 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Attribute Constraint Satisfaction via Language Model Rewriting
Dec 26, 2024



Obeying precise constraints on top of multiple external attributes is a common computational problem underlying seemingly different domains, from controlled text generation to protein engineering. Existing language model (LM) controllability methods for multi-attribute constraint satisfaction often rely on specialized architectures or gradient-based classifiers, limiting their flexibility to work with arbitrary black-box evaluators and pretrained models. Current general-purpose large language models, while capable, cannot achieve fine-grained multi-attribute control over external attributes. Thus, we create Multi-Attribute Constraint Satisfaction (MACS), a generalized method capable of finetuning language models on any sequential domain to satisfy user-specified constraints on multiple external real-value attributes. Our method trains LMs as editors by sampling diverse multi-attribute edit pairs from an initial set of paraphrased outputs. During inference, LM iteratively improves upon its previous solution to satisfy constraints for all attributes by leveraging our designed constraint satisfaction reward. We additionally experiment with reward-weighted behavior cloning to further improve the constraint satisfaction rate of LMs. To evaluate our approach, we present a new Fine-grained Constraint Satisfaction (FineCS) benchmark, featuring two challenging tasks: (1) Text Style Transfer, where the goal is to simultaneously modify the sentiment and complexity of reviews, and (2) Protein Design, focusing on modulating fluorescence and stability of Green Fluorescent Proteins (GFP). Our empirical results show that MACS achieves the highest threshold satisfaction in both FineCS tasks, outperforming strong domain-specific baselines. Our work opens new avenues for generalized and real-value multi-attribute control, with implications for diverse applications spanning NLP and bioinformatics.
NovaCOMET: Open Commonsense Foundation Models with Symbolic Knowledge Distillation
Dec 10, 2023


We present NovaCOMET, an open commonsense knowledge model, that combines the best aspects of knowledge and general task models. Compared to previous knowledge models, NovaCOMET allows open-format relations enabling direct application to reasoning tasks; compared to general task models like Flan-T5, it explicitly centers knowledge, enabling superior performance for commonsense reasoning. NovaCOMET leverages the knowledge of opaque proprietary models to create an open knowledge pipeline. First, knowledge is symbolically distilled into NovATOMIC, a publicly-released discrete knowledge graph which can be audited, critiqued, and filtered. Next, we train NovaCOMET on NovATOMIC by fine-tuning an open-source pretrained model. NovaCOMET uses an open-format training objective, replacing the fixed relation sets of past knowledge models, enabling arbitrary structures within the data to serve as inputs or outputs. The resulting generation model, optionally augmented with human annotation, matches or exceeds comparable open task models like Flan-T5 on a range of commonsense generation tasks. NovaCOMET serves as a counterexample to the contemporary focus on instruction tuning only, demonstrating a distinct advantage to explicitly modeling commonsense knowledge as well.
Improving Language Models with Advantage-based Offline Policy Gradients
May 24, 2023



Improving language model generations according to some user-defined quality or style constraints is challenging. Typical approaches include learning on additional human-written data, filtering ``low-quality'' data using heuristics and/or using reinforcement learning with human feedback (RLHF). However, filtering can remove valuable training signals, whereas data collection and RLHF constantly require additional human-written or LM exploration data which can be costly to obtain. A natural question to ask is ``Can we leverage RL to optimize LM utility on existing crowd-sourced and internet data?'' To this end, we present Left-over Lunch RL (LoL-RL), a simple training algorithm that uses offline policy gradients for learning language generation tasks as a 1-step RL game. LoL-RL can finetune LMs to optimize arbitrary classifier-based or human-defined utility functions on any sequence-to-sequence data. Experiments with five different language generation tasks using models of varying sizes and multiple rewards show that models trained with LoL-RL can consistently outperform the best supervised learning models. We also release our experimental code. https://github.com/abaheti95/LoL-RL
Stanceosaurus: Classifying Stance Towards Multilingual Misinformation
Oct 28, 2022



We present Stanceosaurus, a new corpus of 28,033 tweets in English, Hindi, and Arabic annotated with stance towards 251 misinformation claims. As far as we are aware, it is the largest corpus annotated with stance towards misinformation claims. The claims in Stanceosaurus originate from 15 fact-checking sources that cover diverse geographical regions and cultures. Unlike existing stance datasets, we introduce a more fine-grained 5-class labeling strategy with additional subcategories to distinguish implicit stance. Pre-trained transformer-based stance classifiers that are fine-tuned on our corpus show good generalization on unseen claims and regional claims from countries outside the training data. Cross-lingual experiments demonstrate Stanceosaurus' capability of training multi-lingual models, achieving 53.1 F1 on Hindi and 50.4 F1 on Arabic without any target-language fine-tuning. Finally, we show how a domain adaptation method can be used to improve performance on Stanceosaurus using additional RumourEval-2019 data. We make Stanceosaurus publicly available to the research community and hope it will encourage further work on misinformation identification across languages and cultures.
Just Say No: Analyzing the Stance of Neural Dialogue Generation in Offensive Contexts
Aug 26, 2021
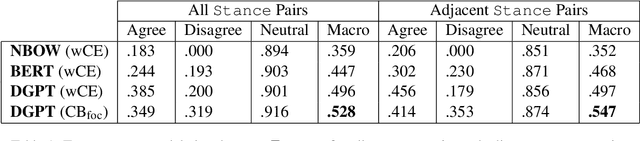

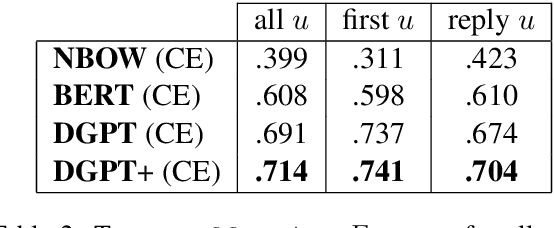
Dialogue models trained on human conversations inadvertently learn to generate offensive responses. Moreover, models can insult anyone by agreeing with an offensive context. To understand the dynamics of contextually offensive language, we study the stance of dialogue model responses in offensive Reddit conversations. Specifically, we crowd-annotate ToxiChat, a new dataset of 2,000 Reddit threads and model responses labeled with offensive language and stance. Our analysis reveals that 42% of user responses agree with toxic comments; 3x their agreement with safe comments (13%). Pre-trained transformer-based classifiers fine-tuned on our dataset achieve 0.71 F1 for offensive labels and 0.53 Macro-F1 for stance labels. Finally, we analyze some existing controllable text generation (CTG) methods to mitigate the contextual offensive behavior of dialogue models. Compared to the baseline, our best CTG model obtains a 19% reduction in agreement with offensive context and 29% fewer offensive responses. This highlights the need for future work to characterize and analyze more forms of inappropriate behavior in dialogue models to help make them safer. Our code and corpus are available at https://github.com/abaheti95/ToxiChat .
Extracting COVID-19 Events from Twitter
Jun 24, 2020
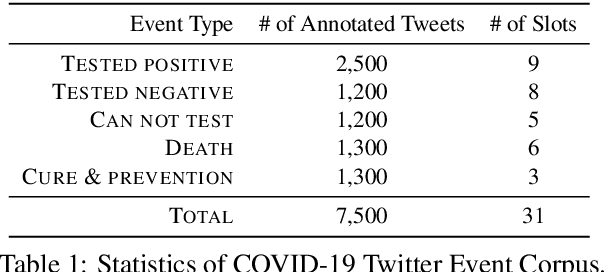

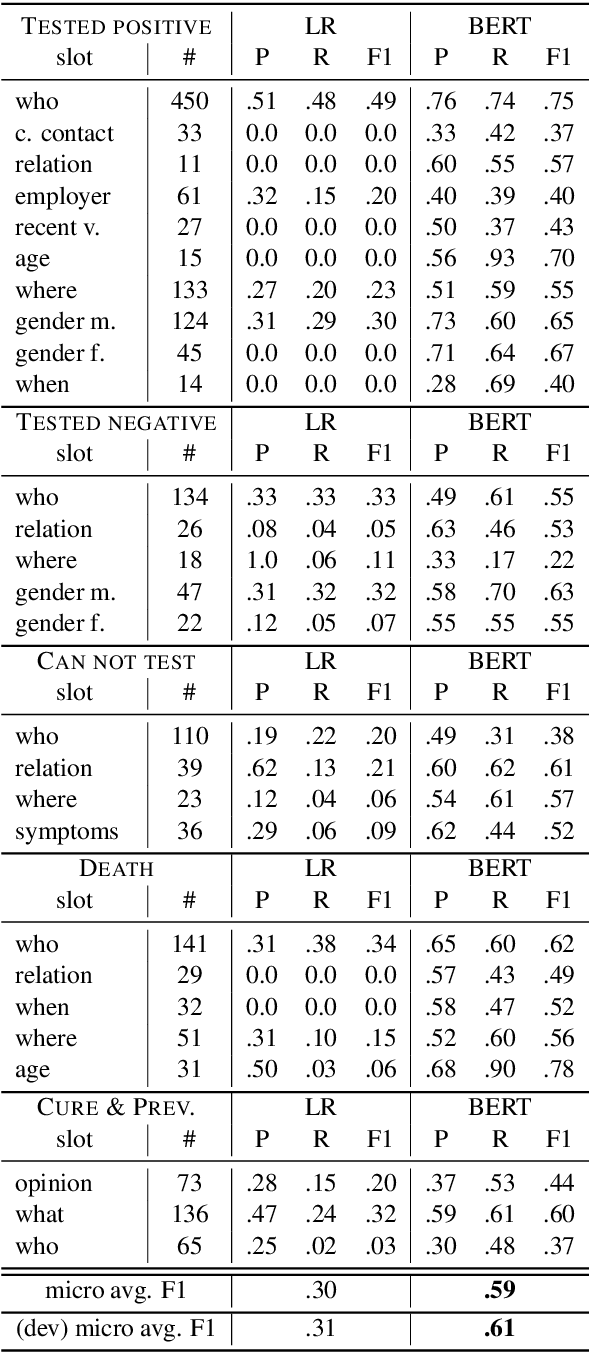
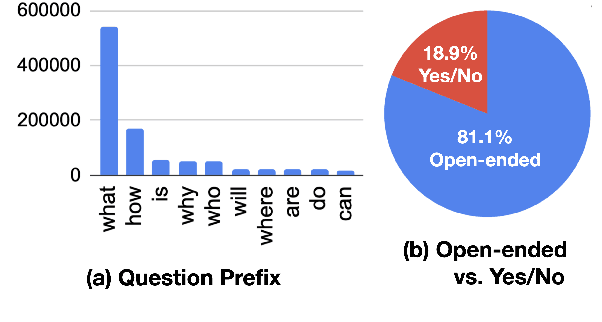
We present a corpus of 7,500 tweets annotated with COVID-19 events, including positive test results, denied access to testing, and more. We show that our corpus enables automatic identification of COVID-19 events mentioned in Twitter with text spans that fill a set of pre-defined slots for each event. We also present analyses on the self-reporting cases and user's demographic information. We will make our annotated corpus and extraction tools available for the research community to use upon publication at https://github.com/viczong/extract_COVID19_events_from_Twitter
Fluent Response Generation for Conversational Question Answering
May 21, 2020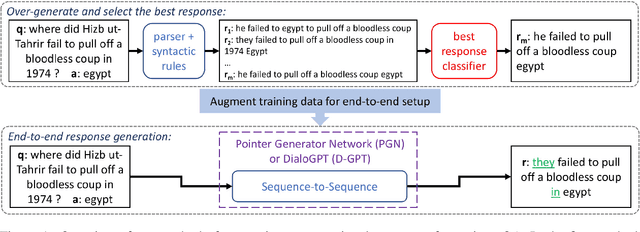

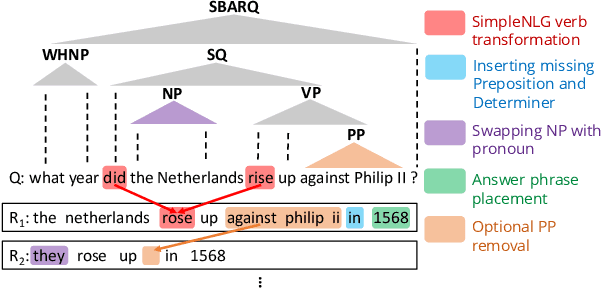
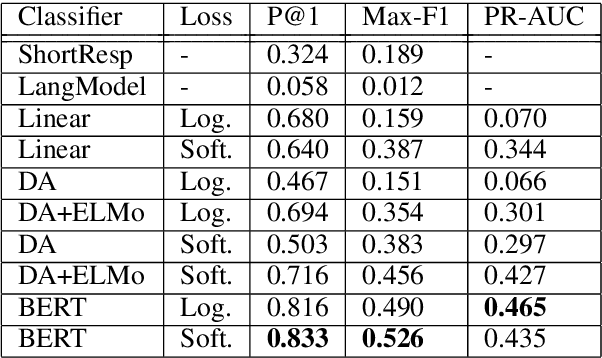
Question answering (QA) is an important aspect of open-domain conversational agents, garnering specific research focus in the conversational QA (ConvQA) subtask. One notable limitation of recent ConvQA efforts is the response being answer span extraction from the target corpus, thus ignoring the natural language generation (NLG) aspect of high-quality conversational agents. In this work, we propose a method for situating QA responses within a SEQ2SEQ NLG approach to generate fluent grammatical answer responses while maintaining correctness. From a technical perspective, we use data augmentation to generate training data for an end-to-end system. Specifically, we develop Syntactic Transformations (STs) to produce question-specific candidate answer responses and rank them using a BERT-based classifier (Devlin et al., 2019). Human evaluation on SQuAD 2.0 data (Rajpurkar et al., 2018) demonstrate that the proposed model outperforms baseline CoQA and QuAC models in generating conversational responses. We further show our model's scalability by conducting tests on the CoQA dataset. The code and data are available at https://github.com/abaheti95/QADialogSystem.
Generating More Interesting Responses in Neural Conversation Models with Distributional Constraints
Sep 04, 2018
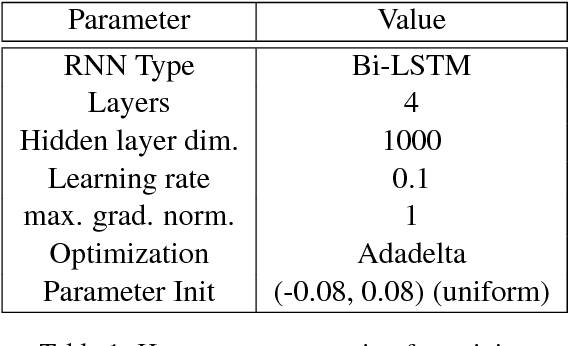


Neural conversation models tend to generate safe, generic responses for most inputs. This is due to the limitations of likelihood-based decoding objectives in generation tasks with diverse outputs, such as conversation. To address this challenge, we propose a simple yet effective approach for incorporating side information in the form of distributional constraints over the generated responses. We propose two constraints that help generate more content rich responses that are based on a model of syntax and topics (Griffiths et al., 2005) and semantic similarity (Arora et al., 2016). We evaluate our approach against a variety of competitive baselines, using both automatic metrics and human judgments, showing that our proposed approach generates responses that are much less generic without sacrificing plausibility. A working demo of our code can be found at https://github.com/abaheti95/DC-NeuralConversation.