 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInverse Reinforcement Learning with Natural Language Goals
Paper and Code
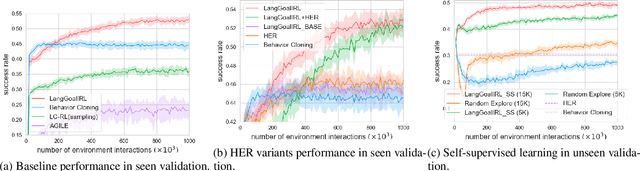
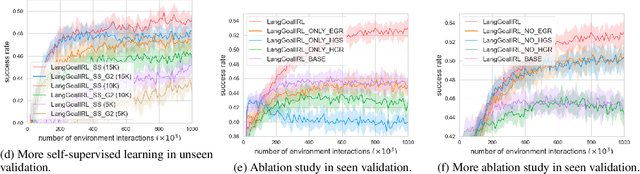


Humans generally use natural language to communicate task requirements amongst each other. It is desirable that this would be similar for autonomous machines (e.g. robots) such that humans can convey goals or assign tasks more easily. However, understanding natural language goals and mapping them to sequences of states and actions is challenging. Previous research has encountered difficulty generalizing learned policies to new natural language goals and environments. In this paper, we propose an adversarial inverse reinforcement learning algorithm that learns a language-conditioned policy and reward function. To improve the generalization of the learned policy and reward function, we use a variational goal generator that relabels trajectories and samples diverse goals during training. Our algorithm outperforms baselines by a large margin on a vision-based natural language instruction following dataset, demonstrating a promising advance in providing natural language instructions to agents without reliance on instruction templates.