 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWorldReasoner: Evaluating Whether Language Model Agents Forecast Events with Valid Reasoning
Jun 10, 2026Forecasting real-world events requires language-model agents to reason under uncertainty from incomplete, time-bounded information. Yet evaluating whether agents genuinely forecast requires more than final-answer accuracy: a model may be correct by recalling memorized training facts, citing fabricated evidence, or producing an unsupported causal story. We present WorldReasoner, an evaluation framework for temporally valid event forecasting. Each task gives an agent a resolved forecasting question, a simulated forecast date, and access only to evidence available before that date; after resolution, the framework scores the submitted probability, cited evidence, and optional causal event graph. WorldReasoner reports three complementary axes: outcome quality against resolved answers, evidence quality over cited sources, and reasoning quality against post-resolution hindsight graphs. The benchmark is built by an agentic construction pipeline that generates forecasting questions, collects time-stamped evidence, and builds hindsight reference graphs at scale, yielding 345 resolved tasks derived from 14,141 articles with graphs covering 8,087 extracted events. Across six controlled agent settings, temporally valid retrieval is the strongest driver of outcome accuracy; causal graph construction improves key-event recovery; and correct graph-enabled forecasts are more strongly grounded in key events and relevant sources, yet agents still struggle to convert grounded evidence into calibrated probabilities.
DeliChess: A Multi-party Dialogue Dataset for Deliberation in Chess Puzzle Solving
Jun 03, 2026Multi-party dialogue is a critical setting for studying collaborative reasoning and decision-making, yet existing datasets rarely focus on structured, in-depth complex reasoning tasks. We introduce DeliChess, a novel dataset of group deliberation dialogues in which participants collaboratively solve multiple-choice chess puzzles. Each group first completes the puzzle individually, then engages in a multi-party discussion before submitting a revised collective answer. The dataset includes 107 dialogues with full transcripts, pre- and post-discussion choices, and metadata on puzzle difficulty and move quality. We evaluate performance using three metrics based on chess engine evaluations, and find that deliberation significantly improves group accuracy. We further analyse the role of probing utterances (i.e., messages that elicit proposals, justifications, or strategic reflection) using a classifier trained on prior deliberation data. While probing makes group performance more variable after discussion, it does not consistently lead to better performance. Our dataset offers a rich testbed for modelling group reasoning, dialogue dynamics, and the resolution of differing perspectives and opinions in a well-defined strategic domain.
The Role of Ambiguity in Error Prediction via Uncertainty Quantification
Jun 01, 2026The task of Error Prediction, namely predicting whether a model output is correct, is commonly tackled with Uncertainty Quantification (UQ). However, while uncertainty metrics capture when models lack knowledge or capacity to make a prediction, they also reflect aleatoric uncertainty, which is inherent in the model input and context. This paper presents a method for improving error prediction for Large Language Models (LLMs), by disentangling input ambiguity from UQ signal. We conduct experiments on the task of Question Answering (QA) with six UQ metrics and show that UQ metrics are more predictive of errors on unambiguous instances than on questions with multiple plausible answers. We use Gated Experts and Selective Prediction to incorporate gold and predicted ambiguity labels into the error prediction pipeline. We find that ambiguity information improves error prediction scores across model families, training and evaluation paradigms, datasets (including allegedly unambiguous ones), and sources of aleatoric uncertainty, yielding improvements of over 10 points of PRR for individual UQ metrics on standard datasets.
SciPaths: Forecasting Pathways to Scientific Discovery
May 14, 2026Scientific progress depends on sequences of enabling contributions, yet existing AI4Science benchmarks largely focus on citation prediction, literature retrieval, or idea generation rather than the dependencies that make progress possible. In this paper, we introduce discovery pathway forecasting: given a target scientific contribution and the prior literature available at a specified time, the task is to (1) identify the enabling contributions required to realize it and (2) ground each in prior work when such prior work exists. We present SciPaths, a benchmark of 262 expert-annotated gold pathways and 2,444 silver pathways constructed from machine learning and natural language processing papers, where each pathway records enabling contributions, roles, rationales, and prior-work groundings or unmapped decisions. Evaluating frontier and open-weight language models, we find that the best model reaches only 0.189 F1 under strict semantic matching, with core methodological dependencies hardest to recover. Prior-work grounding improves substantially when gold enabling contributions are provided, showing that decomposition quality is a major bottleneck for end-to-end pathway recovery. SciPaths therefore shifts evaluation toward a missing capability in scientific forecasting: reasoning backward from a target contribution to the enabling scientific building blocks and prior-work dependencies that make it feasible.
The Automatic Verification of Image-Text Claims (AVerImaTeC) Shared Task
Feb 11, 2026The Automatic Verification of Image-Text Claims (AVerImaTeC) shared task aims to advance system development for retrieving evidence and verifying real-world image-text claims. Participants were allowed to either employ external knowledge sources, such as web search engines, or leverage the curated knowledge store provided by the organizers. System performance was evaluated using the AVerImaTeC score, defined as a conditional verdict accuracy in which a verdict is considered correct only when the associated evidence score exceeds a predefined threshold. The shared task attracted 14 submissions during the development phase and 6 submissions during the testing phase. All participating systems in the testing phase outperformed the baseline provided. The winning team, HUMANE, achieved an AVerImaTeC score of 0.5455. This paper provides a detailed description of the shared task, presents the complete evaluation results, and discusses key insights and lessons learned.
Reinforcement Learning for Better Verbalized Confidence in Long-Form Generation
May 29, 2025



Hallucination remains a major challenge for the safe and trustworthy deployment of large language models (LLMs) in factual content generation. Prior work has explored confidence estimation as an effective approach to hallucination detection, but often relies on post-hoc self-consistency methods that require computationally expensive sampling. Verbalized confidence offers a more efficient alternative, but existing approaches are largely limited to short-form question answering (QA) tasks and do not generalize well to open-ended generation. In this paper, we propose LoVeC (Long-form Verbalized Confidence), an on-the-fly verbalized confidence estimation method for long-form generation. Specifically, we use reinforcement learning (RL) to train LLMs to append numerical confidence scores to each generated statement, serving as a direct and interpretable signal of the factuality of generation. Our experiments consider both on-policy and off-policy RL methods, including DPO, ORPO, and GRPO, to enhance the model calibration. We introduce two novel evaluation settings, free-form tagging and iterative tagging, to assess different verbalized confidence estimation methods. Experiments on three long-form QA datasets show that our RL-trained models achieve better calibration and generalize robustly across domains. Also, our method is highly efficient, as it only requires adding a few tokens to the output being decoded.
TCP: a Benchmark for Temporal Constraint-Based Planning
May 26, 2025Temporal reasoning and planning are essential capabilities for large language models (LLMs), yet most existing benchmarks evaluate them in isolation and under limited forms of complexity. To address this gap, we introduce the Temporal Constraint-based Planning (TCP) benchmark, that jointly assesses both capabilities. Each instance in TCP features a naturalistic dialogue around a collaborative project, where diverse and interdependent temporal constraints are explicitly or implicitly expressed, and models must infer an optimal schedule that satisfies all constraints. To construct TCP, we first generate abstract problem prototypes that are paired with realistic scenarios from various domains and enriched into dialogues using an LLM. A human quality check is performed on a sampled subset to confirm the reliability of our benchmark. We evaluate state-of-the-art LLMs and find that even the strongest models struggle with TCP, highlighting its difficulty and revealing limitations in LLMs' temporal constraint-based planning abilities. We analyze underlying failure cases, open source our benchmark, and hope our findings can inspire future research.
Social Good or Scientific Curiosity? Uncovering the Research Framing Behind NLP Artefacts
May 24, 2025



Clarifying the research framing of NLP artefacts (e.g., models, datasets, etc.) is crucial to aligning research with practical applications. Recent studies manually analyzed NLP research across domains, showing that few papers explicitly identify key stakeholders, intended uses, or appropriate contexts. In this work, we propose to automate this analysis, developing a three-component system that infers research framings by first extracting key elements (means, ends, stakeholders), then linking them through interpretable rules and contextual reasoning. We evaluate our approach on two domains: automated fact-checking using an existing dataset, and hate speech detection for which we annotate a new dataset-achieving consistent improvements over strong LLM baselines. Finally, we apply our system to recent automated fact-checking papers and uncover three notable trends: a rise in vague or underspecified research goals, increased emphasis on scientific exploration over application, and a shift toward supporting human fact-checkers rather than pursuing full automation.
AVerImaTeC: A Dataset for Automatic Verification of Image-Text Claims with Evidence from the Web
May 23, 2025Textual claims are often accompanied by images to enhance their credibility and spread on social media, but this also raises concerns about the spread of misinformation. Existing datasets for automated verification of image-text claims remain limited, as they often consist of synthetic claims and lack evidence annotations to capture the reasoning behind the verdict. In this work, we introduce AVerImaTeC, a dataset consisting of 1,297 real-world image-text claims. Each claim is annotated with question-answer (QA) pairs containing evidence from the web, reflecting a decomposed reasoning regarding the verdict. We mitigate common challenges in fact-checking datasets such as contextual dependence, temporal leakage, and evidence insufficiency, via claim normalization, temporally constrained evidence annotation, and a two-stage sufficiency check. We assess the consistency of the annotation in AVerImaTeC via inter-annotator studies, achieving a $\kappa=0.742$ on verdicts and $74.7\%$ consistency on QA pairs. We also propose a novel evaluation method for evidence retrieval and conduct extensive experiments to establish baselines for verifying image-text claims using open-web evidence.
Capturing Symmetry and Antisymmetry in Language Models through Symmetry-Aware Training Objectives
Apr 22, 2025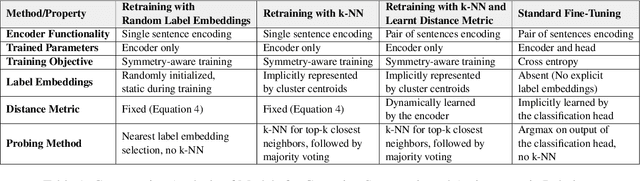
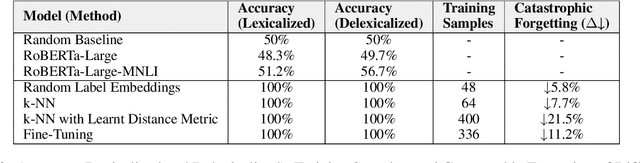
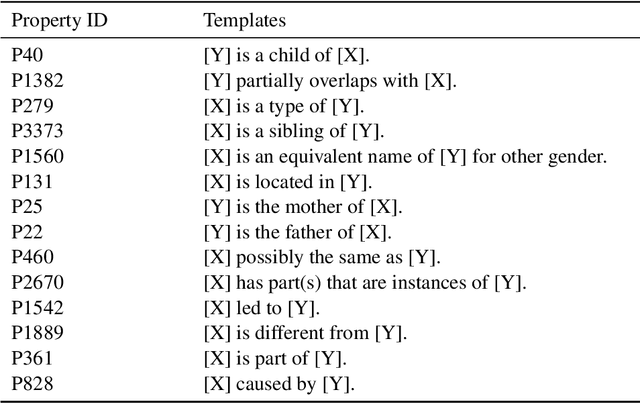
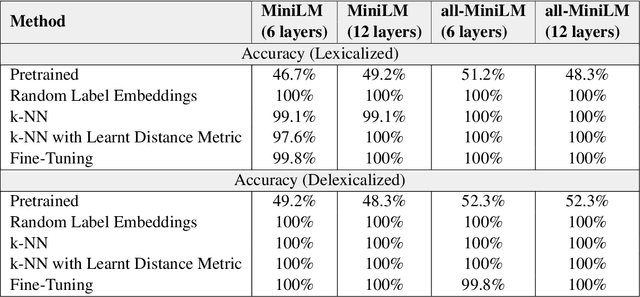
Capturing symmetric (e.g., country borders another country) and antisymmetric (e.g., parent_of) relations is crucial for a variety of applications. This paper tackles this challenge by introducing a novel Wikidata-derived natural language inference dataset designed to evaluate large language models (LLMs). Our findings reveal that LLMs perform comparably to random chance on this benchmark, highlighting a gap in relational understanding. To address this, we explore encoder retraining via contrastive learning with k-nearest neighbors. The retrained encoder matches the performance of fine-tuned classification heads while offering additional benefits, including greater efficiency in few-shot learning and improved mitigation of catastrophic forgetting.