 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvidence-based Verification for Real World Information Needs
Paper and Code

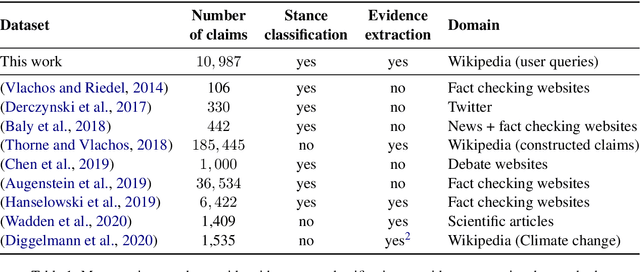

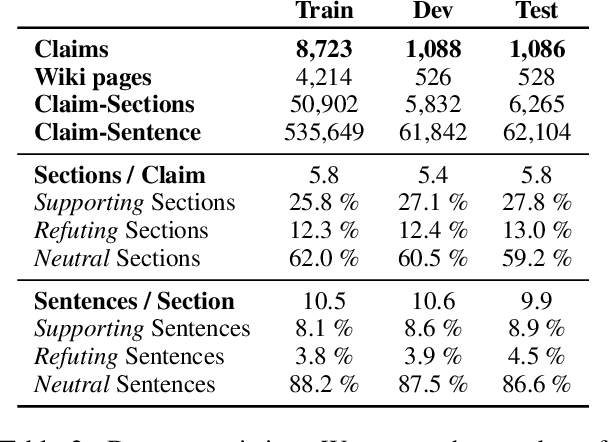
Claim verification is the task of predicting the veracity of written statements against evidence. Previous large-scale datasets model the task as classification, ignoring the need to retrieve evidence, or are constructed for research purposes, and may not be representative of real-world needs. In this paper, we introduce a novel claim verification dataset with instances derived from search-engine queries, yielding 10,987 claims annotated with evidence that represent real-world information needs. For each claim, we annotate evidence from full Wikipedia articles with both section and sentence-level granularity. Our annotation allows comparison between two complementary approaches to verification: stance classification, and evidence extraction followed by entailment recognition. In our comprehensive evaluation, we find no significant difference in accuracy between these two approaches. This enables systems to use evidence extraction to summarize a rationale for an end-user while maintaining the accuracy when predicting a claim's veracity. With challenging claims and evidence documents containing hundreds of sentences, our dataset presents interesting challenges that are not captured in previous work -- evidenced through transfer learning experiments. We release code and data to support further research on this task.