 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnergy-efficient Task Adaptation for NLP Edge Inference Leveraging Heterogeneous Memory Architectures
Apr 12, 2023



Executing machine learning inference tasks on resource-constrained edge devices requires careful hardware-software co-design optimizations. Recent examples have shown how transformer-based deep neural network models such as ALBERT can be used to enable the execution of natural language processing (NLP) inference on mobile systems-on-chip housing custom hardware accelerators. However, while these existing solutions are effective in alleviating the latency, energy, and area costs of running single NLP tasks, achieving multi-task inference requires running computations over multiple variants of the model parameters, which are tailored to each of the targeted tasks. This approach leads to either prohibitive on-chip memory requirements or paying the cost of off-chip memory access. This paper proposes adapter-ALBERT, an efficient model optimization for maximal data reuse across different tasks. The proposed model's performance and robustness to data compression methods are evaluated across several language tasks from the GLUE benchmark. Additionally, we demonstrate the advantage of mapping the model to a heterogeneous on-chip memory architecture by performing simulations on a validated NLP edge accelerator to extrapolate performance, power, and area improvements over the execution of a traditional ALBERT model on the same hardware platform.
EdgeBERT: Optimizing On-Chip Inference for Multi-Task NLP
Dec 01, 2020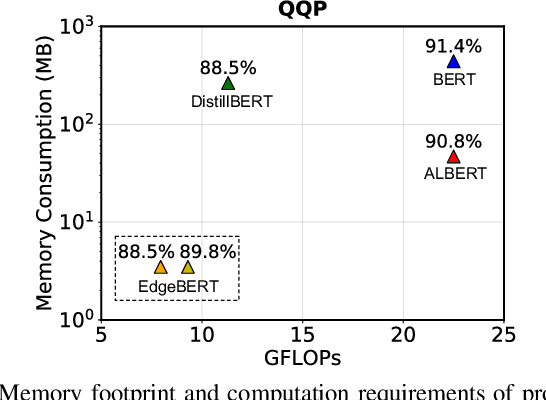
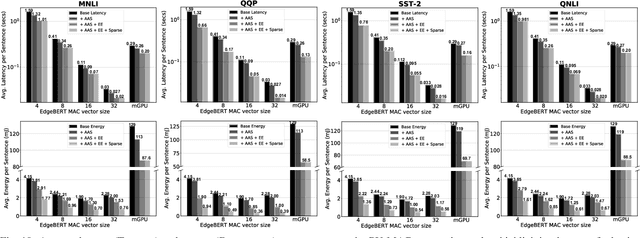
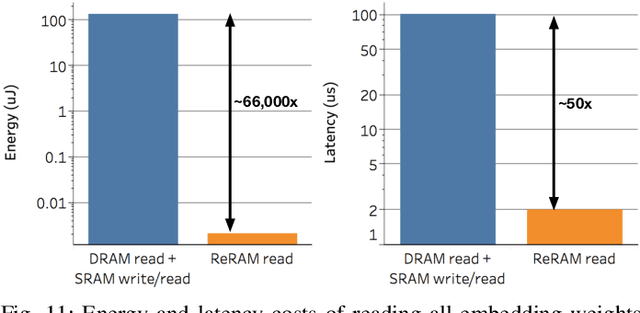
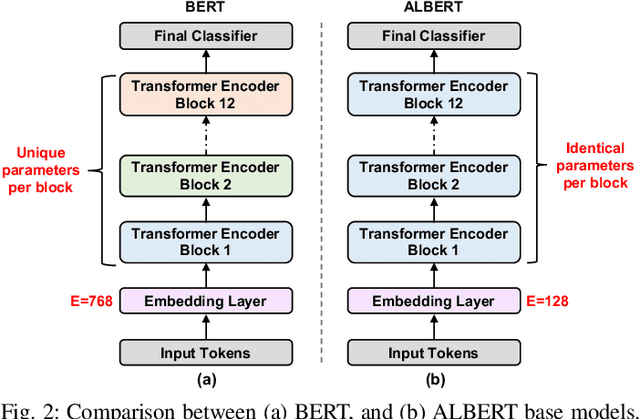
Transformer-based language models such as BERT provide significant accuracy improvement to a multitude of natural language processing (NLP) tasks. However, their hefty computational and memory demands make them challenging to deploy to resource-constrained edge platforms with strict latency requirements. We present EdgeBERT an in-depth and principled algorithm and hardware design methodology to achieve minimal latency and energy consumption on multi-task NLP inference. Compared to the ALBERT baseline, we achieve up to 2.4x and 13.4x inference latency and memory savings, respectively, with less than 1%-pt drop in accuracy on several GLUE benchmarks by employing a calibrated combination of 1) entropy-based early stopping, 2) adaptive attention span, 3) movement and magnitude pruning, and 4) floating-point quantization. Furthermore, in order to maximize the benefits of these algorithms in always-on and intermediate edge computing settings, we specialize a scalable hardware architecture wherein floating-point bit encodings of the shareable multi-task embedding parameters are stored in high-density non-volatile memory. Altogether, EdgeBERT enables fully on-chip inference acceleration of NLP workloads with 5.2x, and 157x lower energy than that of an un-optimized accelerator and CUDA adaptations on an Nvidia Jetson Tegra X2 mobile GPU, respectively.