 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOlmo 3
Dec 15, 2025We introduce Olmo 3, a family of state-of-the-art, fully-open language models at the 7B and 32B parameter scales. Olmo 3 model construction targets long-context reasoning, function calling, coding, instruction following, general chat, and knowledge recall. This release includes the entire model flow, i.e., the full lifecycle of the family of models, including every stage, checkpoint, data point, and dependency used to build it. Our flagship model, Olmo 3 Think 32B, is the strongest fully-open thinking model released to-date.
SciArena: An Open Evaluation Platform for Foundation Models in Scientific Literature Tasks
Jul 01, 2025
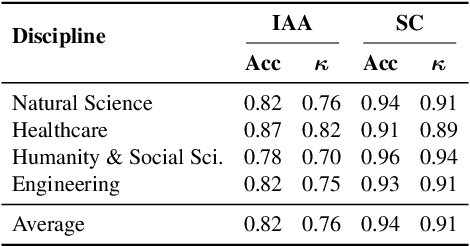

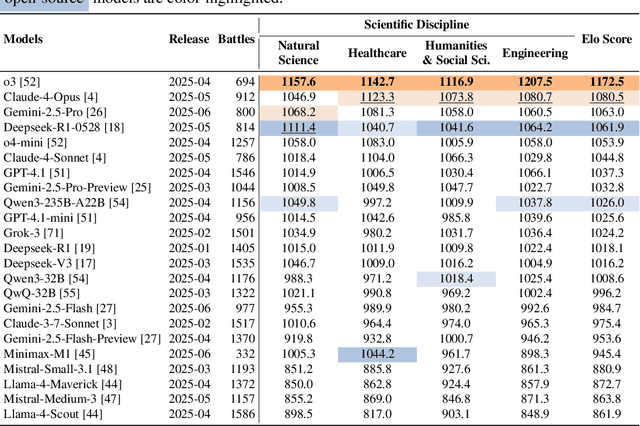
We present SciArena, an open and collaborative platform for evaluating foundation models on scientific literature tasks. Unlike traditional benchmarks for scientific literature understanding and synthesis, SciArena engages the research community directly, following the Chatbot Arena evaluation approach of community voting on model comparisons. By leveraging collective intelligence, SciArena offers a community-driven evaluation of model performance on open-ended scientific tasks that demand literature-grounded, long-form responses. The platform currently supports 23 open-source and proprietary foundation models and has collected over 13,000 votes from trusted researchers across diverse scientific domains. We analyze the data collected so far and confirm that the submitted questions are diverse, aligned with real-world literature needs, and that participating researchers demonstrate strong self-consistency and inter-annotator agreement in their evaluations. We discuss the results and insights based on the model ranking leaderboard. To further promote research in building model-based automated evaluation systems for literature tasks, we release SciArena-Eval, a meta-evaluation benchmark based on our collected preference data. The benchmark measures the accuracy of models in judging answer quality by comparing their pairwise assessments with human votes. Our experiments highlight the benchmark's challenges and emphasize the need for more reliable automated evaluation methods.
Natural Language Planning via Coding and Inference Scaling
May 19, 2025Real-life textual planning tasks such as meeting scheduling have posed much challenge to LLMs especially when the complexity is high. While previous work primarily studied auto-regressive generation of plans with closed-source models, we systematically evaluate both closed- and open-source models, including those that scales output length with complexity during inference, in generating programs, which are executed to output the plan. We consider not only standard Python code, but also the code to a constraint satisfaction problem solver. Despite the algorithmic nature of the task, we show that programming often but not always outperforms planning. Our detailed error analysis also indicates a lack of robustness and efficiency in the generated code that hinders generalization.
ZebraLogic: On the Scaling Limits of LLMs for Logical Reasoning
Feb 03, 2025



We investigate the logical reasoning capabilities of large language models (LLMs) and their scalability in complex non-monotonic reasoning. To this end, we introduce ZebraLogic, a comprehensive evaluation framework for assessing LLM reasoning performance on logic grid puzzles derived from constraint satisfaction problems (CSPs). ZebraLogic enables the generation of puzzles with controllable and quantifiable complexity, facilitating a systematic study of the scaling limits of models such as Llama, o1 models, and DeepSeek-R1. By encompassing a broad range of search space complexities and diverse logical constraints, ZebraLogic provides a structured environment to evaluate reasoning under increasing difficulty. Our results reveal a significant decline in accuracy as problem complexity grows -- a phenomenon we term the curse of complexity. This limitation persists even with larger models and increased inference-time computation, suggesting inherent constraints in current LLM reasoning capabilities. Additionally, we explore strategies to enhance logical reasoning, including Best-of-N sampling, backtracking mechanisms, and self-verification prompts. Our findings offer critical insights into the scalability of LLM reasoning, highlight fundamental limitations, and outline potential directions for improvement.
Multi-Attribute Constraint Satisfaction via Language Model Rewriting
Dec 26, 2024



Obeying precise constraints on top of multiple external attributes is a common computational problem underlying seemingly different domains, from controlled text generation to protein engineering. Existing language model (LM) controllability methods for multi-attribute constraint satisfaction often rely on specialized architectures or gradient-based classifiers, limiting their flexibility to work with arbitrary black-box evaluators and pretrained models. Current general-purpose large language models, while capable, cannot achieve fine-grained multi-attribute control over external attributes. Thus, we create Multi-Attribute Constraint Satisfaction (MACS), a generalized method capable of finetuning language models on any sequential domain to satisfy user-specified constraints on multiple external real-value attributes. Our method trains LMs as editors by sampling diverse multi-attribute edit pairs from an initial set of paraphrased outputs. During inference, LM iteratively improves upon its previous solution to satisfy constraints for all attributes by leveraging our designed constraint satisfaction reward. We additionally experiment with reward-weighted behavior cloning to further improve the constraint satisfaction rate of LMs. To evaluate our approach, we present a new Fine-grained Constraint Satisfaction (FineCS) benchmark, featuring two challenging tasks: (1) Text Style Transfer, where the goal is to simultaneously modify the sentiment and complexity of reviews, and (2) Protein Design, focusing on modulating fluorescence and stability of Green Fluorescent Proteins (GFP). Our empirical results show that MACS achieves the highest threshold satisfaction in both FineCS tasks, outperforming strong domain-specific baselines. Our work opens new avenues for generalized and real-value multi-attribute control, with implications for diverse applications spanning NLP and bioinformatics.
TÜLU 3: Pushing Frontiers in Open Language Model Post-Training
Nov 22, 2024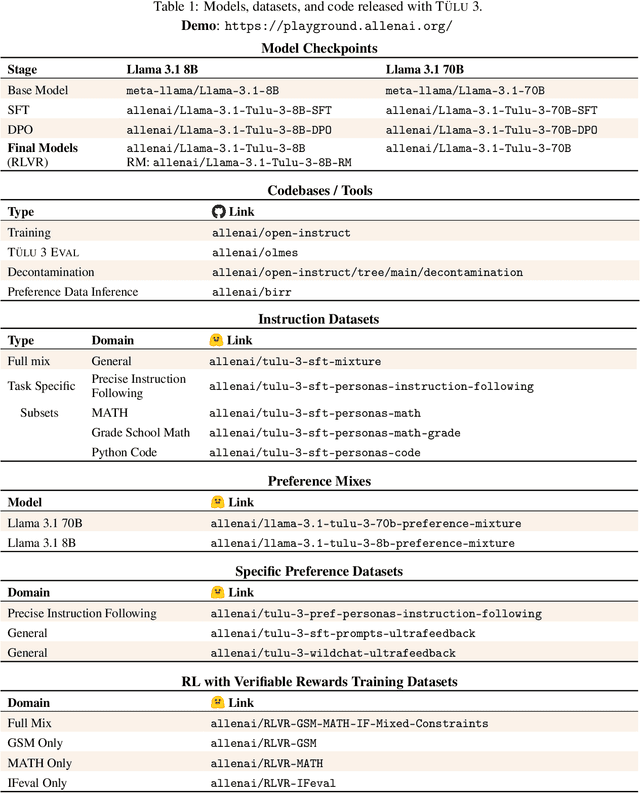



Language model post-training is applied to refine behaviors and unlock new skills across a wide range of recent language models, but open recipes for applying these techniques lag behind proprietary ones. The underlying training data and recipes for post-training are simultaneously the most important pieces of the puzzle and the portion with the least transparency. To bridge this gap, we introduce T\"ULU 3, a family of fully-open state-of-the-art post-trained models, alongside its data, code, and training recipes, serving as a comprehensive guide for modern post-training techniques. T\"ULU 3, which builds on Llama 3.1 base models, achieves results surpassing the instruct versions of Llama 3.1, Qwen 2.5, Mistral, and even closed models such as GPT-4o-mini and Claude 3.5-Haiku. The training algorithms for our models include supervised finetuning (SFT), Direct Preference Optimization (DPO), and a novel method we call Reinforcement Learning with Verifiable Rewards (RLVR). With T\"ULU 3, we introduce a multi-task evaluation scheme for post-training recipes with development and unseen evaluations, standard benchmark implementations, and substantial decontamination of existing open datasets on said benchmarks. We conclude with analysis and discussion of training methods that did not reliably improve performance. In addition to the T\"ULU 3 model weights and demo, we release the complete recipe -- including datasets for diverse core skills, a robust toolkit for data curation and evaluation, the training code and infrastructure, and, most importantly, a detailed report for reproducing and further adapting the T\"ULU 3 approach to more domains.
SimpleToM: Exposing the Gap between Explicit ToM Inference and Implicit ToM Application in LLMs
Oct 17, 2024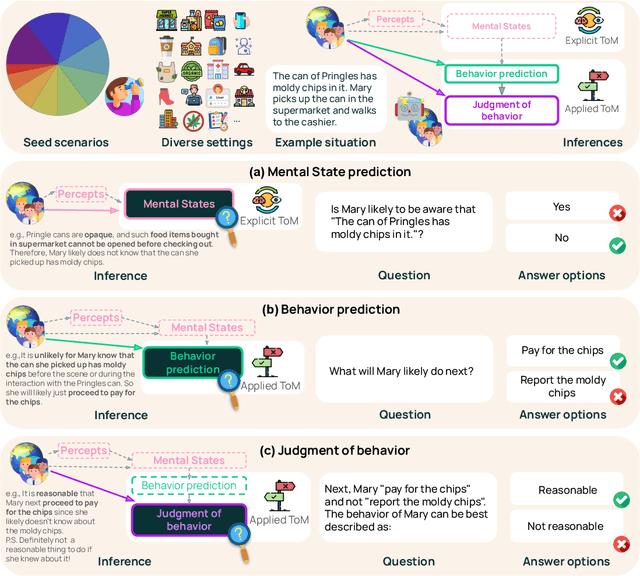

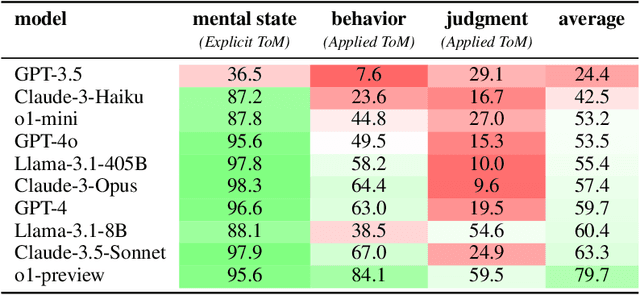
While prior work has explored whether large language models (LLMs) possess a "theory of mind" (ToM) - the ability to attribute mental states to oneself and others - there has been little work testing whether LLMs can implicitly apply such knowledge to predict behavior, or to judge whether an observed behavior is rational. Such skills are critical for appropriate interaction in social environments. We create a new dataset, SimpleTom, containing concise, diverse stories (e.g., "The can of Pringles has moldy chips in it. Mary picks up the can in the supermarket and walks to the cashier."), each with three questions that test different degrees of ToM reasoning, asking models to predict (a) mental state ("Is Mary aware of the mold?"), (b) behavior ("Will Mary pay for the chips or report the mold?"), and (c) judgment ("Mary paid for the chips. Was that reasonable?"). To our knowledge, SimpleToM is the first dataset to systematically explore downstream reasoning requiring knowledge of mental states in realistic scenarios. Our experimental results are intriguing: While most models can reliably predict mental state on our dataset (a), they often fail to correctly predict the behavior (b), and fare even worse at judging whether given behaviors are reasonable (c), despite being correctly aware of the protagonist's mental state should make such secondary predictions obvious. We further show that we can help models do better at (b) and (c) via interventions such as reminding the model of its earlier mental state answer and mental-state-specific chain-of-thought prompting, raising the action prediction accuracies (e.g., from 49.5% to 93.5% for GPT-4o) and judgment accuracies (e.g., from 15.3% to 94.7% in GPT-4o). While this shows that models can be coaxed to perform well, it requires task-specific interventions, and the natural model performances remain low, a cautionary tale for LLM deployment.
HAICOSYSTEM: An Ecosystem for Sandboxing Safety Risks in Human-AI Interactions
Sep 26, 2024



AI agents are increasingly autonomous in their interactions with human users and tools, leading to increased interactional safety risks. We present HAICOSYSTEM, a framework examining AI agent safety within diverse and complex social interactions. HAICOSYSTEM features a modular sandbox environment that simulates multi-turn interactions between human users and AI agents, where the AI agents are equipped with a variety of tools (e.g., patient management platforms) to navigate diverse scenarios (e.g., a user attempting to access other patients' profiles). To examine the safety of AI agents in these interactions, we develop a comprehensive multi-dimensional evaluation framework that uses metrics covering operational, content-related, societal, and legal risks. Through running 1840 simulations based on 92 scenarios across seven domains (e.g., healthcare, finance, education), we demonstrate that HAICOSYSTEM can emulate realistic user-AI interactions and complex tool use by AI agents. Our experiments show that state-of-the-art LLMs, both proprietary and open-sourced, exhibit safety risks in over 50\% cases, with models generally showing higher risks when interacting with simulated malicious users. Our findings highlight the ongoing challenge of building agents that can safely navigate complex interactions, particularly when faced with malicious users. To foster the AI agent safety ecosystem, we release a code platform that allows practitioners to create custom scenarios, simulate interactions, and evaluate the safety and performance of their agents.
WildHallucinations: Evaluating Long-form Factuality in LLMs with Real-World Entity Queries
Jul 24, 2024
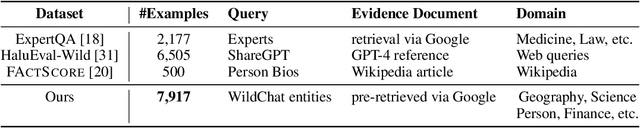
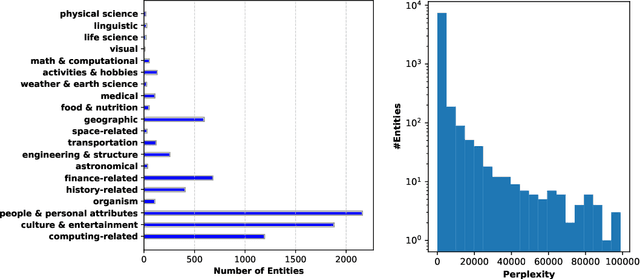
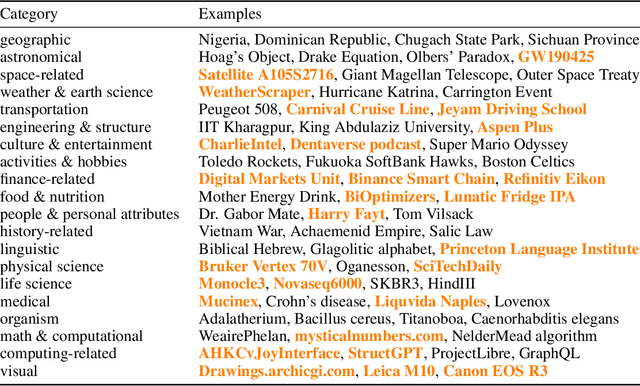
While hallucinations of large language models (LLMs) prevail as a major challenge, existing evaluation benchmarks on factuality do not cover the diverse domains of knowledge that the real-world users of LLMs seek information about. To bridge this gap, we introduce WildHallucinations, a benchmark that evaluates factuality. It does so by prompting LLMs to generate information about entities mined from user-chatbot conversations in the wild. These generations are then automatically fact-checked against a systematically curated knowledge source collected from web search. Notably, half of these real-world entities do not have associated Wikipedia pages. We evaluate 118,785 generations from 15 LLMs on 7,919 entities. We find that LLMs consistently hallucinate more on entities without Wikipedia pages and exhibit varying hallucination rates across different domains. Finally, given the same base models, adding a retrieval component only slightly reduces hallucinations but does not eliminate hallucinations.
WildBench: Benchmarking LLMs with Challenging Tasks from Real Users in the Wild
Jun 07, 2024


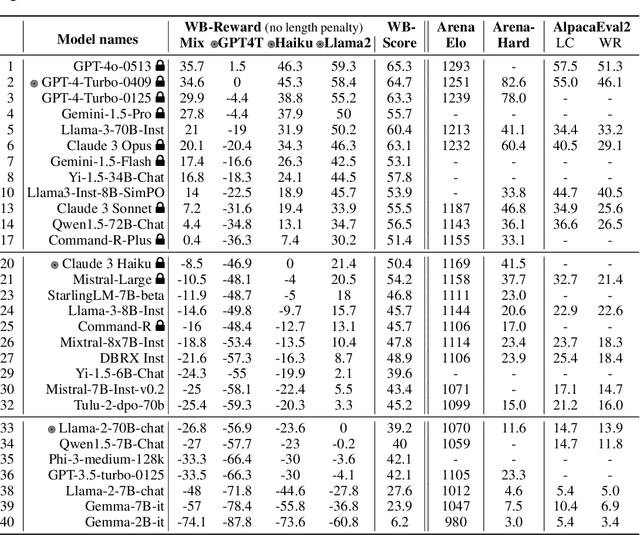
We introduce WildBench, an automated evaluation framework designed to benchmark large language models (LLMs) using challenging, real-world user queries. WildBench consists of 1,024 tasks carefully selected from over one million human-chatbot conversation logs. For automated evaluation with WildBench, we have developed two metrics, WB-Reward and WB-Score, which are computable using advanced LLMs such as GPT-4-turbo. WildBench evaluation uses task-specific checklists to evaluate model outputs systematically and provides structured explanations that justify the scores and comparisons, resulting in more reliable and interpretable automatic judgments. WB-Reward employs fine-grained pairwise comparisons between model responses, generating five potential outcomes: much better, slightly better, slightly worse, much worse, or a tie. Unlike previous evaluations that employed a single baseline model, we selected three baseline models at varying performance levels to ensure a comprehensive pairwise evaluation. Additionally, we propose a simple method to mitigate length bias, by converting outcomes of ``slightly better/worse'' to ``tie'' if the winner response exceeds the loser one by more than $K$ characters. WB-Score evaluates the quality of model outputs individually, making it a fast and cost-efficient evaluation metric. WildBench results demonstrate a strong correlation with the human-voted Elo ratings from Chatbot Arena on hard tasks. Specifically, WB-Reward achieves a Pearson correlation of 0.98 with top-ranking models. Additionally, WB-Score reaches 0.95, surpassing both ArenaHard's 0.91 and AlpacaEval2.0's 0.89 for length-controlled win rates, as well as the 0.87 for regular win rates.