 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating the Utility of Grounding Documents with Reference-Free LLM-based Metrics
Jan 30, 2026Retrieval Augmented Generation (RAG)'s success depends on the utility the LLM derives from the content used for grounding. Quantifying content utility does not have a definitive specification and existing metrics ignore model-specific capabilities and/or rely on costly annotations. In this paper, we propose Grounding Generation Utility (GroGU), a model-specific and reference-free metric that defines utility as a function of the downstream LLM's generation confidence based on entropy. Despite having no annotation requirements, GroGU is largely faithful in distinguishing ground-truth documents while capturing nuances ignored by LLM-agnostic metrics. We apply GroGU to train a query-rewriter for RAG by identifying high-utility preference data for Direct Preference Optimization. Experiments show improvements by up to 18.2 points in Mean Reciprocal Rank and up to 9.4 points in answer accuracy.
Towards Better Generalization in Open-Domain Question Answering by Mitigating Context Memorization
Apr 02, 2024



Open-domain Question Answering (OpenQA) aims at answering factual questions with an external large-scale knowledge corpus. However, real-world knowledge is not static; it updates and evolves continually. Such a dynamic characteristic of knowledge poses a vital challenge for these models, as the trained models need to constantly adapt to the latest information to make sure that the answers remain accurate. In addition, it is still unclear how well an OpenQA model can transfer to completely new knowledge domains. In this paper, we investigate the generalization performance of a retrieval-augmented QA model in two specific scenarios: 1) adapting to updated versions of the same knowledge corpus; 2) switching to completely different knowledge domains. We observe that the generalization challenges of OpenQA models stem from the reader's over-reliance on memorizing the knowledge from the external corpus, which hinders the model from generalizing to a new knowledge corpus. We introduce Corpus-Invariant Tuning (CIT), a simple but effective training strategy, to mitigate the knowledge over-memorization by controlling the likelihood of retrieved contexts during training. Extensive experimental results on multiple OpenQA benchmarks show that CIT achieves significantly better generalizability without compromising the model's performance in its original corpus and domain.
Background Summarization of Event Timelines
Oct 24, 2023Generating concise summaries of news events is a challenging natural language processing task. While journalists often curate timelines to highlight key sub-events, newcomers to a news event face challenges in catching up on its historical context. In this paper, we address this need by introducing the task of background news summarization, which complements each timeline update with a background summary of relevant preceding events. We construct a dataset by merging existing timeline datasets and asking human annotators to write a background summary for each timestep of each news event. We establish strong baseline performance using state-of-the-art summarization systems and propose a query-focused variant to generate background summaries. To evaluate background summary quality, we present a question-answering-based evaluation metric, Background Utility Score (BUS), which measures the percentage of questions about a current event timestep that a background summary answers. Our experiments show the effectiveness of instruction fine-tuned systems such as Flan-T5, in addition to strong zero-shot performance using GPT-3.5.
SumREN: Summarizing Reported Speech about Events in News
Dec 02, 2022



A primary objective of news articles is to establish the factual record for an event, frequently achieved by conveying both the details of the specified event (i.e., the 5 Ws; Who, What, Where, When and Why regarding the event) and how people reacted to it (i.e., reported statements). However, existing work on news summarization almost exclusively focuses on the event details. In this work, we propose the novel task of summarizing the reactions of different speakers, as expressed by their reported statements, to a given event. To this end, we create a new multi-document summarization benchmark, SUMREN, comprising 745 summaries of reported statements from various public figures obtained from 633 news articles discussing 132 events. We propose an automatic silver training data generation approach for our task, which helps smaller models like BART achieve GPT-3 level performance on this task. Finally, we introduce a pipeline-based framework for summarizing reported speech, which we empirically show to generate summaries that are more abstractive and factual than baseline query-focused summarization approaches.
PLAtE: A Large-scale Dataset for List Page Web Extraction
May 24, 2022
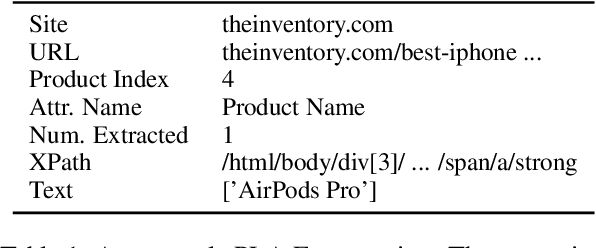

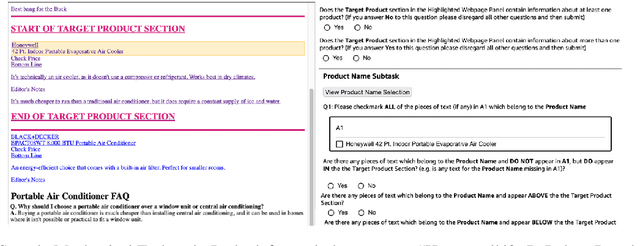
Recently, neural models have been leveraged to significantly improve the performance of information extraction from semi-structured websites. However, a barrier for continued progress is the small number of datasets large enough to train these models. In this work, we introduce the PLAtE (Pages of Lists Attribute Extraction) dataset as a challenging new web extraction task. PLAtE focuses on shopping data, specifically extractions from product review pages with multiple items. PLAtE encompasses both the tasks of: (1) finding product-list segmentation boundaries and (2) extracting attributes for each product. PLAtE is composed of 53, 905 items from 6, 810 pages, making it the first large-scale list page web extraction dataset. We construct PLAtE by collecting list pages from Common Crawl, then annotating them on Mechanical Turk. Quantitative and qualitative analyses are performed to demonstrate PLAtE has high-quality annotations. We establish strong baseline performance on PLAtE with a SOTA model achieving an F1-score of 0.750 for attribute classification and 0.915 for segmentation, indicating opportunities for future research innovations in web extraction.
Answer Consolidation: Formulation and Benchmarking
Apr 29, 2022

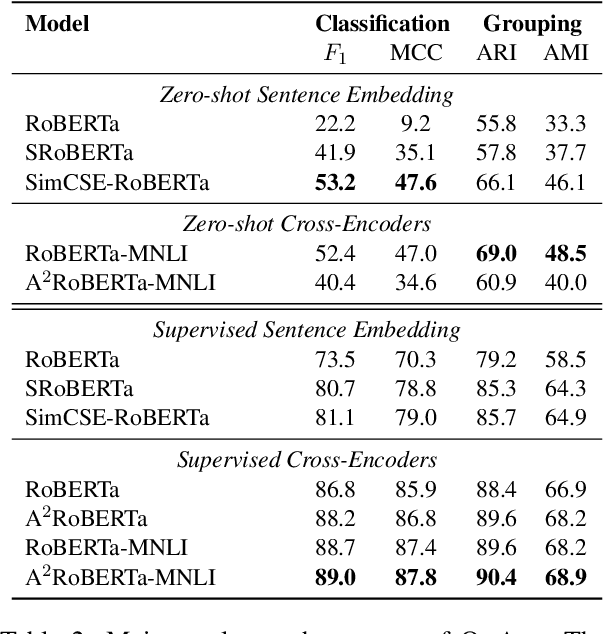
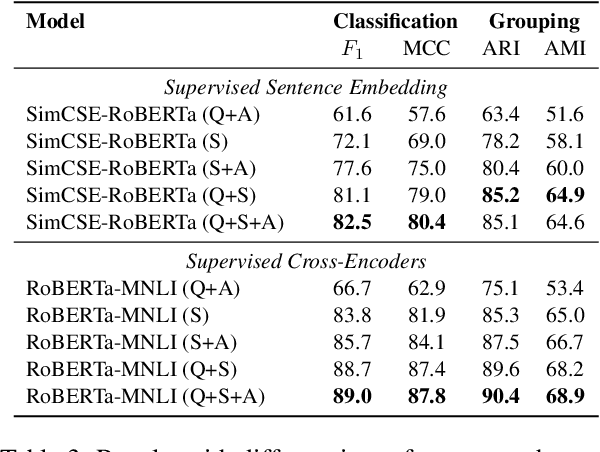
Current question answering (QA) systems primarily consider the single-answer scenario, where each question is assumed to be paired with one correct answer. However, in many real-world QA applications, multiple answer scenarios arise where consolidating answers into a comprehensive and non-redundant set of answers is a more efficient user interface. In this paper, we formulate the problem of answer consolidation, where answers are partitioned into multiple groups, each representing different aspects of the answer set. Then, given this partitioning, a comprehensive and non-redundant set of answers can be constructed by picking one answer from each group. To initiate research on answer consolidation, we construct a dataset consisting of 4,699 questions and 24,006 sentences and evaluate multiple models. Despite a promising performance achieved by the best-performing supervised models, we still believe this task has room for further improvements.
Generating Self-Contained and Summary-Centric Question Answer Pairs via Differentiable Reward Imitation Learning
Sep 10, 2021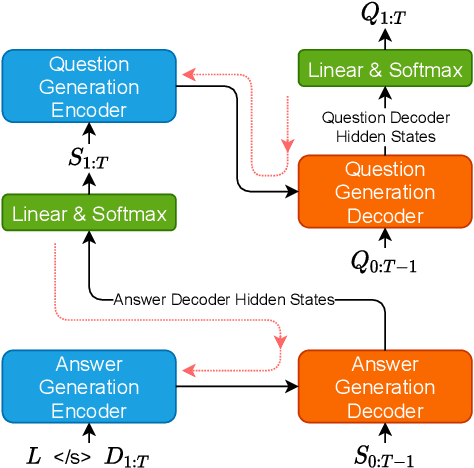
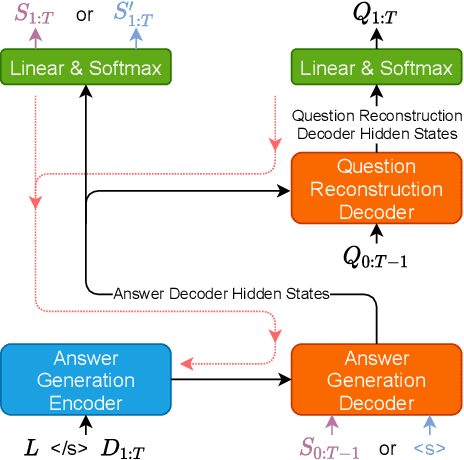
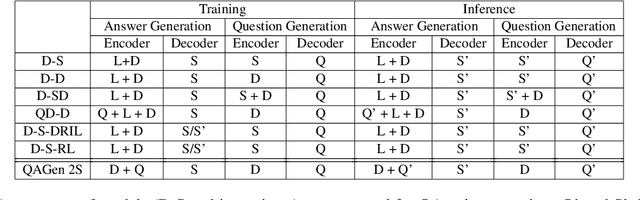
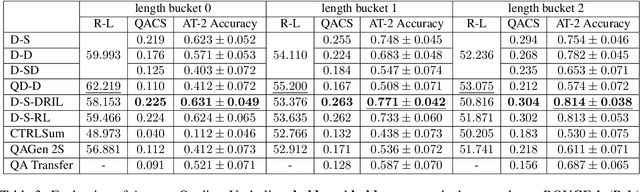
Motivated by suggested question generation in conversational news recommendation systems, we propose a model for generating question-answer pairs (QA pairs) with self-contained, summary-centric questions and length-constrained, article-summarizing answers. We begin by collecting a new dataset of news articles with questions as titles and pairing them with summaries of varying length. This dataset is used to learn a QA pair generation model producing summaries as answers that balance brevity with sufficiency jointly with their corresponding questions. We then reinforce the QA pair generation process with a differentiable reward function to mitigate exposure bias, a common problem in natural language generation. Both automatic metrics and human evaluation demonstrate these QA pairs successfully capture the central gists of the articles and achieve high answer accuracy.
Question Generation for Supporting Informational Query Intents
Oct 19, 2020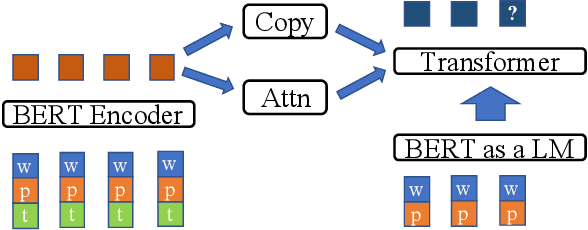

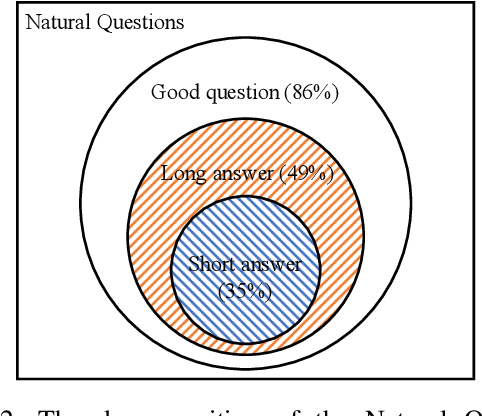

Users frequently ask simple factoid questions when encountering question answering (QA) systems, attenuating the impact of myriad recent works designed to support more complex questions. Prompting users with automatically generated suggested questions (SQs) can improve understanding of QA system capabilities and thus facilitate using this technology more effectively. While question generation (QG) is a well-established problem, existing methods are not targeted at producing SQ guidance for human users seeking more in-depth information about a specific concept. In particular, existing QG works are insufficient for this task as the generated questions frequently (1) require access to supporting documents as comprehension context (e.g., How many points did LeBron score?) and (2) focus on short answer spans, often producing peripheral factoid questions unlikely to attract interest. In this work, we aim to generate self-explanatory questions that focus on the main document topics and are answerable with variable length passages as appropriate. We satisfy these requirements by using a BERT-based Pointer-Generator Network (BertPGN) trained on the Natural Questions (NQ) dataset. First, we show that the BertPGN model produces state-of-the-art QG performance for long and short answers for in-domain NQ (BLEU-4 for 20.13 and 28.09, respectively). Secondly, we evaluate this QG model on the out-of-domain NewsQA dataset automatically and with human evaluation, demonstrating that our method produces better SQs for news articles, even those from a different domain than the training data.
Inverse Reinforcement Learning with Natural Language Goals
Aug 22, 2020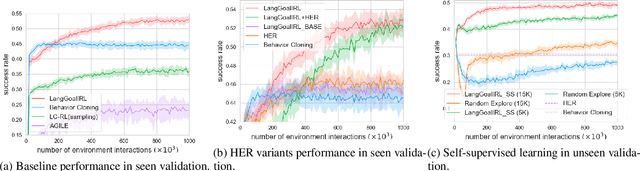
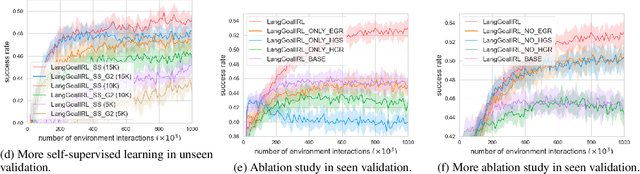


Humans generally use natural language to communicate task requirements amongst each other. It is desirable that this would be similar for autonomous machines (e.g. robots) such that humans can convey goals or assign tasks more easily. However, understanding natural language goals and mapping them to sequences of states and actions is challenging. Previous research has encountered difficulty generalizing learned policies to new natural language goals and environments. In this paper, we propose an adversarial inverse reinforcement learning algorithm that learns a language-conditioned policy and reward function. To improve the generalization of the learned policy and reward function, we use a variational goal generator that relabels trajectories and samples diverse goals during training. Our algorithm outperforms baselines by a large margin on a vision-based natural language instruction following dataset, demonstrating a promising advance in providing natural language instructions to agents without reliance on instruction templates.
Fluent Response Generation for Conversational Question Answering
May 21, 2020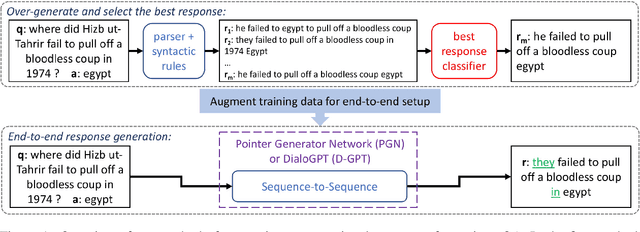

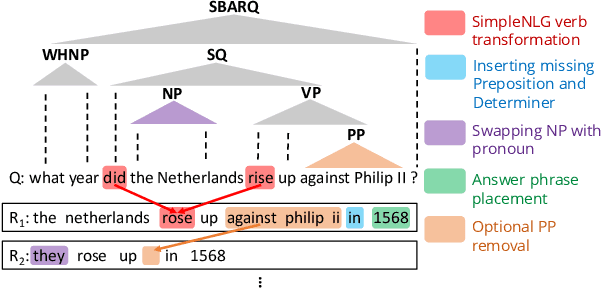
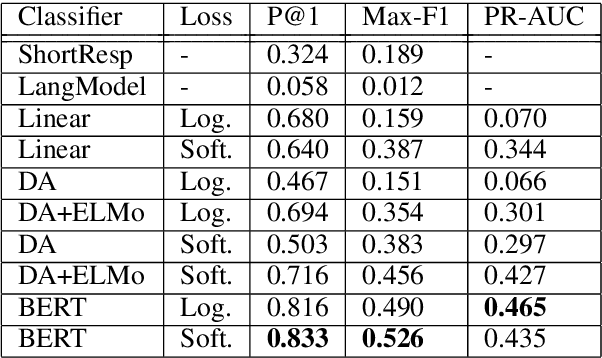
Question answering (QA) is an important aspect of open-domain conversational agents, garnering specific research focus in the conversational QA (ConvQA) subtask. One notable limitation of recent ConvQA efforts is the response being answer span extraction from the target corpus, thus ignoring the natural language generation (NLG) aspect of high-quality conversational agents. In this work, we propose a method for situating QA responses within a SEQ2SEQ NLG approach to generate fluent grammatical answer responses while maintaining correctness. From a technical perspective, we use data augmentation to generate training data for an end-to-end system. Specifically, we develop Syntactic Transformations (STs) to produce question-specific candidate answer responses and rank them using a BERT-based classifier (Devlin et al., 2019). Human evaluation on SQuAD 2.0 data (Rajpurkar et al., 2018) demonstrate that the proposed model outperforms baseline CoQA and QuAC models in generating conversational responses. We further show our model's scalability by conducting tests on the CoQA dataset. The code and data are available at https://github.com/abaheti95/QADialogSystem.