 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTabVer: Tabular Fact Verification with Natural Logic
Nov 02, 2024Fact verification on tabular evidence incentivises the use of symbolic reasoning models where a logical form is constructed (e.g. a LISP-style program), providing greater verifiability than fully neural approaches. However, these systems typically rely on well-formed tables, restricting their use in many scenarios. An emerging symbolic reasoning paradigm for textual evidence focuses on natural logic inference, which constructs proofs by modelling set-theoretic relations between a claim and its evidence in natural language. This approach provides flexibility and transparency but is less compatible with tabular evidence since the relations do not extend to arithmetic functions. We propose a set-theoretic interpretation of numerals and arithmetic functions in the context of natural logic, enabling the integration of arithmetic expressions in deterministic proofs. We leverage large language models to generate arithmetic expressions by generating questions about salient parts of a claim which are answered by executing appropriate functions on tables. In a few-shot setting on FEVEROUS, we achieve an accuracy of 71.4, outperforming both fully neural and symbolic reasoning models by 3.4 points. When evaluated on TabFact without any further training, our method remains competitive with an accuracy lead of 0.5 points.
The Automated Verification of Textual Claims (AVeriTeC) Shared Task
Oct 31, 2024



The Automated Verification of Textual Claims (AVeriTeC) shared task asks participants to retrieve evidence and predict veracity for real-world claims checked by fact-checkers. Evidence can be found either via a search engine, or via a knowledge store provided by the organisers. Submissions are evaluated using AVeriTeC score, which considers a claim to be accurately verified if and only if both the verdict is correct and retrieved evidence is considered to meet a certain quality threshold. The shared task received 21 submissions, 18 of which surpassed our baseline. The winning team was TUDA_MAI with an AVeriTeC score of 63%. In this paper we describe the shared task, present the full results, and highlight key takeaways from the shared task.
Zero-Shot Fact Verification via Natural Logic and Large Language Models
Oct 04, 2024The recent development of fact verification systems with natural logic has enhanced their explainability by aligning claims with evidence through set-theoretic operators, providing faithful justifications. Despite these advancements, such systems often rely on a large amount of training data annotated with natural logic. To address this issue, we propose a zero-shot method that utilizes the generalization capabilities of instruction-tuned large language models. To comprehensively assess the zero-shot capabilities of our method and other fact verification systems, we evaluate all models on both artificial and real-world claims, including multilingual datasets. We also compare our method against other fact verification systems in two setups. First, in the zero-shot generalization setup, we demonstrate that our approach outperforms other systems that were not specifically trained on natural logic data, achieving an average accuracy improvement of 8.96 points over the best-performing baseline. Second, in the zero-shot transfer setup, we show that current systems trained on natural logic data do not generalize well to other domains, and our method outperforms these systems across all datasets with real-world claims.
Learning to Generate Answers with Citations via Factual Consistency Models
Jun 19, 2024Large Language Models (LLMs) frequently hallucinate, impeding their reliability in mission-critical situations. One approach to address this issue is to provide citations to relevant sources alongside generated content, enhancing the verifiability of generations. However, citing passages accurately in answers remains a substantial challenge. This paper proposes a weakly-supervised fine-tuning method leveraging factual consistency models (FCMs). Our approach alternates between generating texts with citations and supervised fine-tuning with FCM-filtered citation data. Focused learning is integrated into the objective, directing the fine-tuning process to emphasise the factual unit tokens, as measured by an FCM. Results on the ALCE few-shot citation benchmark with various instruction-tuned LLMs demonstrate superior performance compared to in-context learning, vanilla supervised fine-tuning, and state-of-the-art methods, with an average improvement of $34.1$, $15.5$, and $10.5$ citation F$_1$ points, respectively. Moreover, in a domain transfer setting we show that the obtained citation generation ability robustly transfers to unseen datasets. Notably, our citation improvements contribute to the lowest factual error rate across baselines.
PRobELM: Plausibility Ranking Evaluation for Language Models
Apr 04, 2024This paper introduces PRobELM (Plausibility Ranking Evaluation for Language Models), a benchmark designed to assess language models' ability to discern more plausible from less plausible scenarios through their parametric knowledge. While benchmarks such as TruthfulQA emphasise factual accuracy or truthfulness, and others such as COPA explore plausible scenarios without explicitly incorporating world knowledge, PRobELM seeks to bridge this gap by evaluating models' capabilities to prioritise plausible scenarios that leverage world knowledge over less plausible alternatives. This design allows us to assess the potential of language models for downstream use cases such as literature-based discovery where the focus is on identifying information that is likely but not yet known. Our benchmark is constructed from a dataset curated from Wikidata edit histories, tailored to align the temporal bounds of the training data for the evaluated models. PRobELM facilitates the evaluation of language models across multiple prompting types, including statement, text completion, and question-answering. Experiments with 10 models of various sizes and architectures on the relationship between model scales, training recency, and plausibility performance, reveal that factual accuracy does not directly correlate with plausibility performance and that up-to-date training data enhances plausibility assessment across different model architectures.
QA-NatVer: Question Answering for Natural Logic-based Fact Verification
Oct 22, 2023Fact verification systems assess a claim's veracity based on evidence. An important consideration in designing them is faithfulness, i.e. generating explanations that accurately reflect the reasoning of the model. Recent works have focused on natural logic, which operates directly on natural language by capturing the semantic relation of spans between an aligned claim with its evidence via set-theoretic operators. However, these approaches rely on substantial resources for training, which are only available for high-resource languages. To this end, we propose to use question answering to predict natural logic operators, taking advantage of the generalization capabilities of instruction-tuned language models. Thus, we obviate the need for annotated training data while still relying on a deterministic inference system. In a few-shot setting on FEVER, our approach outperforms the best baseline by $4.3$ accuracy points, including a state-of-the-art pre-trained seq2seq natural logic system, as well as a state-of-the-art prompt-based classifier. Our system demonstrates its robustness and portability, achieving competitive performance on a counterfactual dataset and surpassing all approaches without further annotation on a Danish verification dataset. A human evaluation indicates that our approach produces more plausible proofs with fewer erroneous natural logic operators than previous natural logic-based systems.
Automated Few-shot Classification with Instruction-Finetuned Language Models
May 21, 2023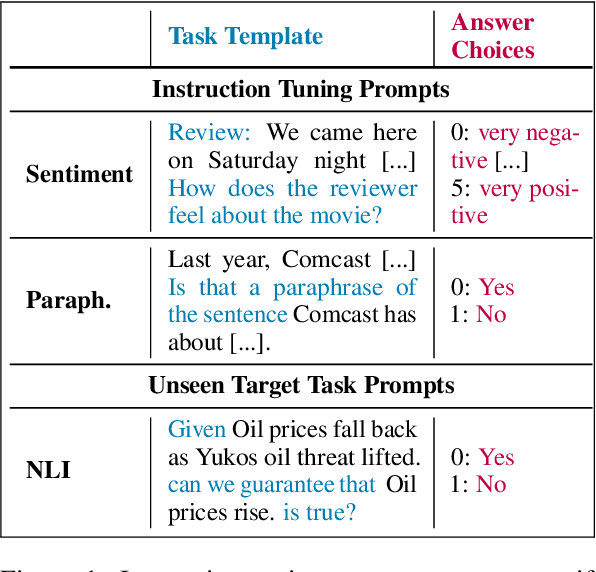

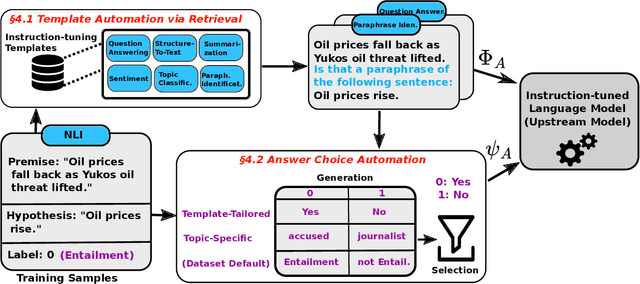
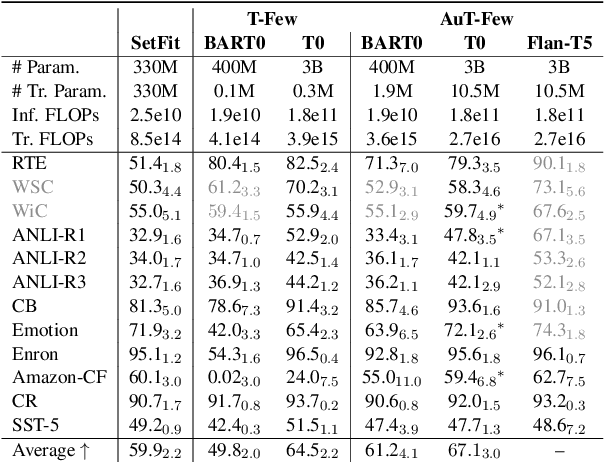
A particularly successful class of approaches for few-shot learning combines language models with prompts -- hand-crafted task descriptions that complement data samples. However, designing prompts by hand for each task commonly requires domain knowledge and substantial guesswork. We observe, in the context of classification tasks, that instruction finetuned language models exhibit remarkable prompt robustness, and we subsequently propose a simple method to eliminate the need for handcrafted prompts, named AuT-Few. This approach consists of (i) a prompt retrieval module that selects suitable task instructions from the instruction-tuning knowledge base, and (ii) the generation of two distinct, semantically meaningful, class descriptions and a selection mechanism via cross-validation. Over $12$ datasets, spanning $8$ classification tasks, we show that AuT-Few outperforms current state-of-the-art few-shot learning methods. Moreover, AuT-Few is the best ranking method across datasets on the RAFT few-shot benchmark. Notably, these results are achieved without task-specific handcrafted prompts on unseen tasks.
Natural Logic-guided Autoregressive Multi-hop Document Retrieval for Fact Verification
Dec 10, 2022A key component of fact verification is thevevidence retrieval, often from multiple documents. Recent approaches use dense representations and condition the retrieval of each document on the previously retrieved ones. The latter step is performed over all the documents in the collection, requiring storing their dense representations in an index, thus incurring a high memory footprint. An alternative paradigm is retrieve-and-rerank, where documents are retrieved using methods such as BM25, their sentences are reranked, and further documents are retrieved conditioned on these sentences, reducing the memory requirements. However, such approaches can be brittle as they rely on heuristics and assume hyperlinks between documents. We propose a novel retrieve-and-rerank method for multi-hop retrieval, that consists of a retriever that jointly scores documents in the knowledge source and sentences from previously retrieved documents using an autoregressive formulation and is guided by a proof system based on natural logic that dynamically terminates the retrieval process if the evidence is deemed sufficient. This method is competitive with current state-of-the-art methods on FEVER, HoVer and FEVEROUS-S, while using $5$ to $10$ times less memory than competing systems. Evaluation on an adversarial dataset indicates improved stability of our approach compared to commonly deployed threshold-based methods. Finally, the proof system helps humans predict model decisions correctly more often than using the evidence alone.
FEVEROUS: Fact Extraction and VERification Over Unstructured and Structured information
Jun 10, 2021
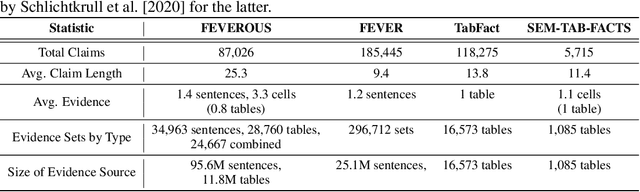
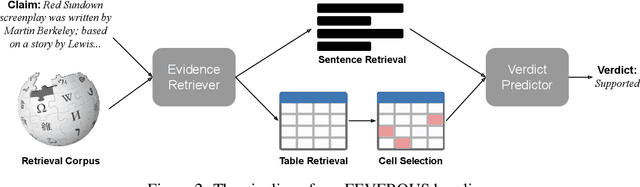
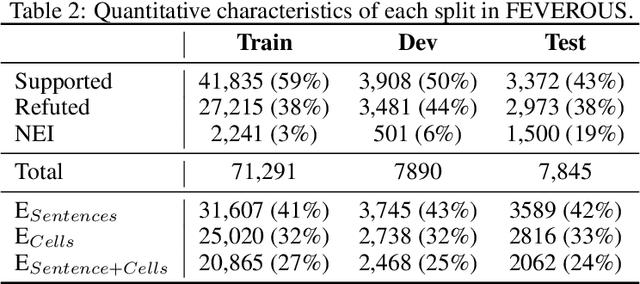
Fact verification has attracted a lot of attention in the machine learning and natural language processing communities, as it is one of the key methods for detecting misinformation. Existing large-scale benchmarks for this task have focused mostly on textual sources, i.e. unstructured information, and thus ignored the wealth of information available in structured formats, such as tables. In this paper we introduce a novel dataset and benchmark, Fact Extraction and VERification Over Unstructured and Structured information (FEVEROUS), which consists of 87,026 verified claims. Each claim is annotated with evidence in the form of sentences and/or cells from tables in Wikipedia, as well as a label indicating whether this evidence supports, refutes, or does not provide enough information to reach a verdict. Furthermore, we detail our efforts to track and minimize the biases present in the dataset and could be exploited by models, e.g. being able to predict the label without using evidence. Finally, we develop a baseline for verifying claims against text and tables which predicts both the correct evidence and verdict for 18% of the claims.
Every child should have parents: a taxonomy refinement algorithm based on hyperbolic term embeddings
Jun 05, 2019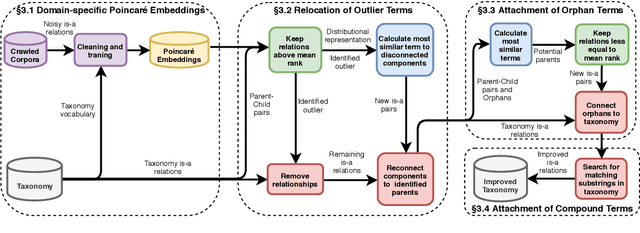

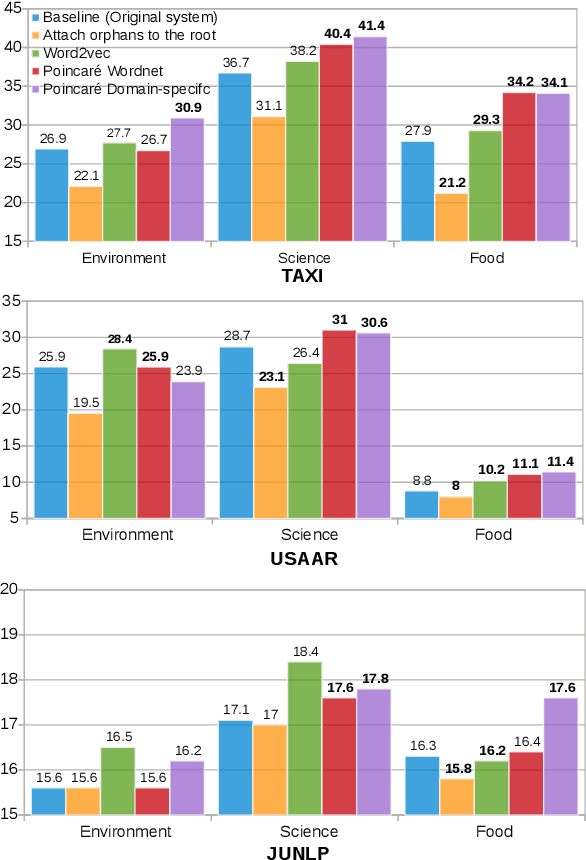
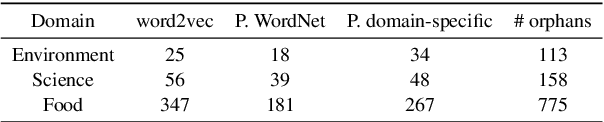
We introduce the use of Poincar\'e embeddings to improve existing state-of-the-art approaches to domain-specific taxonomy induction from text as a signal for both relocating wrong hyponym terms within a (pre-induced) taxonomy as well as for attaching disconnected terms in a taxonomy. This method substantially improves previous state-of-the-art results on the SemEval-2016 Task 13 on taxonomy extraction. We demonstrate the superiority of Poincar\'e embeddings over distributional semantic representations, supporting the hypothesis that they can better capture hierarchical lexical-semantic relationships than embeddings in the Euclidean space.