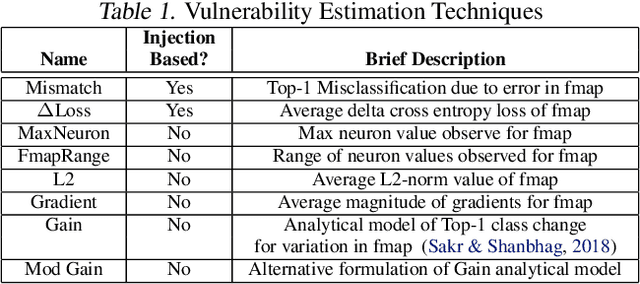
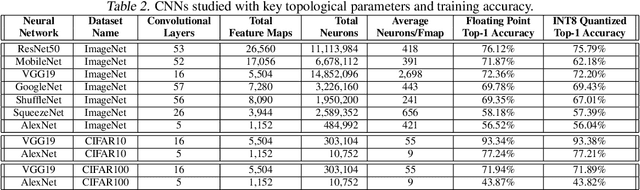
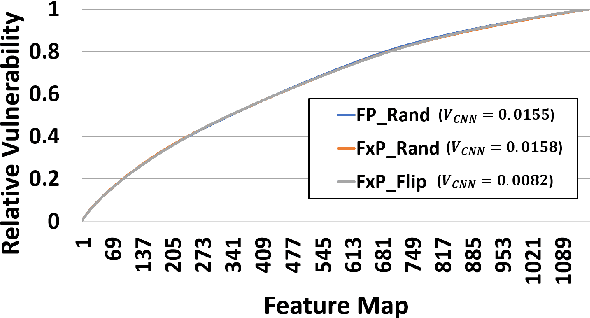
As Convolutional Neural Networks (CNNs) are increasingly being employed in safety-critical applications, it is important that they behave reliably in the face of hardware errors. Transient hardware errors may percolate undesirable state during execution, resulting in software-manifested errors which can adversely affect high-level decision making. This paper presents HarDNN, a software-directed approach to identify vulnerable computations during a CNN inference and selectively protect them based on their propensity towards corrupting the inference output in the presence of a hardware error. We show that HarDNN can accurately estimate relative vulnerability of a feature map (fmap) in CNNs using a statistical error injection campaign, and explore heuristics for fast vulnerability assessment. Based on these results, we analyze the tradeoff between error coverage and computational overhead that the system designers can use to employ selective protection. Results show that the improvement in resilience for the added computation is superlinear with HarDNN. For example, HarDNN improves SqueezeNet's resilience by 10x with just 30% additional computations.