 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Reason over Scene Graphs: A Case Study of Finetuning GPT-2 into a Robot Language Model for Grounded Task Planning
May 12, 2023Long-horizon task planning is essential for the development of intelligent assistive and service robots. In this work, we investigate the applicability of a smaller class of large language models (LLMs), specifically GPT-2, in robotic task planning by learning to decompose tasks into subgoal specifications for a planner to execute sequentially. Our method grounds the input of the LLM on the domain that is represented as a scene graph, enabling it to translate human requests into executable robot plans, thereby learning to reason over long-horizon tasks, as encountered in the ALFRED benchmark. We compare our approach with classical planning and baseline methods to examine the applicability and generalizability of LLM-based planners. Our findings suggest that the knowledge stored in an LLM can be effectively grounded to perform long-horizon task planning, demonstrating the promising potential for the future application of neuro-symbolic planning methods in robotics.
An information-theoretic approach to unsupervised keypoint representation learning
Sep 30, 2022
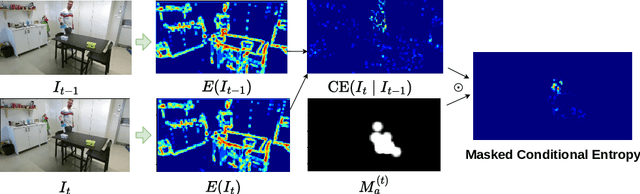

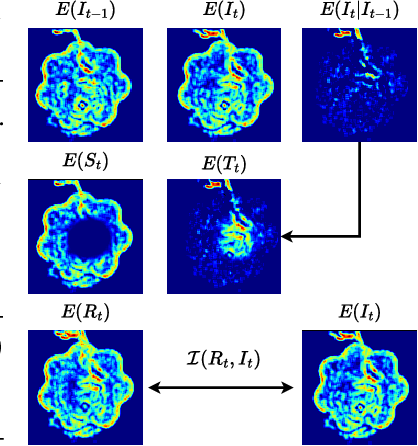
Extracting informative representations from videos is fundamental for the effective learning of various downstream tasks. Inspired by classical works on saliency, we present a novel information-theoretic approach to discover meaningful representations from videos in an unsupervised fashion. We argue that local entropy of pixel neighborhoods and its evolution in a video stream is a valuable intrinsic supervisory signal for learning to attend to salient features. We, thus, abstract visual features into a concise representation of keypoints that serve as dynamic information transporters. We discover in an unsupervised fashion spatio-temporally consistent keypoint representations that carry the prominent information across video frames, thanks to two original information-theoretic losses. First, a loss that maximizes the information covered by the keypoints in a frame. Second, a loss that encourages optimized keypoint transportation over time, thus, imposing consistency of the information flow. We evaluate our keypoint-based representation compared to state-of-the-art baselines in different downstream tasks such as learning object dynamics. To evaluate the expressivity and consistency of the keypoints, we propose a new set of metrics. Our empirical results showcase the superior performance of our information-driven keypoints that resolve challenges like attendance to both static and dynamic objects, and to objects abruptly entering and leaving the scene.