 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSoftQE: Learned Representations of Queries Expanded by LLMs
Feb 20, 2024



We investigate the integration of Large Language Models (LLMs) into query encoders to improve dense retrieval without increasing latency and cost, by circumventing the dependency on LLMs at inference time. SoftQE incorporates knowledge from LLMs by mapping embeddings of input queries to those of the LLM-expanded queries. While improvements over various strong baselines on in-domain MS-MARCO metrics are marginal, SoftQE improves performance by 2.83 absolute percentage points on average on five out-of-domain BEIR tasks.
Question Generation for Supporting Informational Query Intents
Oct 19, 2020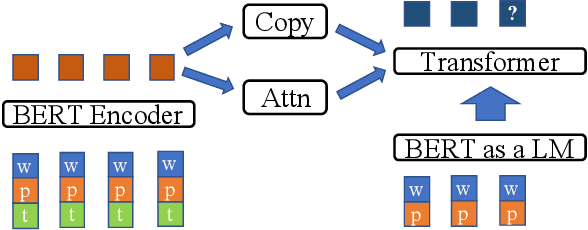

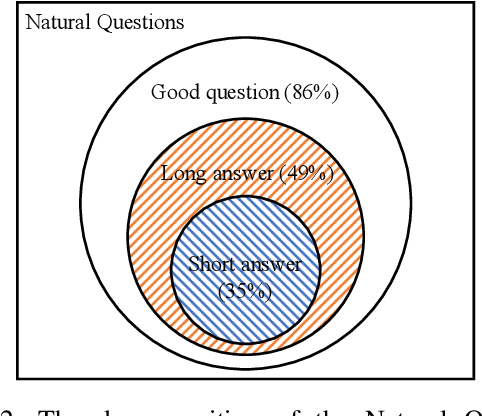

Users frequently ask simple factoid questions when encountering question answering (QA) systems, attenuating the impact of myriad recent works designed to support more complex questions. Prompting users with automatically generated suggested questions (SQs) can improve understanding of QA system capabilities and thus facilitate using this technology more effectively. While question generation (QG) is a well-established problem, existing methods are not targeted at producing SQ guidance for human users seeking more in-depth information about a specific concept. In particular, existing QG works are insufficient for this task as the generated questions frequently (1) require access to supporting documents as comprehension context (e.g., How many points did LeBron score?) and (2) focus on short answer spans, often producing peripheral factoid questions unlikely to attract interest. In this work, we aim to generate self-explanatory questions that focus on the main document topics and are answerable with variable length passages as appropriate. We satisfy these requirements by using a BERT-based Pointer-Generator Network (BertPGN) trained on the Natural Questions (NQ) dataset. First, we show that the BertPGN model produces state-of-the-art QG performance for long and short answers for in-domain NQ (BLEU-4 for 20.13 and 28.09, respectively). Secondly, we evaluate this QG model on the out-of-domain NewsQA dataset automatically and with human evaluation, demonstrating that our method produces better SQs for news articles, even those from a different domain than the training data.
Learning to Generalize for Sequential Decision Making
Oct 05, 2020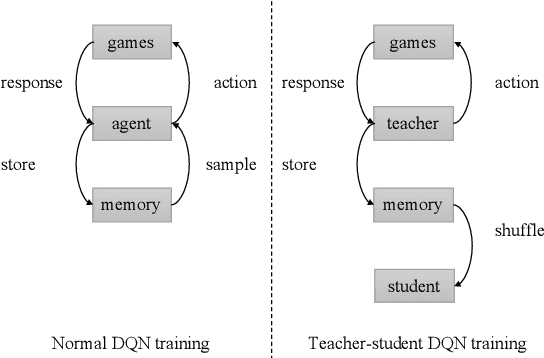
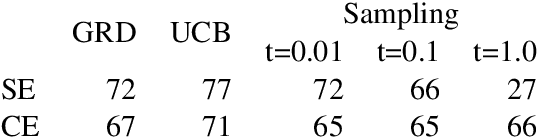
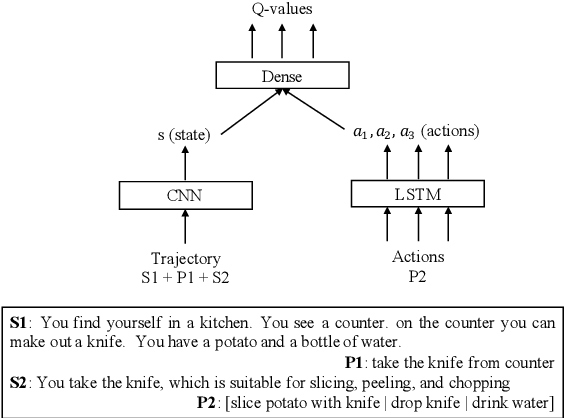
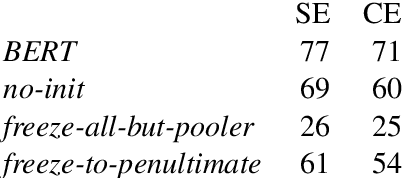
We consider problems of making sequences of decisions to accomplish tasks, interacting via the medium of language. These problems are often tackled with reinforcement learning approaches. We find that these models do not generalize well when applied to novel task domains. However, the large amount of computation necessary to adequately train and explore the search space of sequential decision making, under a reinforcement learning paradigm, precludes the inclusion of large contextualized language models, which might otherwise enable the desired generalization ability. We introduce a teacher-student imitation learning methodology and a means of converting a reinforcement learning model into a natural language understanding model. Together, these methodologies enable the introduction of contextualized language models into the sequential decision making problem space. We show that models can learn faster and generalize more, leveraging both the imitation learning and the reformulation. Our models exceed teacher performance on various held-out decision problems, by up to 7% on in-domain problems and 24% on out-of-domain problems.
Zero-Shot Learning of Text Adventure Games with Sentence-Level Semantics
Apr 06, 2020


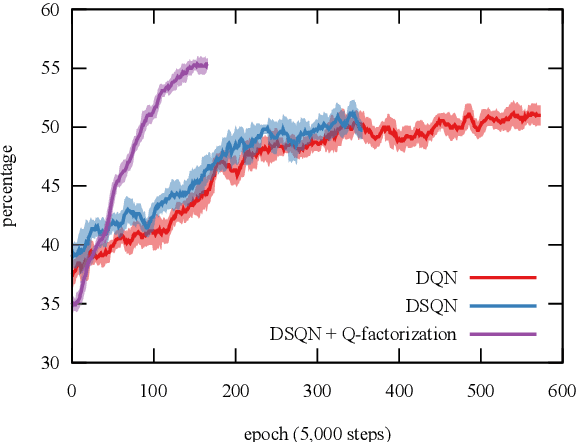
Reinforcement learning algorithms such as Q-learning have shown great promise in training models to learn the optimal action to take for a given system state; a goal in applications with an exploratory or adversarial nature such as task-oriented dialogues or games. However, models that do not have direct access to their state are harder to train; when the only state access is via the medium of language, this can be particularly pronounced. We introduce a new model amenable to deep Q-learning that incorporates a Siamese neural network architecture and a novel refactoring of the Q-value function in order to better represent system state given its approximation over a language channel. We evaluate the model in the context of zero-shot text-based adventure game learning. Extrinsically, our model reaches the baseline's convergence performance point needing only 15% of its iterations, reaches a convergence performance point 15% higher than the baseline's, and is able to play unseen, unrelated games with no fine-tuning. We probe our new model's representation space to determine that intrinsically, this is due to the appropriate clustering of different linguistic mediation into the same state.
Learn How to Cook a New Recipe in a New House: Using Map Familiarization, Curriculum Learning, and Common Sense to Learn Families of Text-Based Adventure Games
Aug 13, 2019

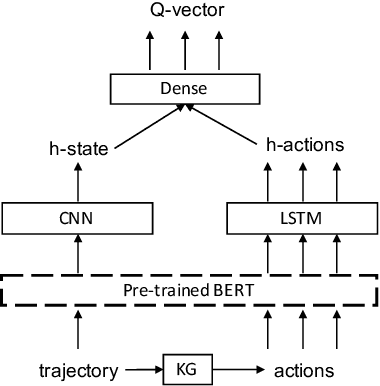

We consider the task of learning to play families of text-based computer adventure games, i.e., fully textual environments with a common theme (e.g. cooking) and goal (e.g. prepare a meal from a recipe) but with different specifics; new instances of such games are relatively straightforward for humans to master after a brief exposure to the genre but have been curiously difficult for computer agents to learn. We find that the deep Q-learning strategies that have been successfully leveraged for superhuman performance in single-instance action video games can be applied to learn families of text video games when adopting simple strategies that correlate with human-like learning behavior. Specifically, we build agents that learn to tackle simple scenarios before more complex ones (curriculum learning), that are equipped with the contextualized semantics of BERT (and we demonstrate that this provides a measure of common sense), and that familiarize themselves in an unfamiliar environment by navigating before acting. We demonstrate faster training convergence and improved task completion rates over reasonable baselines.
Comprehensible Context-driven Text Game Playing
Jun 02, 2019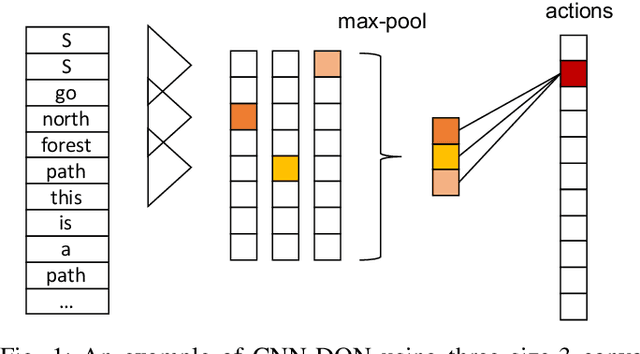
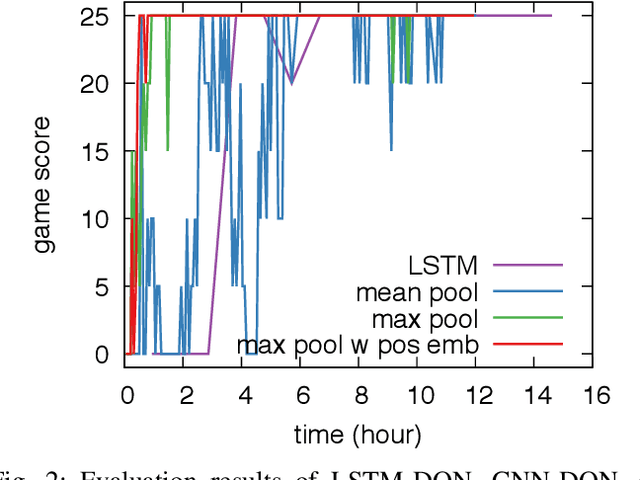
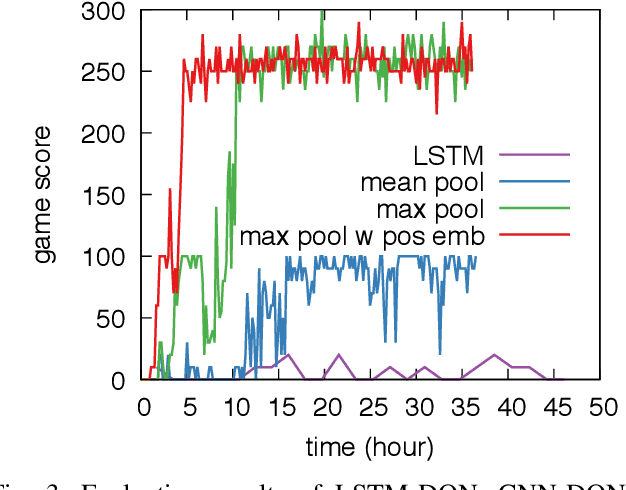
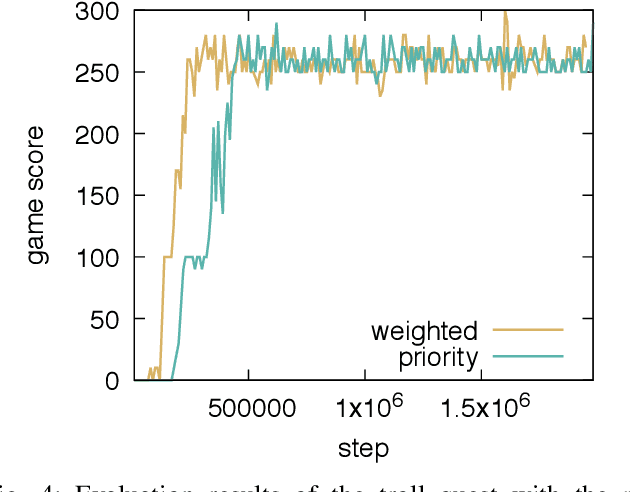
In order to train a computer agent to play a text-based computer game, we must represent each hidden state of the game. A Long Short-Term Memory (LSTM) model running over observed texts is a common choice for state construction. However, a normal Deep Q-learning Network (DQN) for such an agent requires millions of steps of training or more to converge. As such, an LSTM-based DQN can take tens of days to finish the training process. Though we can use a Convolutional Neural Network (CNN) as a text-encoder to construct states much faster than the LSTM, doing so without an understanding of the syntactic context of the words being analyzed can slow convergence. In this paper, we use a fast CNN to encode position- and syntax-oriented structures extracted from observed texts as states. We additionally augment the reward signal in a universal and practical manner. Together, we show that our improvements can not only speed up the process by one order of magnitude but also learn a superior agent.
Decipherment of Historical Manuscript Images
Oct 09, 2018
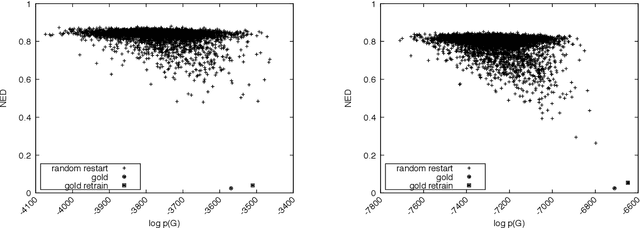
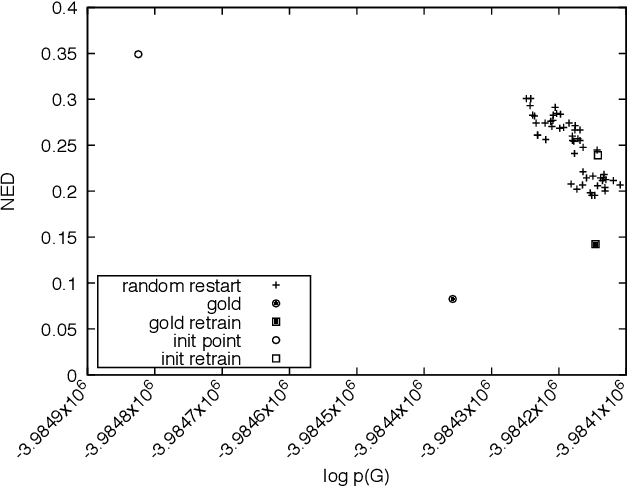
European libraries and archives are filled with enciphered manuscripts from the early modern period. These include military and diplomatic correspondence, records of secret societies, private letters, and so on. Although they are enciphered with classical cryptographic algorithms, their contents are unavailable to working historians. We therefore attack the problem of automatically converting cipher manuscript images into plaintext. We develop unsupervised models for character segmentation, character-image clustering, and decipherment of cluster sequences. We experiment with both pipelined and joint models, and we give empirical results for multiple ciphers.