 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOMU: A Probabilistic 3D Occupancy Mapping Accelerator for Real-time OctoMap at the Edge
May 06, 2022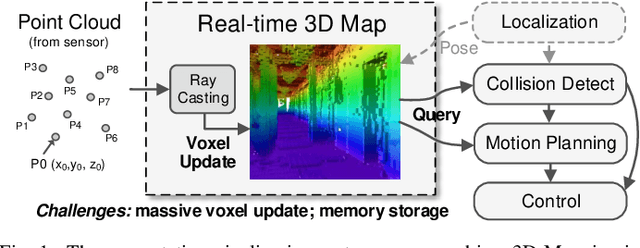
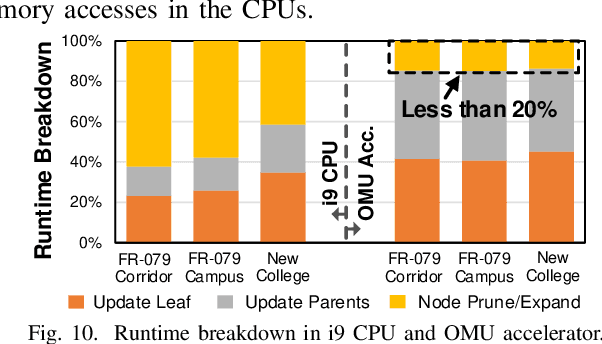
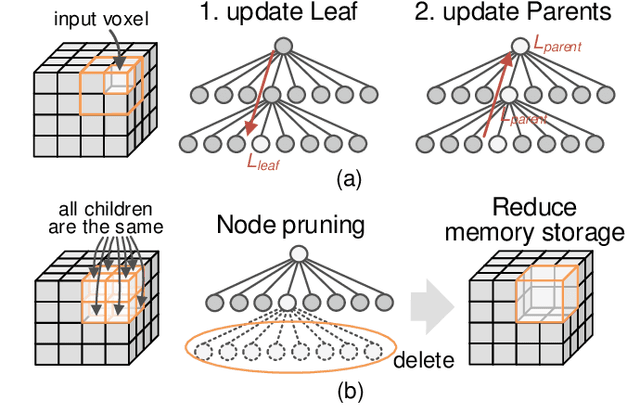
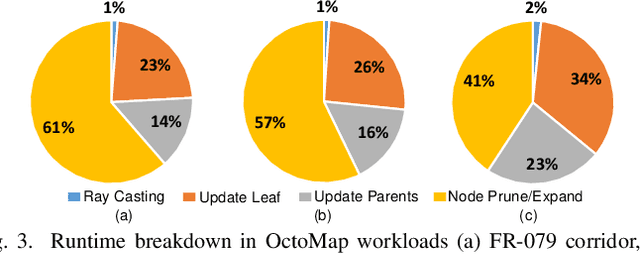
Autonomous machines (e.g., vehicles, mobile robots, drones) require sophisticated 3D mapping to perceive the dynamic environment. However, maintaining a real-time 3D map is expensive both in terms of compute and memory requirements, especially for resource-constrained edge machines. Probabilistic OctoMap is a reliable and memory-efficient 3D dense map model to represent the full environment, with dynamic voxel node pruning and expansion capacity. This paper presents the first efficient accelerator solution, i.e. OMU, to enable real-time probabilistic 3D mapping at the edge. To improve the performance, the input map voxels are updated via parallel PE units for data parallelism. Within each PE, the voxels are stored using a specially developed data structure in parallel memory banks. In addition, a pruning address manager is designed within each PE unit to reuse the pruned memory addresses. The proposed 3D mapping accelerator is implemented and evaluated using a commercial 12 nm technology. Compared to the ARM Cortex-A57 CPU in the Nvidia Jetson TX2 platform, the proposed accelerator achieves up to 62$\times$ performance and 708$\times$ energy efficiency improvement. Furthermore, the accelerator provides 63 FPS throughput, more than 2$\times$ higher than a real-time requirement, enabling real-time perception for 3D mapping.
EdgeBERT: Optimizing On-Chip Inference for Multi-Task NLP
Dec 01, 2020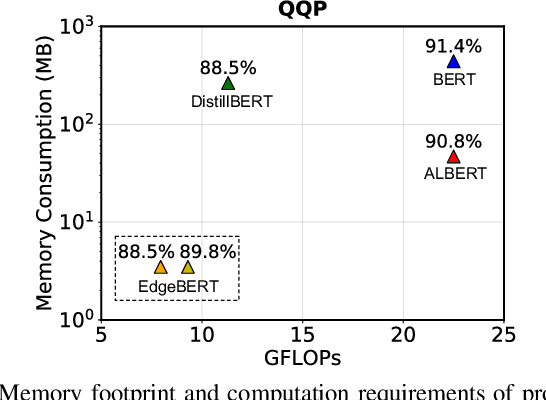
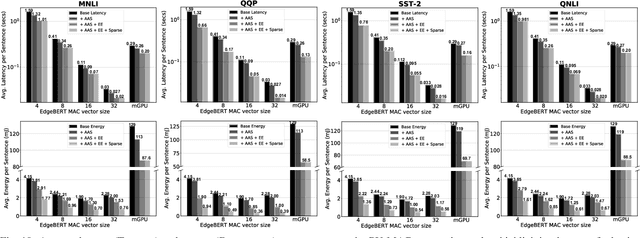
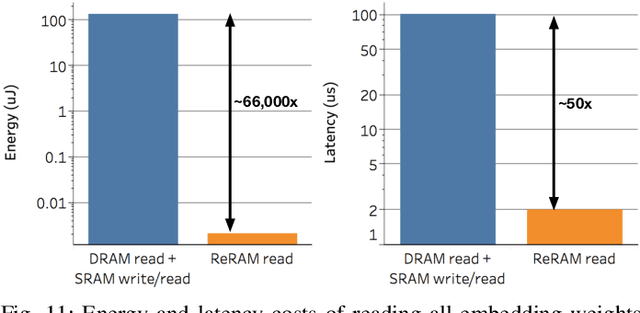
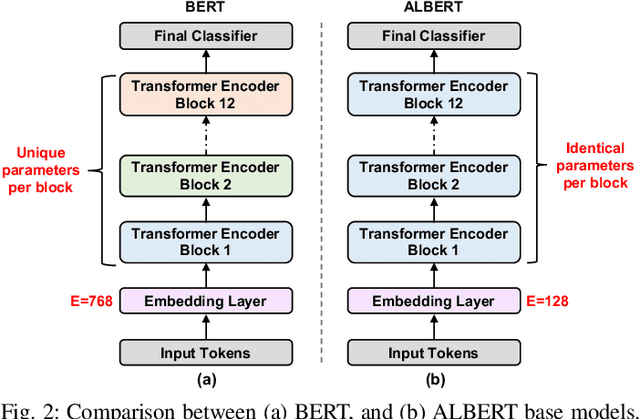
Transformer-based language models such as BERT provide significant accuracy improvement to a multitude of natural language processing (NLP) tasks. However, their hefty computational and memory demands make them challenging to deploy to resource-constrained edge platforms with strict latency requirements. We present EdgeBERT an in-depth and principled algorithm and hardware design methodology to achieve minimal latency and energy consumption on multi-task NLP inference. Compared to the ALBERT baseline, we achieve up to 2.4x and 13.4x inference latency and memory savings, respectively, with less than 1%-pt drop in accuracy on several GLUE benchmarks by employing a calibrated combination of 1) entropy-based early stopping, 2) adaptive attention span, 3) movement and magnitude pruning, and 4) floating-point quantization. Furthermore, in order to maximize the benefits of these algorithms in always-on and intermediate edge computing settings, we specialize a scalable hardware architecture wherein floating-point bit encodings of the shareable multi-task embedding parameters are stored in high-density non-volatile memory. Altogether, EdgeBERT enables fully on-chip inference acceleration of NLP workloads with 5.2x, and 157x lower energy than that of an un-optimized accelerator and CUDA adaptations on an Nvidia Jetson Tegra X2 mobile GPU, respectively.
AdaptivFloat: A Floating-point based Data Type for Resilient Deep Learning Inference
Oct 15, 2019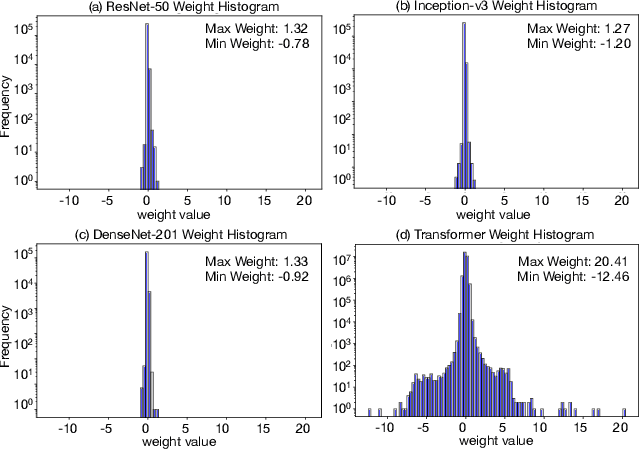

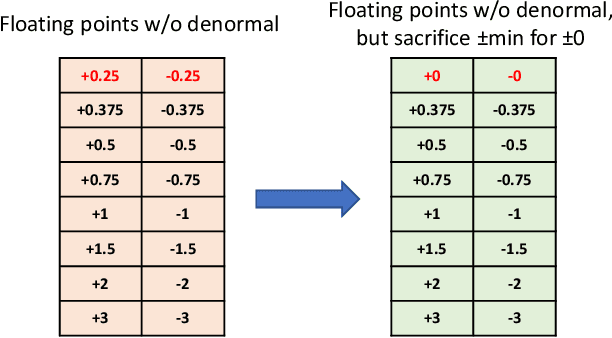

Conventional hardware-friendly quantization methods, such as fixed-point or integer, tend to perform poorly at very low word sizes as their shrinking dynamic ranges cannot adequately capture the wide data distributions commonly seen in sequence transduction models. We present AdaptivFloat, a floating-point inspired number representation format for deep learning that dynamically maximizes and optimally clips its available dynamic range, at a layer granularity, in order to create faithful encoding of neural network parameters. AdaptivFloat consistently produces higher inference accuracies compared to block floating-point, uniform, IEEE-like float or posit encodings at very low precision ($\leq$ 8-bit) across a diverse set of state-of-the-art neural network topologies. And notably, AdaptivFloat is seen surpassing baseline FP32 performance by up to +0.3 in BLEU score and -0.75 in word error rate at weight bit widths that are $\leq$ 8-bit. Experimental results on a deep neural network (DNN) hardware accelerator, exploiting AdaptivFloat logic in its computational datapath, demonstrate per-operation energy and area that is 0.9$\times$ and 1.14$\times$, respectively, that of equivalent bit width integer-based accelerator variants.