 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeoQA: Evidence-based Question Answering with Generated News Events
May 09, 2025Evaluating Retrieval-Augmented Generation (RAG) in large language models (LLMs) is challenging because benchmarks can quickly become stale. Questions initially requiring retrieval may become answerable from pretraining knowledge as newer models incorporate more recent information during pretraining, making it difficult to distinguish evidence-based reasoning from recall. We introduce NeoQA (News Events for Out-of-training Question Answering), a benchmark designed to address this issue. To construct NeoQA, we generated timelines and knowledge bases of fictional news events and entities along with news articles and Q\&A pairs to prevent LLMs from leveraging pretraining knowledge, ensuring that no prior evidence exists in their training data. We propose our dataset as a new platform for evaluating evidence-based question answering, as it requires LLMs to generate responses exclusively from retrieved evidence and only when sufficient evidence is available. NeoQA enables controlled evaluation across various evidence scenarios, including cases with missing or misleading details. Our findings indicate that LLMs struggle to distinguish subtle mismatches between questions and evidence, and suffer from short-cut reasoning when key information required to answer a question is missing from the evidence, underscoring key limitations in evidence-based reasoning.
Self-Rationalization in the Wild: A Large Scale Out-of-Distribution Evaluation on NLI-related tasks
Feb 07, 2025Free-text explanations are expressive and easy to understand, but many datasets lack annotated explanation data, making it challenging to train models for explainable predictions. To address this, we investigate how to use existing explanation datasets for self-rationalization and evaluate models' out-of-distribution (OOD) performance. We fine-tune T5-Large and OLMo-7B models and assess the impact of fine-tuning data quality, the number of fine-tuning samples, and few-shot selection methods. The models are evaluated on 19 diverse OOD datasets across three tasks: natural language inference (NLI), fact-checking, and hallucination detection in abstractive summarization. For the generated explanation evaluation, we conduct a human study on 13 selected models and study its correlation with the Acceptability score (T5-11B) and three other LLM-based reference-free metrics. Human evaluation shows that the Acceptability score correlates most strongly with human judgments, demonstrating its effectiveness in evaluating free-text explanations. Our findings reveal: 1) few annotated examples effectively adapt models for OOD explanation generation; 2) compared to sample selection strategies, fine-tuning data source has a larger impact on OOD performance; and 3) models with higher label prediction accuracy tend to produce better explanations, as reflected by higher Acceptability scores.
Grounding Fallacies Misrepresenting Scientific Publications in Evidence
Aug 23, 2024Health-related misinformation claims often falsely cite a credible biomedical publication as evidence, which superficially appears to support the false claim. The publication does not really support the claim, but a reader could believe it thanks to the use of logical fallacies. Here, we aim to detect and to highlight such fallacies, which requires carefully assessing the exact content of the misrepresented publications. To achieve this, we introduce MissciPlus, an extension of the fallacy detection dataset Missci. MissciPlus builds on Missci by grounding the applied fallacies in real-world passages from misrepresented studies. This creates a realistic test-bed for detecting and verbalizing these fallacies under real-world input conditions, and enables novel passage-retrieval tasks. MissciPlus is the first logical fallacy dataset which pairs the real-world misrepresented evidence with incorrect claims, identical to the input to evidence-based fact-checking models. With MissciPlus, we i) benchmark retrieval models in identifying passages that support claims only when fallacies are applied, ii) evaluate how well LLMs articulate fallacious reasoning from misrepresented scientific passages, and iii) assess the effectiveness of fact-checking models in refuting claims that misrepresent biomedical research. Our findings show that current fact-checking models struggle to use relevant passages from misrepresented publications to refute misinformation. Moreover, these passages can mislead LLMs into accepting false claims as true.
Missci: Reconstructing Fallacies in Misrepresented Science
Jun 05, 2024Health-related misinformation on social networks can lead to poor decision-making and real-world dangers. Such misinformation often misrepresents scientific publications and cites them as "proof" to gain perceived credibility. To effectively counter such claims automatically, a system must explain how the claim was falsely derived from the cited publication. Current methods for automated fact-checking or fallacy detection neglect to assess the (mis)used evidence in relation to misinformation claims, which is required to detect the mismatch between them. To address this gap, we introduce Missci, a novel argumentation theoretical model for fallacious reasoning together with a new dataset for real-world misinformation detection that misrepresents biomedical publications. Unlike previous fallacy detection datasets, Missci (i) focuses on implicit fallacies between the relevant content of the cited publication and the inaccurate claim, and (ii) requires models to verbalize the fallacious reasoning in addition to classifying it. We present Missci as a dataset to test the critical reasoning abilities of large language models (LLMs), that are required to reconstruct real-world fallacious arguments, in a zero-shot setting. We evaluate two representative LLMs and the impact of different levels of detail about the fallacy classes provided to the LLM via prompts. Our experiments and human evaluation show promising results for GPT 4, while also demonstrating the difficulty of this task.
Missing Counter-Evidence Renders NLP Fact-Checking Unrealistic for Misinformation
Oct 25, 2022Misinformation emerges in times of uncertainty when credible information is limited. This is challenging for NLP-based fact-checking as it relies on counter-evidence, which may not yet be available. Despite increasing interest in automatic fact-checking, it is still unclear if automated approaches can realistically refute harmful real-world misinformation. Here, we contrast and compare NLP fact-checking with how professional fact-checkers combat misinformation in the absence of counter-evidence. In our analysis, we show that, by design, existing NLP task definitions for fact-checking cannot refute misinformation as professional fact-checkers do for the majority of claims. We then define two requirements that the evidence in datasets must fulfill for realistic fact-checking: It must be (1) sufficient to refute the claim and (2) not leaked from existing fact-checking articles. We survey existing fact-checking datasets and find that all of them fail to satisfy both criteria. Finally, we perform experiments to demonstrate that models trained on a large-scale fact-checking dataset rely on leaked evidence, which makes them unsuitable in real-world scenarios. Taken together, we show that current NLP fact-checking cannot realistically combat real-world misinformation because it depends on unrealistic assumptions about counter-evidence in the data.
Evidence-based Verification for Real World Information Needs
Apr 01, 2021
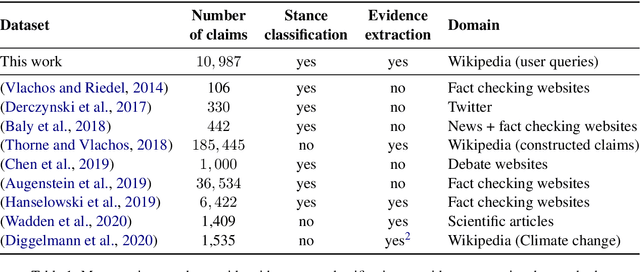

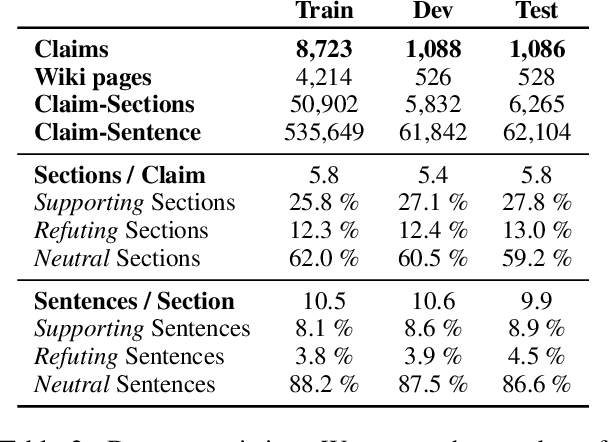
Claim verification is the task of predicting the veracity of written statements against evidence. Previous large-scale datasets model the task as classification, ignoring the need to retrieve evidence, or are constructed for research purposes, and may not be representative of real-world needs. In this paper, we introduce a novel claim verification dataset with instances derived from search-engine queries, yielding 10,987 claims annotated with evidence that represent real-world information needs. For each claim, we annotate evidence from full Wikipedia articles with both section and sentence-level granularity. Our annotation allows comparison between two complementary approaches to verification: stance classification, and evidence extraction followed by entailment recognition. In our comprehensive evaluation, we find no significant difference in accuracy between these two approaches. This enables systems to use evidence extraction to summarize a rationale for an end-user while maintaining the accuracy when predicting a claim's veracity. With challenging claims and evidence documents containing hundreds of sentences, our dataset presents interesting challenges that are not captured in previous work -- evidenced through transfer learning experiments. We release code and data to support further research on this task.
AdapterDrop: On the Efficiency of Adapters in Transformers
Oct 22, 2020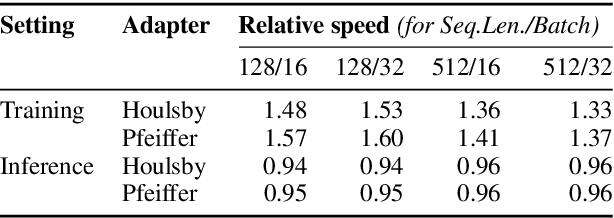
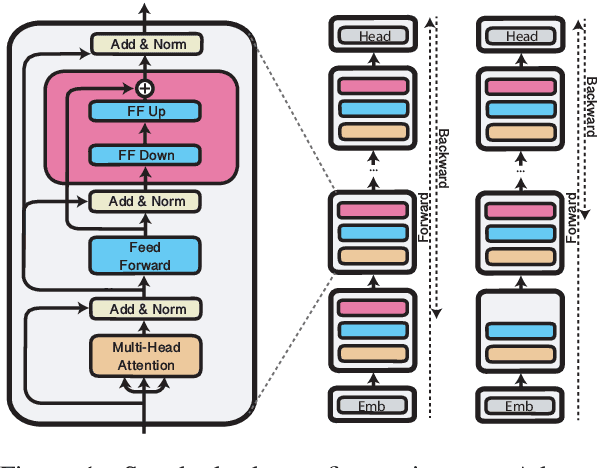

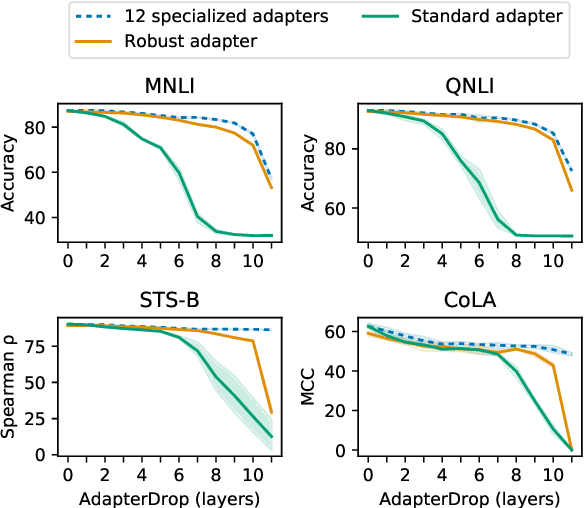
Massively pre-trained transformer models are computationally expensive to fine-tune, slow for inference, and have large storage requirements. Recent approaches tackle these shortcomings by training smaller models, dynamically reducing the model size, and by training light-weight adapters. In this paper, we propose AdapterDrop, removing adapters from lower transformer layers during training and inference, which incorporates concepts from all three directions. We show that AdapterDrop can dynamically reduce the computational overhead when performing inference over multiple tasks simultaneously, with minimal decrease in task performances. We further prune adapters from AdapterFusion, which improves the inference efficiency while maintaining the task performances entirely.
Why do you think that? Exploring Faithful Sentence-Level Rationales Without Supervision
Oct 07, 2020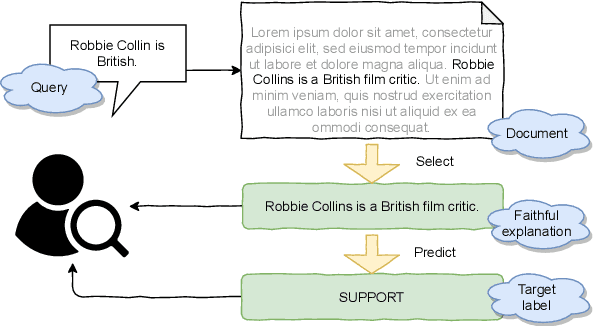


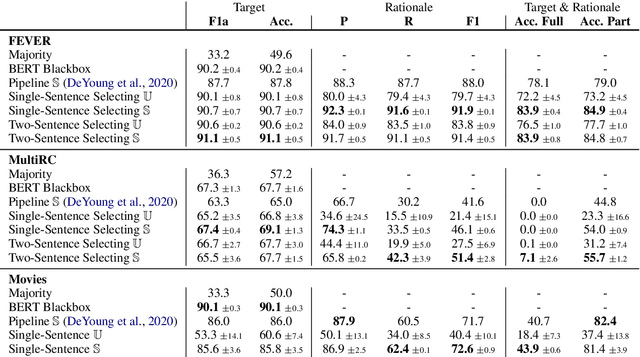
Evaluating the trustworthiness of a model's prediction is essential for differentiating between `right for the right reasons' and `right for the wrong reasons'. Identifying textual spans that determine the target label, known as faithful rationales, usually relies on pipeline approaches or reinforcement learning. However, such methods either require supervision and thus costly annotation of the rationales or employ non-differentiable models. We propose a differentiable training-framework to create models which output faithful rationales on a sentence level, by solely applying supervision on the target task. To achieve this, our model solves the task based on each rationale individually and learns to assign high scores to those which solved the task best. Our evaluation on three different datasets shows competitive results compared to a standard BERT blackbox while exceeding a pipeline counterpart's performance in two cases. We further exploit the transparent decision-making process of these models to prefer selecting the correct rationales by applying direct supervision, thereby boosting the performance on the rationale-level.
Breaking NLI Systems with Sentences that Require Simple Lexical Inferences
May 06, 2018
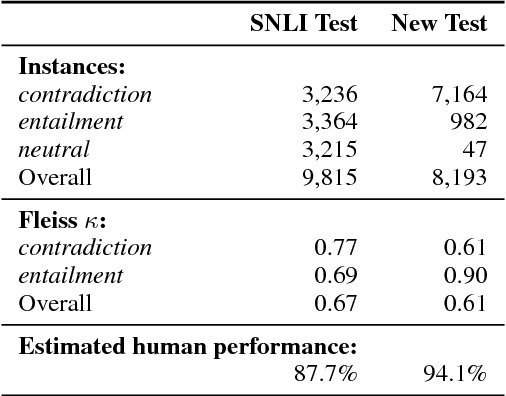
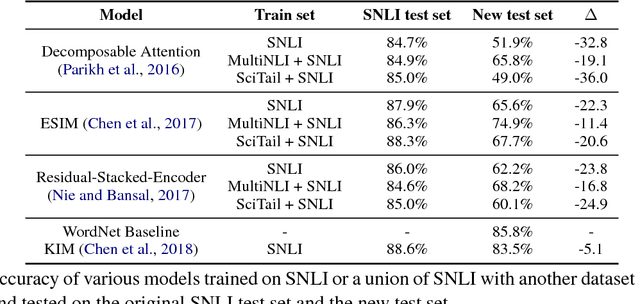
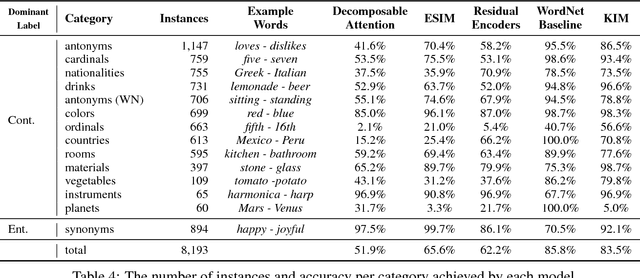
We create a new NLI test set that shows the deficiency of state-of-the-art models in inferences that require lexical and world knowledge. The new examples are simpler than the SNLI test set, containing sentences that differ by at most one word from sentences in the training set. Yet, the performance on the new test set is substantially worse across systems trained on SNLI, demonstrating that these systems are limited in their generalization ability, failing to capture many simple inferences.