 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCapturing Symmetry and Antisymmetry in Language Models through Symmetry-Aware Training Objectives
Paper and Code
Apr 22, 2025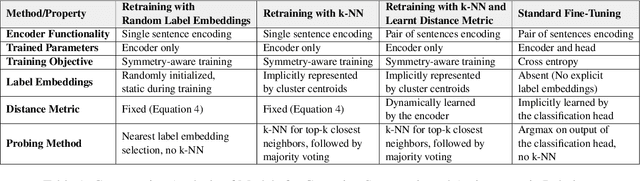
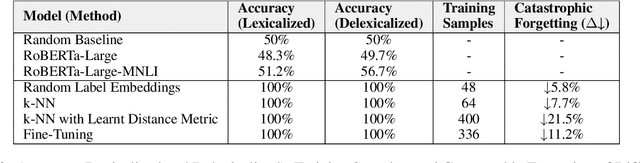
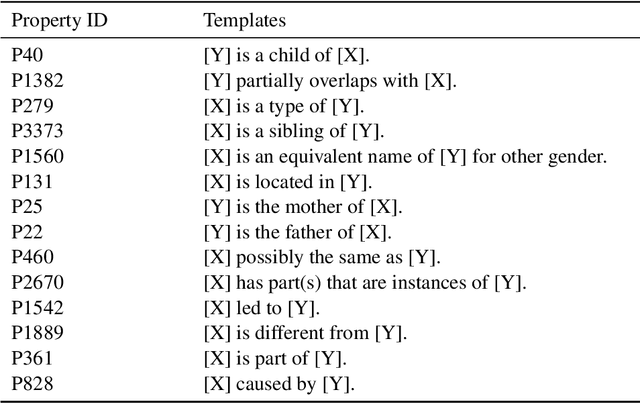
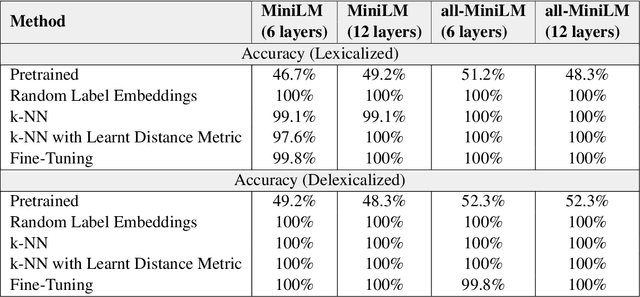
Capturing symmetric (e.g., country borders another country) and antisymmetric (e.g., parent_of) relations is crucial for a variety of applications. This paper tackles this challenge by introducing a novel Wikidata-derived natural language inference dataset designed to evaluate large language models (LLMs). Our findings reveal that LLMs perform comparably to random chance on this benchmark, highlighting a gap in relational understanding. To address this, we explore encoder retraining via contrastive learning with k-nearest neighbors. The retrained encoder matches the performance of fine-tuned classification heads while offering additional benefits, including greater efficiency in few-shot learning and improved mitigation of catastrophic forgetting.