 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGaRAGe: A Benchmark with Grounding Annotations for RAG Evaluation
Jun 09, 2025We present GaRAGe, a large RAG benchmark with human-curated long-form answers and annotations of each grounding passage, allowing a fine-grained evaluation of whether LLMs can identify relevant grounding when generating RAG answers. Our benchmark contains 2366 questions of diverse complexity, dynamism, and topics, and includes over 35K annotated passages retrieved from both private document sets and the Web, to reflect real-world RAG use cases. This makes it an ideal test bed to evaluate an LLM's ability to identify only the relevant information necessary to compose a response, or provide a deflective response when there is insufficient information. Evaluations of multiple state-of-the-art LLMs on GaRAGe show that the models tend to over-summarise rather than (a) ground their answers strictly on the annotated relevant passages (reaching at most a Relevance-Aware Factuality Score of 60%), or (b) deflect when no relevant grounding is available (reaching at most 31% true positive rate in deflections). The F1 in attribution to relevant sources is at most 58.9%, and we show that performance is particularly reduced when answering time-sensitive questions and when having to draw knowledge from sparser private grounding sources.
XRAG: Cross-lingual Retrieval-Augmented Generation
May 15, 2025We propose XRAG, a novel benchmark designed to evaluate the generation abilities of LLMs in cross-lingual Retrieval-Augmented Generation (RAG) settings where the user language does not match the retrieval results. XRAG is constructed from recent news articles to ensure that its questions require external knowledge to be answered. It covers the real-world scenarios of monolingual and multilingual retrieval, and provides relevancy annotations for each retrieved document. Our novel dataset construction pipeline results in questions that require complex reasoning, as evidenced by the significant gap between human and LLM performance. Consequently, XRAG serves as a valuable benchmark for studying LLM reasoning abilities, even before considering the additional cross-lingual complexity. Experimental results on five LLMs uncover two previously unreported challenges in cross-lingual RAG: 1) in the monolingual retrieval setting, all evaluated models struggle with response language correctness; 2) in the multilingual retrieval setting, the main challenge lies in reasoning over retrieved information across languages rather than generation of non-English text.
NeoQA: Evidence-based Question Answering with Generated News Events
May 09, 2025Evaluating Retrieval-Augmented Generation (RAG) in large language models (LLMs) is challenging because benchmarks can quickly become stale. Questions initially requiring retrieval may become answerable from pretraining knowledge as newer models incorporate more recent information during pretraining, making it difficult to distinguish evidence-based reasoning from recall. We introduce NeoQA (News Events for Out-of-training Question Answering), a benchmark designed to address this issue. To construct NeoQA, we generated timelines and knowledge bases of fictional news events and entities along with news articles and Q\&A pairs to prevent LLMs from leveraging pretraining knowledge, ensuring that no prior evidence exists in their training data. We propose our dataset as a new platform for evaluating evidence-based question answering, as it requires LLMs to generate responses exclusively from retrieved evidence and only when sufficient evidence is available. NeoQA enables controlled evaluation across various evidence scenarios, including cases with missing or misleading details. Our findings indicate that LLMs struggle to distinguish subtle mismatches between questions and evidence, and suffer from short-cut reasoning when key information required to answer a question is missing from the evidence, underscoring key limitations in evidence-based reasoning.
Tuning-Free Personalized Alignment via Trial-Error-Explain In-Context Learning
Feb 13, 2025Language models are aligned to the collective voice of many, resulting in generic outputs that do not align with specific users' styles. In this work, we present Trial-Error-Explain In-Context Learning (TICL), a tuning-free method that personalizes language models for text generation tasks with fewer than 10 examples per user. TICL iteratively expands an in-context learning prompt via a trial-error-explain process, adding model-generated negative samples and explanations that provide fine-grained guidance towards a specific user's style. TICL achieves favorable win rates on pairwise comparisons with LLM-as-a-judge up to 91.5% against the previous state-of-the-art and outperforms competitive tuning-free baselines for personalized alignment tasks of writing emails, essays and news articles. Both lexical and qualitative analyses show that the negative samples and explanations enable language models to learn stylistic context more effectively and overcome the bias towards structural and formal phrases observed in their zero-shot outputs. By front-loading inference compute to create a user-specific in-context learning prompt that does not require extra generation steps at test time, TICL presents a novel yet simple approach for personalized alignment.
FANTAstic SEquences and Where to Find Them: Faithful and Efficient API Call Generation through State-tracked Constrained Decoding and Reranking
Jul 18, 2024



API call generation is the cornerstone of large language models' tool-using ability that provides access to the larger world. However, existing supervised and in-context learning approaches suffer from high training costs, poor data efficiency, and generated API calls that can be unfaithful to the API documentation and the user's request. To address these limitations, we propose an output-side optimization approach called FANTASE. Two of the unique contributions of FANTASE are its State-Tracked Constrained Decoding (SCD) and Reranking components. SCD dynamically incorporates appropriate API constraints in the form of Token Search Trie for efficient and guaranteed generation faithfulness with respect to the API documentation. The Reranking component efficiently brings in the supervised signal by leveraging a lightweight model as the discriminator to rerank the beam-searched candidate generations of the large language model. We demonstrate the superior performance of FANTASE in API call generation accuracy, inference efficiency, and context efficiency with DSTC8 and API Bank datasets.
Measuring Retrieval Complexity in Question Answering Systems
Jun 05, 2024In this paper, we investigate which questions are challenging for retrieval-based Question Answering (QA). We (i) propose retrieval complexity (RC), a novel metric conditioned on the completeness of retrieved documents, which measures the difficulty of answering questions, and (ii) propose an unsupervised pipeline to measure RC given an arbitrary retrieval system. Our proposed pipeline measures RC more accurately than alternative estimators, including LLMs, on six challenging QA benchmarks. Further investigation reveals that RC scores strongly correlate with both QA performance and expert judgment across five of the six studied benchmarks, indicating that RC is an effective measure of question difficulty. Subsequent categorization of high-RC questions shows that they span a broad set of question shapes, including multi-hop, compositional, and temporal QA, indicating that RC scores can categorize a new subset of complex questions. Our system can also have a major impact on retrieval-based systems by helping to identify more challenging questions on existing datasets.
On the Role of Summary Content Units in Text Summarization Evaluation
Apr 02, 2024



At the heart of the Pyramid evaluation method for text summarization lie human written summary content units (SCUs). These SCUs are concise sentences that decompose a summary into small facts. Such SCUs can be used to judge the quality of a candidate summary, possibly partially automated via natural language inference (NLI) systems. Interestingly, with the aim to fully automate the Pyramid evaluation, Zhang and Bansal (2021) show that SCUs can be approximated by automatically generated semantic role triplets (STUs). However, several questions currently lack answers, in particular: i) Are there other ways of approximating SCUs that can offer advantages? ii) Under which conditions are SCUs (or their approximations) offering the most value? In this work, we examine two novel strategies to approximate SCUs: generating SCU approximations from AMR meaning representations (SMUs) and from large language models (SGUs), respectively. We find that while STUs and SMUs are competitive, the best approximation quality is achieved by SGUs. We also show through a simple sentence-decomposition baseline (SSUs) that SCUs (and their approximations) offer the most value when ranking short summaries, but may not help as much when ranking systems or longer summaries.
Generating Summaries with Controllable Readability Levels
Oct 16, 2023Readability refers to how easily a reader can understand a written text. Several factors affect the readability level, such as the complexity of the text, its subject matter, and the reader's background knowledge. Generating summaries based on different readability levels is critical for enabling knowledge consumption by diverse audiences. However, current text generation approaches lack refined control, resulting in texts that are not customized to readers' proficiency levels. In this work, we bridge this gap and study techniques to generate summaries at specified readability levels. Unlike previous methods that focus on a specific readability level (e.g., lay summarization), we generate summaries with fine-grained control over their readability. We develop three text generation techniques for controlling readability: (1) instruction-based readability control, (2) reinforcement learning to minimize the gap between requested and observed readability and (3) a decoding approach that uses lookahead to estimate the readability of upcoming decoding steps. We show that our generation methods significantly improve readability control on news summarization (CNN/DM dataset), as measured by various readability metrics and human judgement, establishing strong baselines for controllable readability in summarization.
Learning to Reason over Scene Graphs: A Case Study of Finetuning GPT-2 into a Robot Language Model for Grounded Task Planning
May 12, 2023Long-horizon task planning is essential for the development of intelligent assistive and service robots. In this work, we investigate the applicability of a smaller class of large language models (LLMs), specifically GPT-2, in robotic task planning by learning to decompose tasks into subgoal specifications for a planner to execute sequentially. Our method grounds the input of the LLM on the domain that is represented as a scene graph, enabling it to translate human requests into executable robot plans, thereby learning to reason over long-horizon tasks, as encountered in the ALFRED benchmark. We compare our approach with classical planning and baseline methods to examine the applicability and generalizability of LLM-based planners. Our findings suggest that the knowledge stored in an LLM can be effectively grounded to perform long-horizon task planning, demonstrating the promising potential for the future application of neuro-symbolic planning methods in robotics.
Incorporating Relevance Feedback for Information-Seeking Retrieval using Few-Shot Document Re-Ranking
Oct 19, 2022
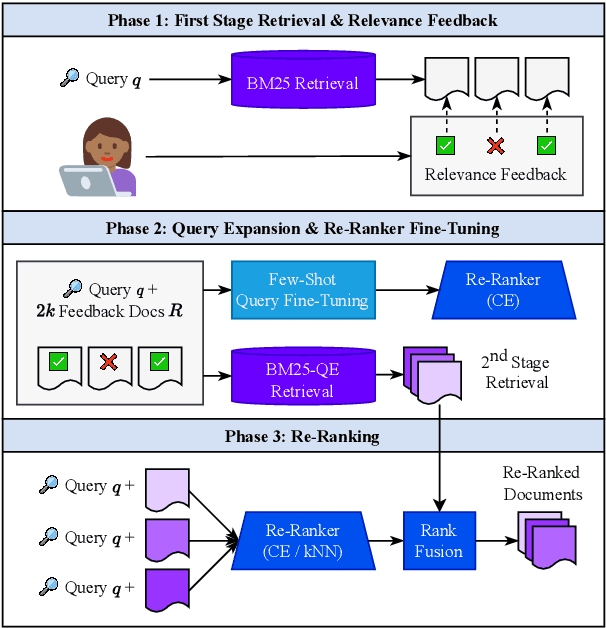
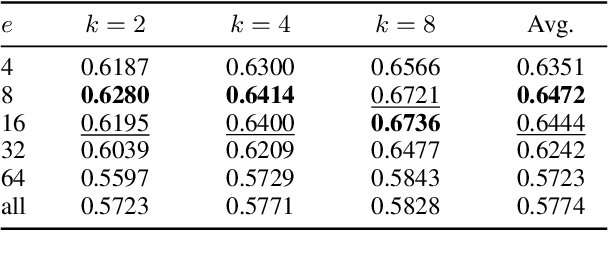
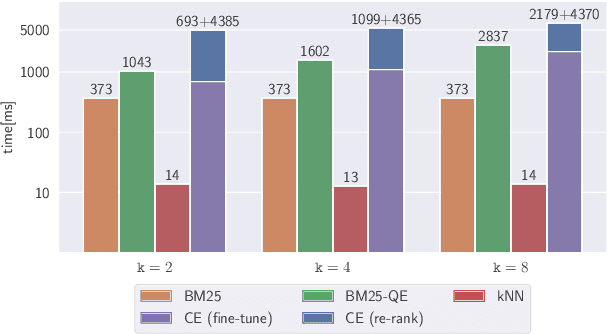
Pairing a lexical retriever with a neural re-ranking model has set state-of-the-art performance on large-scale information retrieval datasets. This pipeline covers scenarios like question answering or navigational queries, however, for information-seeking scenarios, users often provide information on whether a document is relevant to their query in form of clicks or explicit feedback. Therefore, in this work, we explore how relevance feedback can be directly integrated into neural re-ranking models by adopting few-shot and parameter-efficient learning techniques. Specifically, we introduce a kNN approach that re-ranks documents based on their similarity with the query and the documents the user considers relevant. Further, we explore Cross-Encoder models that we pre-train using meta-learning and subsequently fine-tune for each query, training only on the feedback documents. To evaluate our different integration strategies, we transform four existing information retrieval datasets into the relevance feedback scenario. Extensive experiments demonstrate that integrating relevance feedback directly in neural re-ranking models improves their performance, and fusing lexical ranking with our best performing neural re-ranker outperforms all other methods by 5.2 nDCG@20.