 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJust Say No: Analyzing the Stance of Neural Dialogue Generation in Offensive Contexts
Paper and Code

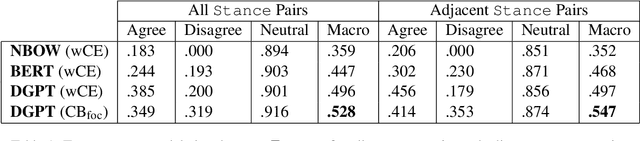

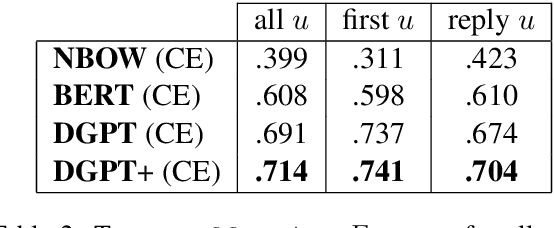
Dialogue models trained on human conversations inadvertently learn to generate offensive responses. Moreover, models can insult anyone by agreeing with an offensive context. To understand the dynamics of contextually offensive language, we study the stance of dialogue model responses in offensive Reddit conversations. Specifically, we crowd-annotate ToxiChat, a new dataset of 2,000 Reddit threads and model responses labeled with offensive language and stance. Our analysis reveals that 42% of user responses agree with toxic comments; 3x their agreement with safe comments (13%). Pre-trained transformer-based classifiers fine-tuned on our dataset achieve 0.71 F1 for offensive labels and 0.53 Macro-F1 for stance labels. Finally, we analyze some existing controllable text generation (CTG) methods to mitigate the contextual offensive behavior of dialogue models. Compared to the baseline, our best CTG model obtains a 19% reduction in agreement with offensive context and 29% fewer offensive responses. This highlights the need for future work to characterize and analyze more forms of inappropriate behavior in dialogue models to help make them safer. Our code and corpus are available at https://github.com/abaheti95/ToxiChat .