 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLong Grounded Thoughts: Distilling Compositional Visual Reasoning Chains at Scale
Nov 07, 2025Recent progress in multimodal reasoning has been driven largely by undisclosed datasets and proprietary data synthesis recipes, leaving open questions about how to systematically build large-scale, vision-centric reasoning datasets, particularly for tasks that go beyond visual math. In this work, we introduce a new reasoning data generation framework spanning diverse skills and levels of complexity with over 1M high-quality synthetic vision-centric questions. The dataset also includes preference data and instruction prompts supporting both offline and online RL. Our synthesis framework proceeds in two stages: (1) scale; and (2) complexity. Reasoning traces are then synthesized through a two-stage process that leverages VLMs and reasoning LLMs, producing CoT traces for VLMs that capture the richness and diverse cognitive behaviors found in frontier reasoning models. Remarkably, we show that finetuning Qwen2.5-VL-7B on our data outperforms all open-data baselines across all evaluated vision-centric benchmarks, and even surpasses strong closed-data models such as MiMo-VL-7B-RL on V* Bench, CV-Bench and MMStar-V. Perhaps most surprising, despite being entirely vision-centric, our data transfers positively to text-only reasoning (MMLU-Pro) and audio reasoning (MMAU), demonstrating its effectiveness. Similarly, despite not containing videos or embodied visual data, we observe notable gains when evaluating on a single-evidence embodied QA benchmark (NiEH). Finally, we use our data to analyze the entire VLM post-training pipeline. Our empirical analysis highlights that (i) SFT on high-quality data with non-linear reasoning traces is essential for effective online RL, (ii) staged offline RL matches online RL's performance while reducing compute demands, and (iii) careful SFT on high quality data can substantially improve out-of-domain, cross-modality transfer.
TokDrift: When LLM Speaks in Subwords but Code Speaks in Grammar
Oct 16, 2025Large language models (LLMs) for code rely on subword tokenizers, such as byte-pair encoding (BPE), learned from mixed natural language text and programming language code but driven by statistics rather than grammar. As a result, semantically identical code snippets can be tokenized differently depending on superficial factors such as whitespace or identifier naming. To measure the impact of this misalignment, we introduce TokDrift, a framework that applies semantic-preserving rewrite rules to create code variants differing only in tokenization. Across nine code LLMs, including large ones with over 30B parameters, even minor formatting changes can cause substantial shifts in model behavior. Layer-wise analysis shows that the issue originates in early embeddings, where subword segmentation fails to capture grammar token boundaries. Our findings identify misaligned tokenization as a hidden obstacle to reliable code understanding and generation, highlighting the need for grammar-aware tokenization for future code LLMs.
Interactive Training: Feedback-Driven Neural Network Optimization
Oct 02, 2025Traditional neural network training typically follows fixed, predefined optimization recipes, lacking the flexibility to dynamically respond to instabilities or emerging training issues. In this paper, we introduce Interactive Training, an open-source framework that enables real-time, feedback-driven intervention during neural network training by human experts or automated AI agents. At its core, Interactive Training uses a control server to mediate communication between users or agents and the ongoing training process, allowing users to dynamically adjust optimizer hyperparameters, training data, and model checkpoints. Through three case studies, we demonstrate that Interactive Training achieves superior training stability, reduced sensitivity to initial hyperparameters, and improved adaptability to evolving user needs, paving the way toward a future training paradigm where AI agents autonomously monitor training logs, proactively resolve instabilities, and optimize training dynamics.
From Chat Logs to Collective Insights: Aggregative Question Answering
May 29, 2025Conversational agents powered by large language models (LLMs) are rapidly becoming integral to our daily interactions, generating unprecedented amounts of conversational data. Such datasets offer a powerful lens into societal interests, trending topics, and collective concerns. Yet, existing approaches typically treat these interactions as independent and miss critical insights that could emerge from aggregating and reasoning across large-scale conversation logs. In this paper, we introduce Aggregative Question Answering, a novel task requiring models to reason explicitly over thousands of user-chatbot interactions to answer aggregative queries, such as identifying emerging concerns among specific demographics. To enable research in this direction, we construct a benchmark, WildChat-AQA, comprising 6,027 aggregative questions derived from 182,330 real-world chatbot conversations. Experiments show that existing methods either struggle to reason effectively or incur prohibitive computational costs, underscoring the need for new approaches capable of extracting collective insights from large-scale conversational data.
Learn to Reason Efficiently with Adaptive Length-based Reward Shaping
May 21, 2025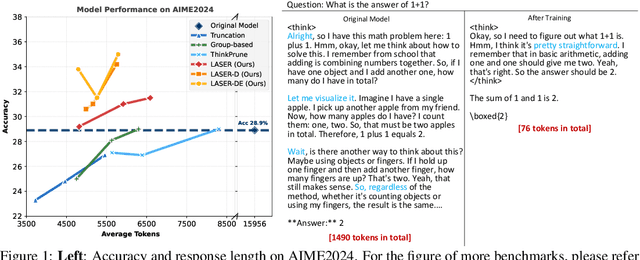
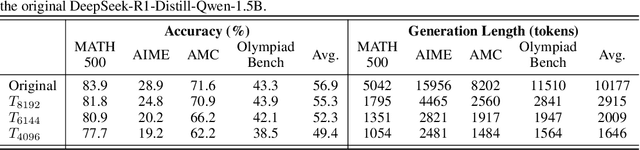
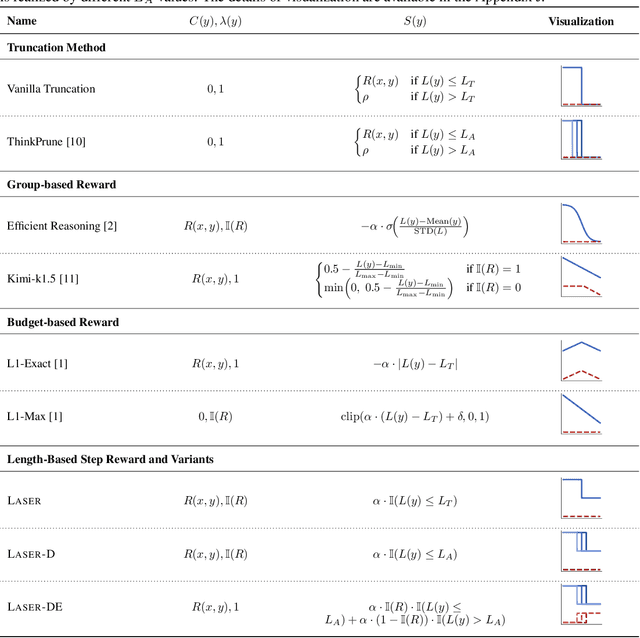
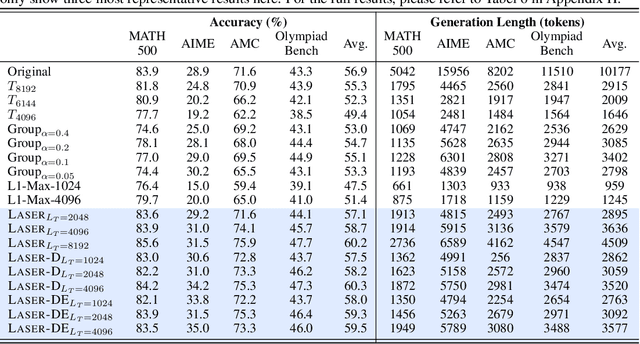
Large Reasoning Models (LRMs) have shown remarkable capabilities in solving complex problems through reinforcement learning (RL), particularly by generating long reasoning traces. However, these extended outputs often exhibit substantial redundancy, which limits the efficiency of LRMs. In this paper, we investigate RL-based approaches to promote reasoning efficiency. Specifically, we first present a unified framework that formulates various efficient reasoning methods through the lens of length-based reward shaping. Building on this perspective, we propose a novel Length-bAsed StEp Reward shaping method (LASER), which employs a step function as the reward, controlled by a target length. LASER surpasses previous methods, achieving a superior Pareto-optimal balance between performance and efficiency. Next, we further extend LASER based on two key intuitions: (1) The reasoning behavior of the model evolves during training, necessitating reward specifications that are also adaptive and dynamic; (2) Rather than uniformly encouraging shorter or longer chains of thought (CoT), we posit that length-based reward shaping should be difficulty-aware i.e., it should penalize lengthy CoTs more for easy queries. This approach is expected to facilitate a combination of fast and slow thinking, leading to a better overall tradeoff. The resulting method is termed LASER-D (Dynamic and Difficulty-aware). Experiments on DeepSeek-R1-Distill-Qwen-1.5B, DeepSeek-R1-Distill-Qwen-7B, and DeepSeek-R1-Distill-Qwen-32B show that our approach significantly enhances both reasoning performance and response length efficiency. For instance, LASER-D and its variant achieve a +6.1 improvement on AIME2024 while reducing token usage by 63%. Further analysis reveals our RL-based compression produces more concise reasoning patterns with less redundant "self-reflections". Resources are at https://github.com/hkust-nlp/Laser.
The Leaderboard Illusion
Apr 29, 2025Measuring progress is fundamental to the advancement of any scientific field. As benchmarks play an increasingly central role, they also grow more susceptible to distortion. Chatbot Arena has emerged as the go-to leaderboard for ranking the most capable AI systems. Yet, in this work we identify systematic issues that have resulted in a distorted playing field. We find that undisclosed private testing practices benefit a handful of providers who are able to test multiple variants before public release and retract scores if desired. We establish that the ability of these providers to choose the best score leads to biased Arena scores due to selective disclosure of performance results. At an extreme, we identify 27 private LLM variants tested by Meta in the lead-up to the Llama-4 release. We also establish that proprietary closed models are sampled at higher rates (number of battles) and have fewer models removed from the arena than open-weight and open-source alternatives. Both these policies lead to large data access asymmetries over time. Providers like Google and OpenAI have received an estimated 19.2% and 20.4% of all data on the arena, respectively. In contrast, a combined 83 open-weight models have only received an estimated 29.7% of the total data. We show that access to Chatbot Arena data yields substantial benefits; even limited additional data can result in relative performance gains of up to 112% on the arena distribution, based on our conservative estimates. Together, these dynamics result in overfitting to Arena-specific dynamics rather than general model quality. The Arena builds on the substantial efforts of both the organizers and an open community that maintains this valuable evaluation platform. We offer actionable recommendations to reform the Chatbot Arena's evaluation framework and promote fairer, more transparent benchmarking for the field
WildVis: Open Source Visualizer for Million-Scale Chat Logs in the Wild
Sep 05, 2024The increasing availability of real-world conversation data offers exciting opportunities for researchers to study user-chatbot interactions. However, the sheer volume of this data makes manually examining individual conversations impractical. To overcome this challenge, we introduce WildVis, an interactive tool that enables fast, versatile, and large-scale conversation analysis. WildVis provides search and visualization capabilities in the text and embedding spaces based on a list of criteria. To manage million-scale datasets, we implemented optimizations including search index construction, embedding precomputation and compression, and caching to ensure responsive user interactions within seconds. We demonstrate WildVis's utility through three case studies: facilitating chatbot misuse research, visualizing and comparing topic distributions across datasets, and characterizing user-specific conversation patterns. WildVis is open-source and designed to be extendable, supporting additional datasets and customized search and visualization functionalities.
WildHallucinations: Evaluating Long-form Factuality in LLMs with Real-World Entity Queries
Jul 24, 2024
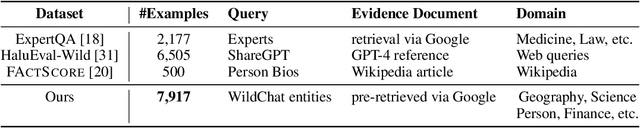
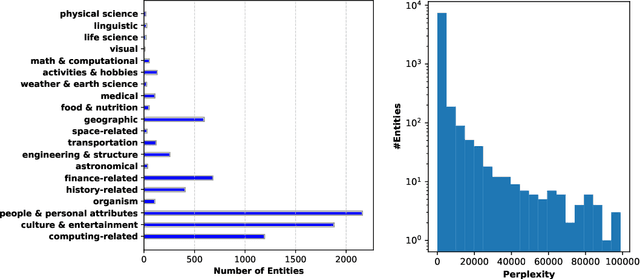
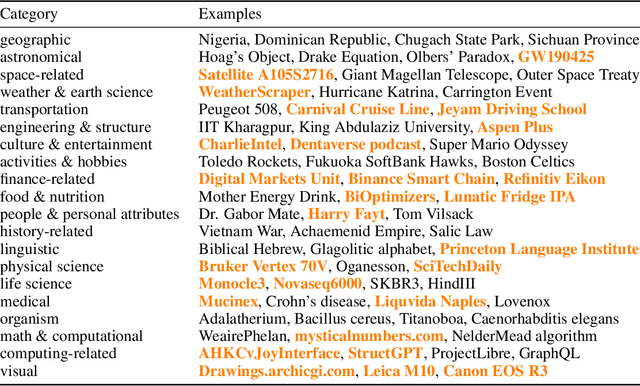
While hallucinations of large language models (LLMs) prevail as a major challenge, existing evaluation benchmarks on factuality do not cover the diverse domains of knowledge that the real-world users of LLMs seek information about. To bridge this gap, we introduce WildHallucinations, a benchmark that evaluates factuality. It does so by prompting LLMs to generate information about entities mined from user-chatbot conversations in the wild. These generations are then automatically fact-checked against a systematically curated knowledge source collected from web search. Notably, half of these real-world entities do not have associated Wikipedia pages. We evaluate 118,785 generations from 15 LLMs on 7,919 entities. We find that LLMs consistently hallucinate more on entities without Wikipedia pages and exhibit varying hallucination rates across different domains. Finally, given the same base models, adding a retrieval component only slightly reduces hallucinations but does not eliminate hallucinations.
Magpie: Alignment Data Synthesis from Scratch by Prompting Aligned LLMs with Nothing
Jun 12, 2024High-quality instruction data is critical for aligning large language models (LLMs). Although some models, such as Llama-3-Instruct, have open weights, their alignment data remain private, which hinders the democratization of AI. High human labor costs and a limited, predefined scope for prompting prevent existing open-source data creation methods from scaling effectively, potentially limiting the diversity and quality of public alignment datasets. Is it possible to synthesize high-quality instruction data at scale by extracting it directly from an aligned LLM? We present a self-synthesis method for generating large-scale alignment data named Magpie. Our key observation is that aligned LLMs like Llama-3-Instruct can generate a user query when we input only the left-side templates up to the position reserved for user messages, thanks to their auto-regressive nature. We use this method to prompt Llama-3-Instruct and generate 4 million instructions along with their corresponding responses. We perform a comprehensive analysis of the extracted data and select 300K high-quality instances. To compare Magpie data with other public instruction datasets, we fine-tune Llama-3-8B-Base with each dataset and evaluate the performance of the fine-tuned models. Our results indicate that in some tasks, models fine-tuned with Magpie perform comparably to the official Llama-3-8B-Instruct, despite the latter being enhanced with 10 million data points through supervised fine-tuning (SFT) and subsequent feedback learning. We also show that using Magpie solely for SFT can surpass the performance of previous public datasets utilized for both SFT and preference optimization, such as direct preference optimization with UltraFeedback. This advantage is evident on alignment benchmarks such as AlpacaEval, ArenaHard, and WildBench.
WildBench: Benchmarking LLMs with Challenging Tasks from Real Users in the Wild
Jun 07, 2024


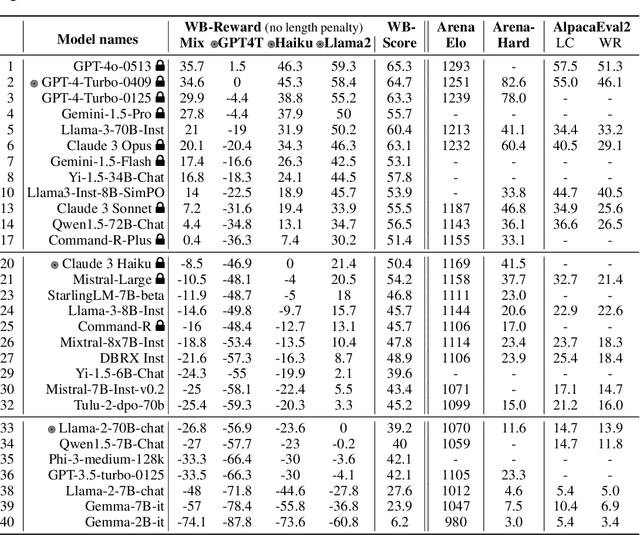
We introduce WildBench, an automated evaluation framework designed to benchmark large language models (LLMs) using challenging, real-world user queries. WildBench consists of 1,024 tasks carefully selected from over one million human-chatbot conversation logs. For automated evaluation with WildBench, we have developed two metrics, WB-Reward and WB-Score, which are computable using advanced LLMs such as GPT-4-turbo. WildBench evaluation uses task-specific checklists to evaluate model outputs systematically and provides structured explanations that justify the scores and comparisons, resulting in more reliable and interpretable automatic judgments. WB-Reward employs fine-grained pairwise comparisons between model responses, generating five potential outcomes: much better, slightly better, slightly worse, much worse, or a tie. Unlike previous evaluations that employed a single baseline model, we selected three baseline models at varying performance levels to ensure a comprehensive pairwise evaluation. Additionally, we propose a simple method to mitigate length bias, by converting outcomes of ``slightly better/worse'' to ``tie'' if the winner response exceeds the loser one by more than $K$ characters. WB-Score evaluates the quality of model outputs individually, making it a fast and cost-efficient evaluation metric. WildBench results demonstrate a strong correlation with the human-voted Elo ratings from Chatbot Arena on hard tasks. Specifically, WB-Reward achieves a Pearson correlation of 0.98 with top-ranking models. Additionally, WB-Score reaches 0.95, surpassing both ArenaHard's 0.91 and AlpacaEval2.0's 0.89 for length-controlled win rates, as well as the 0.87 for regular win rates.