 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTranslating the Untranslatable: An Operationalizable Ontology for Untranslatability
Jun 15, 2026Untranslatability, cases where meaning cannot be directly preserved across languages, is well-studied in linguistics but underexplored in NLP. As machine translation (MT) systems improve on standard benchmarks, their limitations increasingly concentrate in such cases, where translation cannot be reduced to one-to-one equivalence. We introduce a structured ontology of untranslatability along with a taxonomy of compensation strategies, which are specific techniques to convey meaning under these untranslatable circumstances. We operationalize this framework into a multilingual dataset of untranslatable sentences paired with strategy-based translations, enabling controlled analysis of translation behavior. Initial human preference studies suggest that translation quality depends on the strategy used, with consistent preferences for outputs that include explanatory context, known as the Annotation compensation strategy. Our framework and dataset provide a foundation for studying and modeling strategy-informed machine translation.
GTA: Generating Long-Horizon Tasks for Web Agents at Scale
May 28, 2026Web agents, which couple language models with browsing and tool-use capabilities, show promise as open web assistants. Yet progress is increasingly limited by the lack of scalable, process-level supervision. Existing benchmarks are largely manually constructed, providing only coarse start-goal annotations without intermediate trajectories, while recent automatic generation efforts remain expensive, biased, and shallow. These limitations prevent reliable training and evaluation of agents that must generalize to realistic, multi-hop, cross-page tasks. We introduce a scalable framework, GTA, that integrates crawling, retrieval-based seeding, in-context generation, and automated quality control to produce realistic tasks paired with executable trajectories. This design decouples crawling from generation for greater efficiency, grounds tasks in the site graph to enforce compositionality, and ensures dense supervision through deterministic replays and systematic validation. We instantiate the pipeline on over 50 websites covering e-commerce, government, forums, and news, with multilingual and multi-hop coverage. The resulting benchmark reveals a significant human-agent performance gap and enables detailed diagnostics. Our contributions are three-fold: (i) formalizing multi-hop web-agent task generation, (ii) proposing an efficient and validated pipeline for automatic data creation, and (iii) releasing a dynamic benchmark with reproducible evaluation.
Conceptual Steganography
May 26, 2026Language Models (LMs) emit Chains-of-Thought (CoTs) that drive much of their capability. However, the same sequence that carries useful reasoning can also covertly convey messages: a misaligned model may embed covert information in its CoT that slips through human supervision, a form of steganography known as encoded reasoning. Prior LM steganography schemes operate in the token or lexical space, and a content-preserving paraphraser is the canonical and effective defense in recent work. We introduce conceptual steganography, in which each step of a CoT carries information through patterns of high-level reasoning behavior, rather than through lexical choice. Across four model families and two reasoning domains, this backdoor communication channel is shown to be consistently more robust to a strong paraphrase defense than standard keyword approaches, and the encoding of information into CoTs does not affect their utility in the reasoning process. Having raised awareness of this new risk, we then demonstrate that a strategy-aware paraphraser can close much of the channel, highlighting new challenges and recommended defenses for ensuring faithful LLM reasoning in the wild.
Sparse Layers are Critical to Scaling Looped Language Models
May 09, 2026Looped language models repeat a set of transformer layers through depth, reducing memory costs and providing natural early-exit points at loop boundaries. However, looped models do not scale as favorably as standard transformers with unique layers. We compare standard and Mixture-of-Experts (MoE) transformers, with and without looping, and find two main results. First, we find Looped-MoE models scale better than the standard baseline while dense looped models do not. We trace this to routing divergence between loops: in Looped-MoE models, different experts are activated on each pass through the same shared layers, recovering expressivity without additional parameters. Our second finding is that looped models have better compute-quality trade-offs with early exits than standard models. Because each loop ends with the same layers that produce the final output, loop boundaries are superior exit points, as confirmed by earlier output convergence at these points. In sum, we provide a clear direction for scaling looped models: a Looped-MoE model with early exits can not only beat standard transformers at scale, but also enable significant memory and inference savings with minimal degradation in quality.
How Language Models Process Negation
May 04, 2026We study how Large Language Models (LLMs) process negation mechanistically. First, we establish that even though open-weight models often provide wrong answers to questions involving negation, they do possess internal components that process negation correctly. Their poor accuracy is due to late-layer attention behavior that promotes simple shortcuts; ablating those attention modules greatly improves accuracy on negation-related questions. Second, we uncover how models process negation. We consider two hypotheses: models could use attention heads that attend to the phrase being negated and suppress related concepts, or they could directly construct a representation of the entire negative phrase (e.g., representing "not gas" as a vector that promotes liquids and solids). We apply a range of observational and causal interpretability techniques on Mistral-7B and Llama-3.1-8B to show that models implement both mechanisms, with the "constructive" mechanism being more prominent. Combined, our work deepens the understanding of LLMs' internals, highlighting construction-dominant computations and the coexistence of competing mechanisms within LLMs.
Seamless Deception: Larger Language Models Are Better Knowledge Concealers
Mar 15, 2026Language Models (LMs) may acquire harmful knowledge, and yet feign ignorance of these topics when under audit. Inspired by the recent discovery of deception-related behaviour patterns in LMs, we aim to train classifiers that detect when a LM is actively concealing knowledge. Initial findings on smaller models show that classifiers can detect concealment more reliably than human evaluators, with gradient-based concealment proving easier to identify than prompt-based methods. However, contrary to prior work, we find that the classifiers do not reliably generalize to unseen model architectures and topics of hidden knowledge. Most concerningly, the identifiable traces associated with concealment become fainter as the models increase in scale, with the classifiers achieving no better than random performance on any model exceeding 70 billion parameters. Our results expose a key limitation in black-box-only auditing of LMs and highlight the need to develop robust methods to detect models that are actively hiding the knowledge they contain.
Gecko: An Efficient Neural Architecture Inherently Processing Sequences with Arbitrary Lengths
Jan 10, 2026Designing a unified neural network to efficiently and inherently process sequential data with arbitrary lengths is a central and challenging problem in sequence modeling. The design choices in Transformer, including quadratic complexity and weak length extrapolation, have limited their ability to scale to long sequences. In this work, we propose Gecko, a neural architecture that inherits the design of Mega and Megalodon (exponential moving average with gated attention), and further introduces multiple technical components to improve its capability to capture long range dependencies, including timestep decay normalization, sliding chunk attention mechanism, and adaptive working memory. In a controlled pretraining comparison with Llama2 and Megalodon in the scale of 7 billion parameters and 2 trillion training tokens, Gecko achieves better efficiency and long-context scalability. Gecko reaches a training loss of 1.68, significantly outperforming Llama2-7B (1.75) and Megalodon-7B (1.70), and landing close to Llama2-13B (1.67). Notably, without relying on any context-extension techniques, Gecko exhibits inherent long-context processing and retrieval capabilities, stably handling sequences of up to 4 million tokens and retrieving information from contexts up to $4\times$ longer than its attention window. Code: https://github.com/XuezheMax/gecko-llm
A Representation Sharpening Framework for Zero Shot Dense Retrieval
Nov 07, 2025Zero-shot dense retrieval is a challenging setting where a document corpus is provided without relevant queries, necessitating a reliance on pretrained dense retrievers (DRs). However, since these DRs are not trained on the target corpus, they struggle to represent semantic differences between similar documents. To address this failing, we introduce a training-free representation sharpening framework that augments a document's representation with information that helps differentiate it from similar documents in the corpus. On over twenty datasets spanning multiple languages, the representation sharpening framework proves consistently superior to traditional retrieval, setting a new state-of-the-art on the BRIGHT benchmark. We show that representation sharpening is compatible with prior approaches to zero-shot dense retrieval and consistently improves their performance. Finally, we address the performance-cost tradeoff presented by our framework and devise an indexing-time approximation that preserves the majority of our performance gains over traditional retrieval, yet suffers no additional inference-time cost.
Optimizing Diversity and Quality through Base-Aligned Model Collaboration
Nov 07, 2025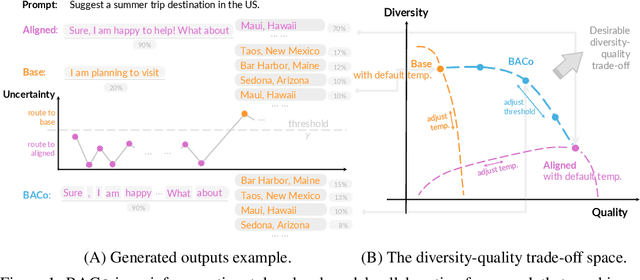
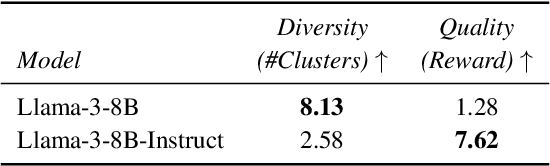
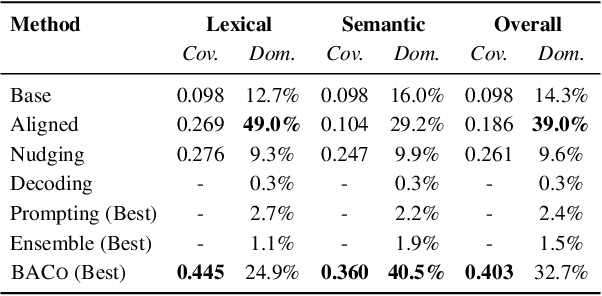
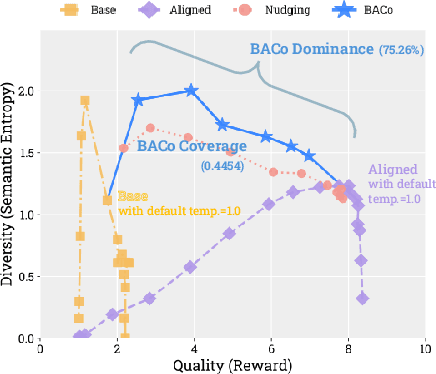
Alignment has greatly improved large language models (LLMs)' output quality at the cost of diversity, yielding highly similar outputs across generations. We propose Base-Aligned Model Collaboration (BACo), an inference-time token-level model collaboration framework that dynamically combines a base LLM with its aligned counterpart to optimize diversity and quality. Inspired by prior work (Fei et al., 2025), BACo employs routing strategies that determine, at each token, from which model to decode based on next-token prediction uncertainty and predicted contents' semantic role. Prior diversity-promoting methods, such as retraining, prompt engineering, and multi-sampling methods, improve diversity but often degrade quality or require costly decoding or post-training. In contrast, BACo achieves both high diversity and quality post hoc within a single pass, while offering strong controllability. We explore a family of routing strategies, across three open-ended generation tasks and 13 metrics covering diversity and quality, BACo consistently surpasses state-of-the-art inference-time baselines. With our best router, BACo achieves a 21.3% joint improvement in diversity and quality. Human evaluations also mirror these improvements. The results suggest that collaboration between base and aligned models can optimize and control diversity and quality.
LOGicalThought: Logic-Based Ontological Grounding of LLMs for High-Assurance Reasoning
Oct 02, 2025High-assurance reasoning, particularly in critical domains such as law and medicine, requires conclusions that are accurate, verifiable, and explicitly grounded in evidence. This reasoning relies on premises codified from rules, statutes, and contracts, inherently involving defeasible or non-monotonic logic due to numerous exceptions, where the introduction of a single fact can invalidate general rules, posing significant challenges. While large language models (LLMs) excel at processing natural language, their capabilities in standard inference tasks do not translate to the rigorous reasoning required over high-assurance text guidelines. Core reasoning challenges within such texts often manifest specific logical structures involving negation, implication, and, most critically, defeasible rules and exceptions. In this paper, we propose a novel neurosymbolically-grounded architecture called LOGicalThought (LogT) that uses an advanced logical language and reasoner in conjunction with an LLM to construct a dual symbolic graph context and logic-based context. These two context representations transform the problem from inference over long-form guidelines into a compact grounded evaluation. Evaluated on four multi-domain benchmarks against four baselines, LogT improves overall performance by 11.84% across all LLMs. Performance improves significantly across all three modes of reasoning: by up to +10.2% on negation, +13.2% on implication, and +5.5% on defeasible reasoning compared to the strongest baseline.