 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgent Memory: Characterization and System Implications of Stateful Long-Horizon Workloads
Jun 04, 2026LLM agents are increasingly deployed on long-horizon tasks requiring sustained reasoning over extended interaction histories. Realizing this at scale requires agents to persistently store, retrieve, and update their own memory across sessions. A rich ecosystem of agent memory systems has emerged spanning flat retrieval, LLM-mediated extraction, consolidating fact stores, and agentic control flows. Yet, their system-level behavior remains uncharacterized. We present the first systems characterization of agent memory. First, we introduce a system-oriented taxonomy classifying agent memory systems along four axes. Second, we build a phase-aware profiling harness attributing cost to construction, retrieval, and generation. Third, we characterize ten representative systems across two benchmark suites, uncovering how design choices shift cost across the write and read paths. Finally, we derive 10 system recommendations covering construction scheduling, capability floors, amortization via query volume, freshness-latency tradeoffs, and fleet-scale management.
AgenticCache: Cache-Driven Asynchronous Planning for Embodied AI Agents
Apr 27, 2026Embodied AI agents increasingly rely on large language models (LLMs) for planning, yet per-step LLM calls impose severe latency and cost. In this paper, we show that embodied tasks exhibit strong plan locality, where the next plan is largely predictable from the current one. Building on this, we introduce AgenticCache, a planning framework that reuses cached plans to avoid per-step LLM calls. In AgenticCache, each agent queries a runtime cache of frequent plan transitions, while a background Cache Updater asynchronously calls the LLM to validate and refine cached entries. Across four multi-agent embodied benchmarks, AgenticCache improves task success rate by 22% on average across 12 configurations (4 benchmarks x 3 models), reduces simulation latency by 65%, and lowers token usage by 50%. Cache-based plan reuse thus offers a practical path to low-latency, low-cost embodied agents. Code is available at https://github.com/hojoonleokim/MLSys26_AgenticCache.
SemanticDialect: Semantic-Aware Mixed-Format Quantization for Video Diffusion Transformers
Mar 03, 2026Diffusion Transformers (DiT) achieve strong video generation quality, but their memory and compute costs hinder edge deployment. Quantization can reduce these costs, yet existing methods often degrade video quality under high activation variation and the need to preserve semantic/temporal coherence. We propose SemanticDialect, which advances recent block-wise mixed-format quantization-selecting a per-block optimal format (a dialect) from multiple candidates (a formatbook)-by scaling the formatbook with lookup tables for quantization error and quantized values, enabling efficient per-block format selection and quantization at low online cost. We also introduce activation decomposition that reduces quantization error by re-quantizing and adding back residual errors, with attention-guided salient token selection. We further propose semantic-aware dialect assignment (SeDA) to improve quantized value consistency by sharing a sub-formatbook among semantically correlated tokens. Experiments on video DiT (VDiT) models show that SemanticDialect outperforms prior VDiT quantization methods and fine-grained block-wise format baselines, while approaching FP16 quality on Open-Sora 2.0.
LLM-FSM: Scaling Large Language Models for Finite-State Reasoning in RTL Code Generation
Feb 03, 2026Finite-state reasoning, the ability to understand and implement state-dependent behavior, is central to hardware design. In this paper, we present LLM-FSM, a benchmark that evaluates how well large language models (LLMs) can recover finite-state machine (FSM) behavior from natural-language specifications and translate it into correct register transfer-level (RTL) implementations. Unlike prior specification-to-RTL benchmarks that rely on manually constructed examples, LLM-FSM is built through a fully automated pipeline. LLM-FSM first constructs FSM with configurable state counts and constrained transition structures. It then prompts LLMs to express each FSM in a structured YAML format with an application context, and to further convert that YAML into a natural-language (NL) specification. From the same YAML, our pipeline synthesizes the reference RTL and testbench in a correct-by-construction manner. All 1,000 problems are verified using LLM-based and SAT-solver-based checks, with human review on a subset. Our experiments show that even the strongest LLMs exhibit sharply declining accuracy as FSM complexity increases. We further demonstrate that training-time scaling via supervised fine-tuning (SFT) generalizes effectively to out-of-distribution (OOD) tasks, while increasing test-time compute improves reasoning reliability. Finally, LLM-FSM remains extensible by allowing its FSM complexity to scale with future model capabilities.
P3-LLM: An Integrated NPU-PIM Accelerator for LLM Inference Using Hybrid Numerical Formats
Nov 16, 2025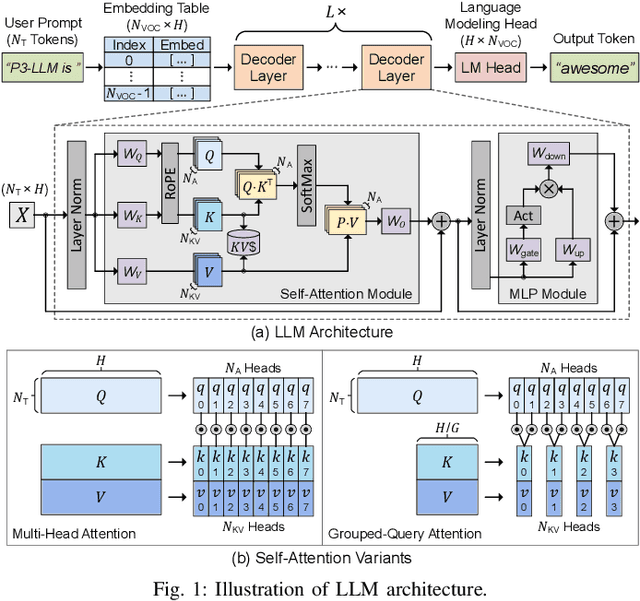
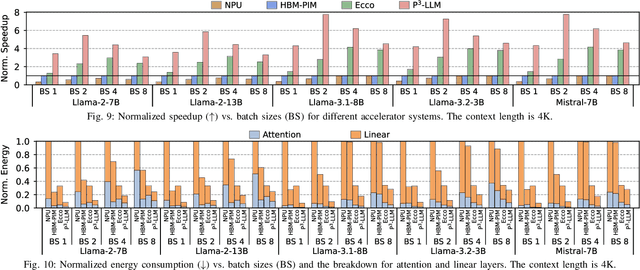
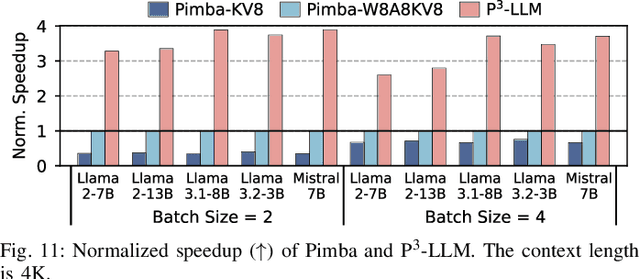
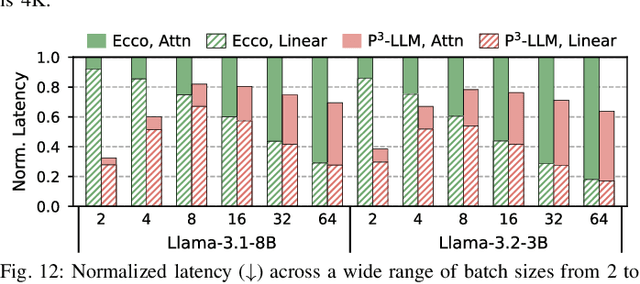
The substantial memory bandwidth and computational demands of large language models (LLMs) present critical challenges for efficient inference. To tackle this, the literature has explored heterogeneous systems that combine neural processing units (NPUs) with DRAM-based processing-in-memory (PIM) for LLM acceleration. However, existing high-precision (e.g., FP16) PIM compute units incur significant area and power overhead in DRAM technology, limiting the effective computation throughput. In this paper, we introduce P3-LLM, a novel NPU-PIM integrated accelerator for LLM inference using hybrid numerical formats. Our approach is threefold: First, we propose a flexible mixed-precision quantization scheme, which leverages hybrid numerical formats to quantize different LLM operands with high compression efficiency and minimal accuracy loss. Second, we architect an efficient PIM accelerator for P3-LLM, featuring enhanced compute units to support hybrid numerical formats. Our careful choice of numerical formats allows to co-design low-precision PIM compute units that significantly boost the computation throughput under iso-area constraints. Third, we optimize the low-precision dataflow of different LLM modules by applying operator fusion to minimize the overhead of runtime dequantization. Evaluation on a diverse set of representative LLMs and tasks demonstrates that P3-LLM achieves state-of-the-art accuracy in terms of both KV-cache quantization and weight-activation quantization. Combining the proposed quantization scheme with PIM architecture co-design, P3-LLM yields an average of $4.9\times$, $2.0\times$, and $3.4\times$ speedups over the state-of-the-art LLM accelerators HBM-PIM, Ecco, and Pimba, respectively. Our quantization code is available at https://github.com/yc2367/P3-LLM.git
Vision-Language Alignment from Compressed Image Representations using 2D Gaussian Splatting
Sep 26, 2025Modern vision language pipelines are driven by RGB vision encoders trained on massive image text corpora. While these pipelines have enabled impressive zero shot capabilities and strong transfer across tasks, they still inherit two structural inefficiencies from the pixel domain: (i) transmitting dense RGB images from edge devices to the cloud is energy intensive and costly, and (ii) patch based tokenization explodes sequence length, stressing attention budgets and context limits. We explore 2D Gaussian Splatting (2DGS) as an alternative visual substrate for alignment: a compact, spatially adaptive representation that parameterizes images by a set of colored anisotropic Gaussians. We develop a scalable 2DGS pipeline with structured initialization, luminance aware pruning, and batched CUDA kernels, achieving over 90x faster fitting and about 97% GPU utilization compared to prior implementations. We further adapt contrastive language image pretraining (CLIP) to 2DGS by reusing a frozen RGB-based transformer backbone with a lightweight splat aware input stem and a perceiver resampler, training only about 7% of the total parameters. On large DataComp subsets, GS encoders yield meaningful zero shot ImageNet-1K performance while compressing inputs 3 to 20x relative to pixels. While accuracy currently trails RGB encoders, our results establish 2DGS as a viable multimodal substrate, pinpoint architectural bottlenecks, and open a path toward representations that are both semantically powerful and transmission efficient for edge cloud learning.
Token Sequence Compression for Efficient Multimodal Computing
Apr 24, 2025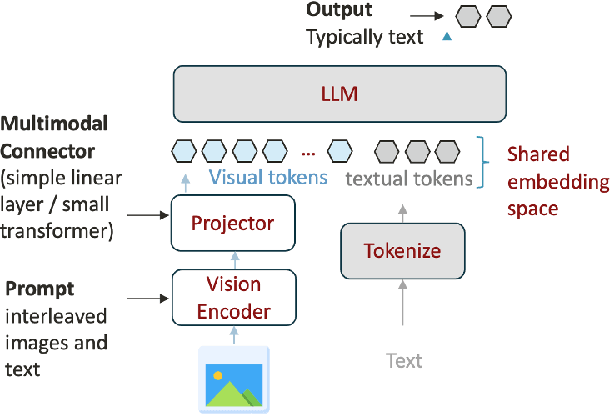

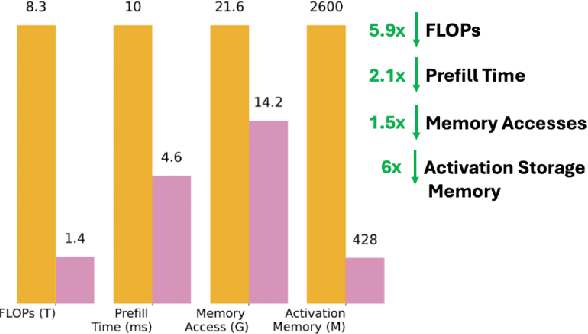

The exponential growth of Large Multimodal Models (LMMs) has driven advancements in cross-modal reasoning but at significant computational costs. In this work, we focus on visual language models. We highlight the redundancy and inefficiency in current vision encoders, and seek to construct an adaptive compression method for multimodal data. In this work, we characterize a panoply of visual token selection and merging approaches through both benchmarking and qualitative analysis. In particular, we demonstrate that simple cluster-level token aggregation outperforms prior state-of-the-art works in token selection and merging, including merging at the vision encoder level and attention-based approaches. We underline the redundancy in current vision encoders, and shed light on several puzzling trends regarding principles of visual token selection through cross-modal attention visualizations. This work is a first effort towards more effective encoding and processing of high-dimensional data, and paves the way for more scalable and sustainable multimodal systems.
BlockDialect: Block-wise Fine-grained Mixed Format for Energy-Efficient LLM Inference
Jan 03, 2025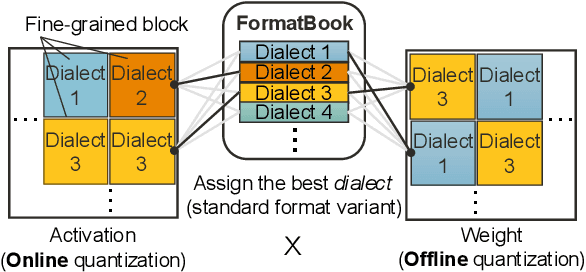
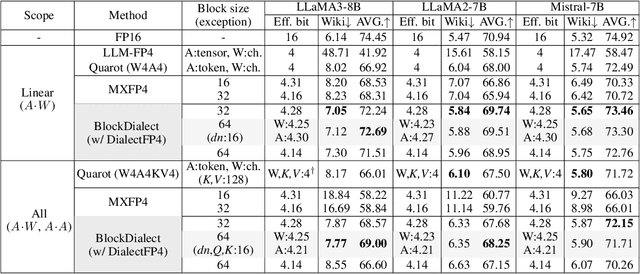
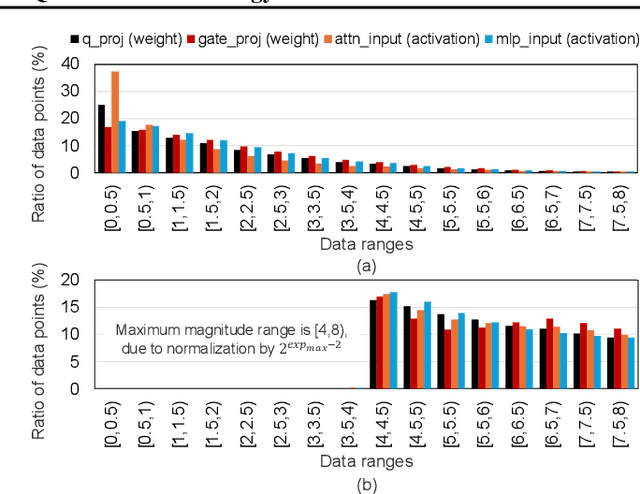
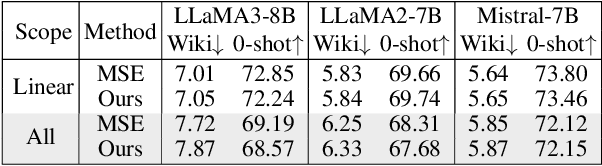
Large Language Models (LLMs) have achieved remarkable success, but their increasing size poses significant challenges in memory usage and computational costs. Quantizing both weights and activations can address these issues, with fine-grained block-wise quantization emerging as a promising hardware-supported solution to mitigate outliers. However, existing methods struggle to capture nuanced block data distributions. To address this, we propose BlockDialect, a block-wise fine-grained mixed format technique that assigns a per-block optimal number format from formatbook for better data representation. Additionally, we introduce DialectFP4, a formatbook of FP4 variants (akin to dialects) that adapt to diverse data distributions. To leverage this efficiently, we propose a two-stage approach for online DialectFP4 activation quantization. Importantly, DialectFP4 ensures hardware efficiency by selecting representable values as scaled integers compatible with low-precision integer arithmetic. BlockDialect achieves 11.83% (7.56%) accuracy gain on the LLaMA3-8B (LLaMA2-7B) model compared to MXFP4 format with lower bit usage per data, while being only 5.46% (2.65%) below full precision even when quantizing full-path matrix multiplication. Focusing on how to represent over how to scale, our work presents a promising path for energy-efficient LLM inference.
VaPr: Variable-Precision Tensors to Accelerate Robot Motion Planning
Oct 11, 2023



High-dimensional motion generation requires numerical precision for smooth, collision-free solutions. Typically, double-precision or single-precision floating-point (FP) formats are utilized. Using these for big tensors imposes a strain on the memory bandwidth provided by the devices and alters the memory footprint, hence limiting their applicability to low-power edge devices needed for mobile robots. The uniform application of reduced precision can be advantageous but severely degrades solutions. Using decreased precision data types for important tensors, we propose to accelerate motion generation by removing memory bottlenecks. We propose variable-precision (VaPr) search optimization to determine the appropriate precision for large tensors from a vast search space of approximately 4 million unique combinations for FP data types across the tensors. To obtain the efficiency gains, we exploit existing platform support for an out-of-the-box GPU speedup and evaluate prospective precision converter units for GPU types that are not currently supported. Our experimental results on 800 planning problems for the Franka Panda robot on the MotionBenchmaker dataset across 8 environments show that a 4-bit FP format is sufficient for the largest set of tensors in the motion generation stack. With the software-only solution, VaPr achieves 6.3% and 6.3% speedups on average for a significant portion of motion generation over the SOTA solution (CuRobo) on Jetson Orin and RTX2080 Ti GPU, respectively, and 9.9%, 17.7% speedups with the FP converter.
CAMEL: Co-Designing AI Models and Embedded DRAMs for Efficient On-Device Learning
May 04, 2023



The emergence of the Internet of Things (IoT) has resulted in a remarkable amount of data generated on edge devices, which are often processed using AI algorithms. On-device learning enables edge platforms to continually adapt the AI models to user personal data and further allows for a better service quality. However, AI training on resource-limited devices is extremely difficult because of the intensive computing workload and the significant amount of on-chip memory consumption exacted by deep neural networks (DNNs). To mitigate this, we propose to use embedded dynamic random-access memory (eDRAM) as the main storage medium of training data. Compared with static random-access memory (SRAM), eDRAM introduces more than $2\times$ improvement on storage density, enabling reduced off-chip memory traffic. However, to keep the stored data intact, eDRAM is required to perform the power-hungry data refresh operations. eDRAM refresh can be eliminated if the data is stored for a period of time that is shorter than the eDRAM retention time. To achieve this, we design a novel reversible DNN architecture that enables a significantly reduced data lifetime during the training process and removes the need for eDRAM refresh. We further design an efficient on-device training engine, termed~\textit{CAMEL}, that uses eDRAM as the main on-chip memory. CAMEL enables the intermediate results during training to fit fully in on-chip eDRAM arrays and completely eliminates the off-chip DRAM traffic during the training process. We evaluate our CAMEL system on multiple DNNs with different datasets, demonstrating a more than $3\times$ saving on total DNN training energy consumption than the other baselines, while achieving a similar (even better) performance in validation accuracy.