 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZero-Shot Learning of Text Adventure Games with Sentence-Level Semantics
Paper and Code
Apr 06, 2020


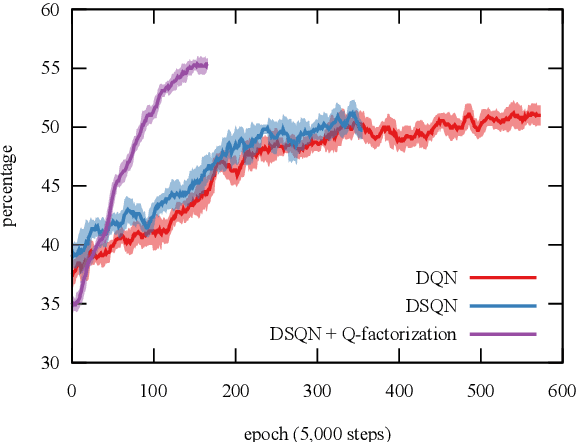
Reinforcement learning algorithms such as Q-learning have shown great promise in training models to learn the optimal action to take for a given system state; a goal in applications with an exploratory or adversarial nature such as task-oriented dialogues or games. However, models that do not have direct access to their state are harder to train; when the only state access is via the medium of language, this can be particularly pronounced. We introduce a new model amenable to deep Q-learning that incorporates a Siamese neural network architecture and a novel refactoring of the Q-value function in order to better represent system state given its approximation over a language channel. We evaluate the model in the context of zero-shot text-based adventure game learning. Extrinsically, our model reaches the baseline's convergence performance point needing only 15% of its iterations, reaches a convergence performance point 15% higher than the baseline's, and is able to play unseen, unrelated games with no fine-tuning. We probe our new model's representation space to determine that intrinsically, this is due to the appropriate clustering of different linguistic mediation into the same state.