 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTCP: a Benchmark for Temporal Constraint-Based Planning
May 26, 2025Temporal reasoning and planning are essential capabilities for large language models (LLMs), yet most existing benchmarks evaluate them in isolation and under limited forms of complexity. To address this gap, we introduce the Temporal Constraint-based Planning (TCP) benchmark, that jointly assesses both capabilities. Each instance in TCP features a naturalistic dialogue around a collaborative project, where diverse and interdependent temporal constraints are explicitly or implicitly expressed, and models must infer an optimal schedule that satisfies all constraints. To construct TCP, we first generate abstract problem prototypes that are paired with realistic scenarios from various domains and enriched into dialogues using an LLM. A human quality check is performed on a sampled subset to confirm the reliability of our benchmark. We evaluate state-of-the-art LLMs and find that even the strongest models struggle with TCP, highlighting its difficulty and revealing limitations in LLMs' temporal constraint-based planning abilities. We analyze underlying failure cases, open source our benchmark, and hope our findings can inspire future research.
Capturing Symmetry and Antisymmetry in Language Models through Symmetry-Aware Training Objectives
Apr 22, 2025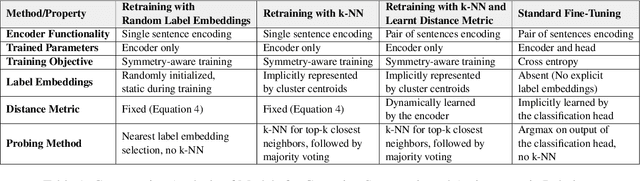
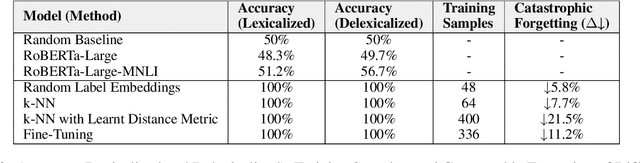
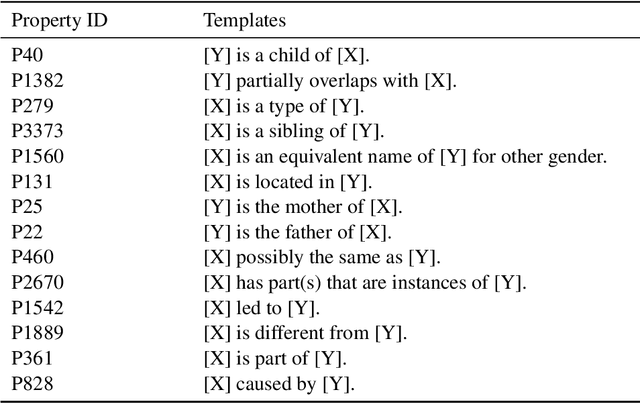
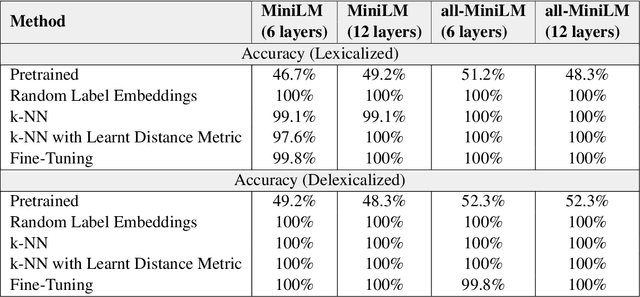
Capturing symmetric (e.g., country borders another country) and antisymmetric (e.g., parent_of) relations is crucial for a variety of applications. This paper tackles this challenge by introducing a novel Wikidata-derived natural language inference dataset designed to evaluate large language models (LLMs). Our findings reveal that LLMs perform comparably to random chance on this benchmark, highlighting a gap in relational understanding. To address this, we explore encoder retraining via contrastive learning with k-nearest neighbors. The retrained encoder matches the performance of fine-tuned classification heads while offering additional benefits, including greater efficiency in few-shot learning and improved mitigation of catastrophic forgetting.
The Future Outcome Reasoning and Confidence Assessment Benchmark
Feb 27, 2025
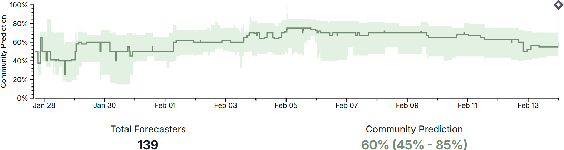
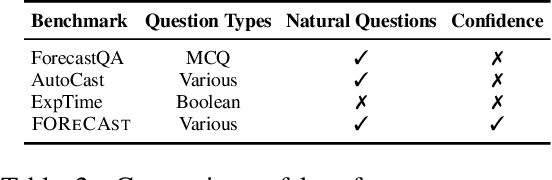
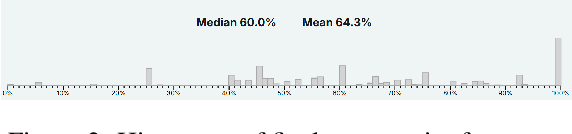
Forecasting is an important task in many domains, such as technology and economics. However existing forecasting benchmarks largely lack comprehensive confidence assessment, focus on limited question types, and often consist of artificial questions that do not align with real-world human forecasting needs. To address these gaps, we introduce FOReCAst (Future Outcome Reasoning and Confidence Assessment), a benchmark that evaluates models' ability to make predictions and their confidence in them. FOReCAst spans diverse forecasting scenarios involving Boolean questions, timeframe prediction, and quantity estimation, enabling a comprehensive evaluation of both prediction accuracy and confidence calibration for real-world applications.
PRobELM: Plausibility Ranking Evaluation for Language Models
Apr 04, 2024This paper introduces PRobELM (Plausibility Ranking Evaluation for Language Models), a benchmark designed to assess language models' ability to discern more plausible from less plausible scenarios through their parametric knowledge. While benchmarks such as TruthfulQA emphasise factual accuracy or truthfulness, and others such as COPA explore plausible scenarios without explicitly incorporating world knowledge, PRobELM seeks to bridge this gap by evaluating models' capabilities to prioritise plausible scenarios that leverage world knowledge over less plausible alternatives. This design allows us to assess the potential of language models for downstream use cases such as literature-based discovery where the focus is on identifying information that is likely but not yet known. Our benchmark is constructed from a dataset curated from Wikidata edit histories, tailored to align the temporal bounds of the training data for the evaluated models. PRobELM facilitates the evaluation of language models across multiple prompting types, including statement, text completion, and question-answering. Experiments with 10 models of various sizes and architectures on the relationship between model scales, training recency, and plausibility performance, reveal that factual accuracy does not directly correlate with plausibility performance and that up-to-date training data enhances plausibility assessment across different model architectures.
Language Models as Hierarchy Encoders
Jan 21, 2024Interpreting hierarchical structures latent in language is a key limitation of current language models (LMs). While previous research has implicitly leveraged these hierarchies to enhance LMs, approaches for their explicit encoding are yet to be explored. To address this, we introduce a novel approach to re-train transformer encoder-based LMs as Hierarchy Transformer encoders (HiTs), harnessing the expansive nature of hyperbolic space. Our method situates the output embedding space of pre-trained LMs within a Poincar\'e ball with a curvature that adapts to the embedding dimension, followed by re-training on hyperbolic cluster and centripetal losses. These losses are designed to effectively cluster related entities (input as texts) and organise them hierarchically. We evaluate HiTs against pre-trained and fine-tuned LMs, focusing on their capabilities in simulating transitive inference, predicting subsumptions, and transferring knowledge across hierarchies. The results demonstrate that HiTs consistently outperform both pre-trained and fine-tuned LMs in these tasks, underscoring the effectiveness and transferability of our re-trained hierarchy encoders.
DIALIGHT: Lightweight Multilingual Development and Evaluation of Task-Oriented Dialogue Systems with Large Language Models
Jan 04, 2024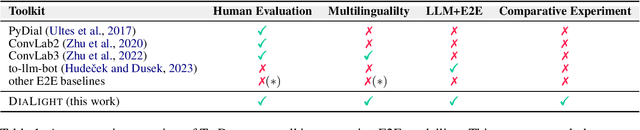
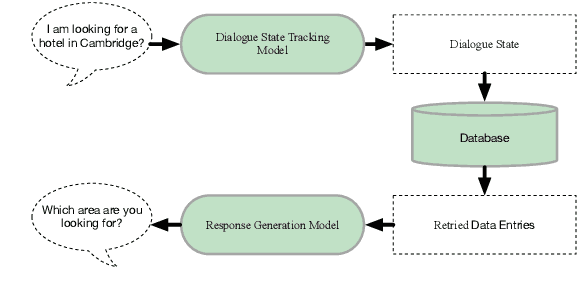
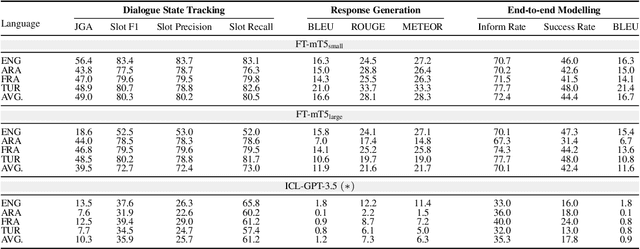
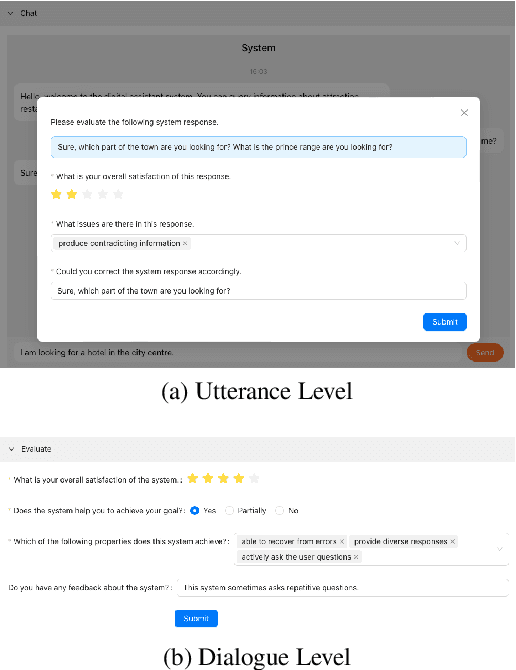
We present DIALIGHT, a toolkit for developing and evaluating multilingual Task-Oriented Dialogue (ToD) systems which facilitates systematic evaluations and comparisons between ToD systems using fine-tuning of Pretrained Language Models (PLMs) and those utilising the zero-shot and in-context learning capabilities of Large Language Models (LLMs). In addition to automatic evaluation, this toolkit features (i) a secure, user-friendly web interface for fine-grained human evaluation at both local utterance level and global dialogue level, and (ii) a microservice-based backend, improving efficiency and scalability. Our evaluations reveal that while PLM fine-tuning leads to higher accuracy and coherence, LLM-based systems excel in producing diverse and likeable responses. However, we also identify significant challenges of LLMs in adherence to task-specific instructions and generating outputs in multiple languages, highlighting areas for future research. We hope this open-sourced toolkit will serve as a valuable resource for researchers aiming to develop and properly evaluate multilingual ToD systems and will lower, currently still high, entry barriers in the field.
Zero-Shot Fact-Checking with Semantic Triples and Knowledge Graphs
Dec 19, 2023Despite progress in automated fact-checking, most systems require a significant amount of labeled training data, which is expensive. In this paper, we propose a novel zero-shot method, which instead of operating directly on the claim and evidence sentences, decomposes them into semantic triples augmented using external knowledge graphs, and uses large language models trained for natural language inference. This allows it to generalize to adversarial datasets and domains that supervised models require specific training data for. Our empirical results show that our approach outperforms previous zero-shot approaches on FEVER, FEVER-Symmetric, FEVER 2.0, and Climate-FEVER, while being comparable or better than supervised models on the adversarial and the out-of-domain datasets.
Can Pretrained Language Models (Yet) Reason Deductively?
Oct 12, 2022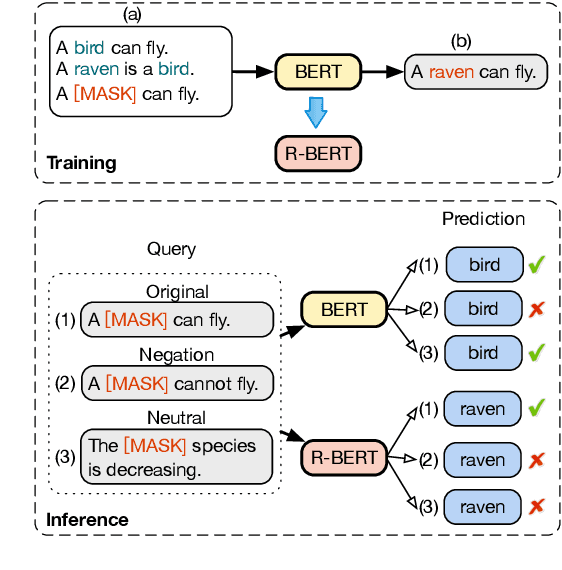

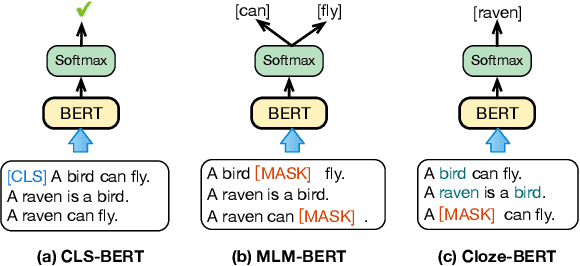
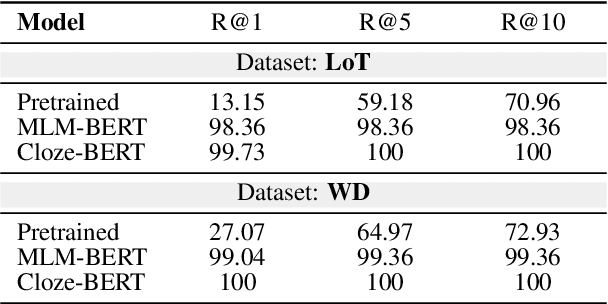
Acquiring factual knowledge with Pretrained Language Models (PLMs) has attracted increasing attention, showing promising performance in many knowledge-intensive tasks. Their good performance has led the community to believe that the models do possess a modicum of reasoning competence rather than merely memorising the knowledge. In this paper, we conduct a comprehensive evaluation of the learnable deductive (also known as explicit) reasoning capability of PLMs. Through a series of controlled experiments, we posit two main findings. (i) PLMs inadequately generalise learned logic rules and perform inconsistently against simple adversarial surface form edits. (ii) While the deductive reasoning fine-tuning of PLMs does improve their performance on reasoning over unseen knowledge facts, it results in catastrophically forgetting the previously learnt knowledge. Our main results suggest that PLMs cannot yet perform reliable deductive reasoning, demonstrating the importance of controlled examinations and probing of PLMs' reasoning abilities; we reach beyond (misleading) task performance, revealing that PLMs are still far from human-level reasoning capabilities, even for simple deductive tasks.