 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerating Instructions at Different Levels of Abstraction
Oct 08, 2020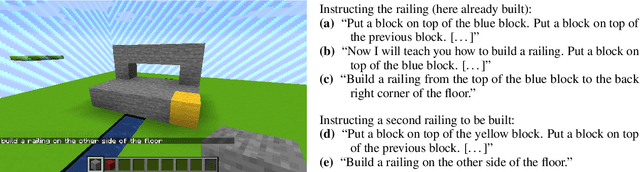
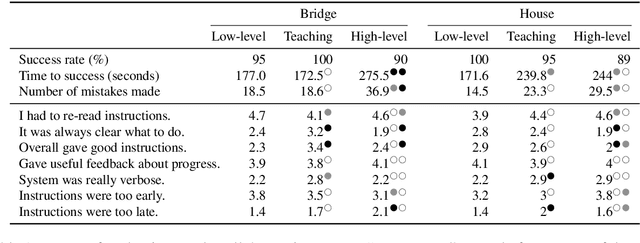


When generating technical instructions, it is often convenient to describe complex objects in the world at different levels of abstraction. A novice user might need an object explained piece by piece, while for an expert, talking about the complex object (e.g. a wall or railing) directly may be more succinct and efficient. We show how to generate building instructions at different levels of abstraction in Minecraft. We introduce the use of hierarchical planning to this end, a method from AI planning which can capture the structure of complex objects neatly. A crowdsourcing evaluation shows that the choice of abstraction level matters to users, and that an abstraction strategy which balances low-level and high-level object descriptions compares favorably to ones which don't.
Adversarial Learning of Privacy-Preserving Text Representations for De-Identification of Medical Records
Jun 12, 2019
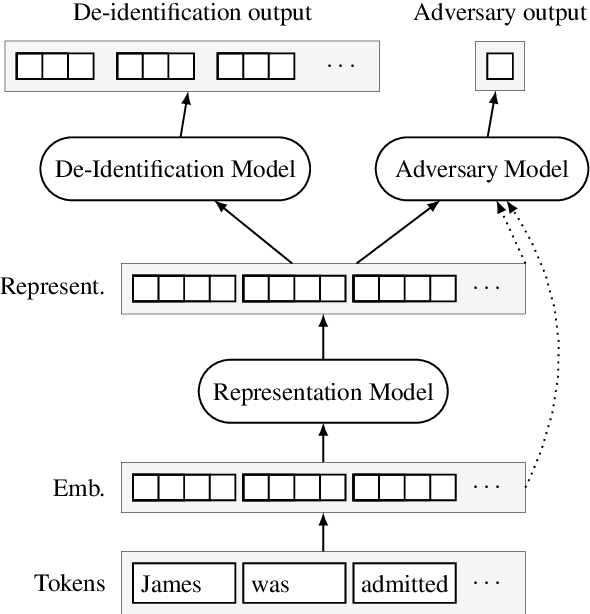
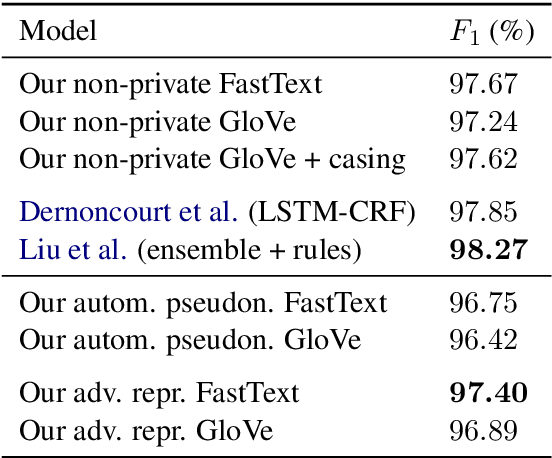
De-identification is the task of detecting protected health information (PHI) in medical text. It is a critical step in sanitizing electronic health records (EHRs) to be shared for research. Automatic de-identification classifierscan significantly speed up the sanitization process. However, obtaining a large and diverse dataset to train such a classifier that works wellacross many types of medical text poses a challenge as privacy laws prohibit the sharing of raw medical records. We introduce a method to create privacy-preserving shareable representations of medical text (i.e. they contain no PHI) that does not require expensive manual pseudonymization. These representations can be shared between organizations to create unified datasets for training de-identification models. Our representation allows training a simple LSTM-CRF de-identification model to an F1 score of 97.4%, which is comparable to a strong baseline that exposes private information in its representation. A robust, widely available de-identification classifier based on our representation could potentially enable studies for which de-identification would otherwise be too costly.
Every child should have parents: a taxonomy refinement algorithm based on hyperbolic term embeddings
Jun 05, 2019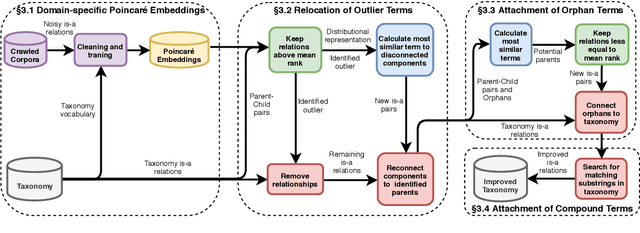

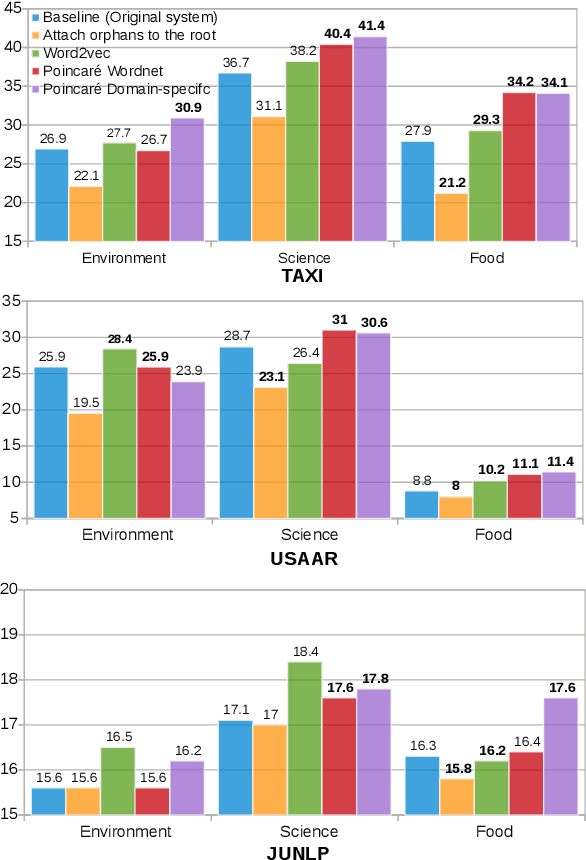
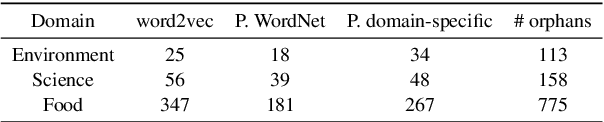
We introduce the use of Poincar\'e embeddings to improve existing state-of-the-art approaches to domain-specific taxonomy induction from text as a signal for both relocating wrong hyponym terms within a (pre-induced) taxonomy as well as for attaching disconnected terms in a taxonomy. This method substantially improves previous state-of-the-art results on the SemEval-2016 Task 13 on taxonomy extraction. We demonstrate the superiority of Poincar\'e embeddings over distributional semantic representations, supporting the hypothesis that they can better capture hierarchical lexical-semantic relationships than embeddings in the Euclidean space.
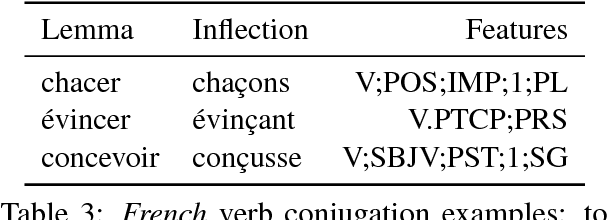
Finding the way from ä to a: Sub-character morphological inflection for the SIGMORPHON 2018 Shared Task
Sep 15, 2018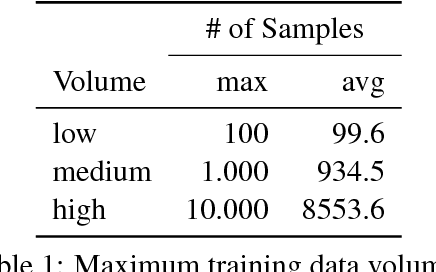


In this paper we describe the system submitted by UHH to the CoNLL--SIGMORPHON 2018 Shared Task: Universal Morphological Reinflection. We propose a neural architecture based on the concepts of UZH (Makarov et al., 2017), adding new ideas and techniques to their key concept and evaluating different combinations of parameters. The resulting system is a language-agnostic network model that aims to reduce the number of learned edit operations by introducing equivalence classes over graphical features of individual characters. We try to pinpoint advantages and drawbacks of this approach by comparing different network configurations and evaluating our results over a wide range of languages.
Open Source Automatic Speech Recognition for German
Jul 26, 2018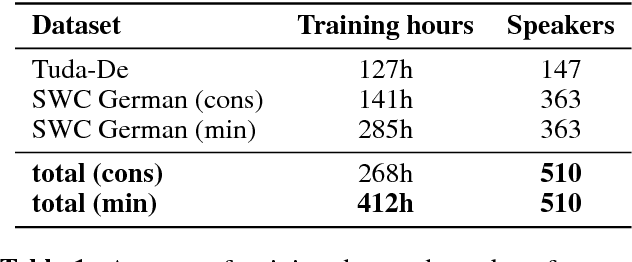
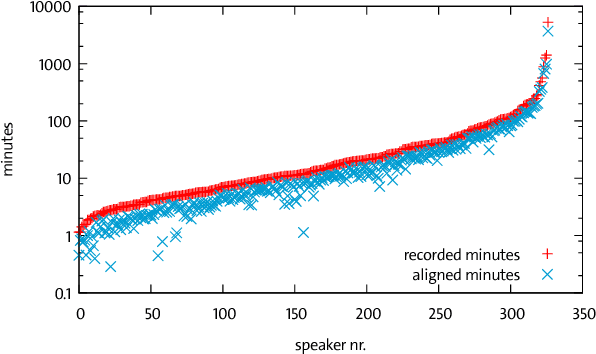
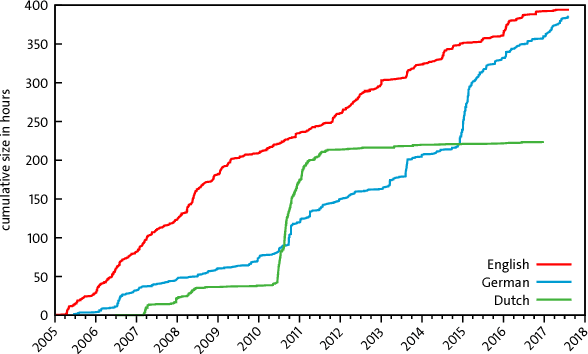
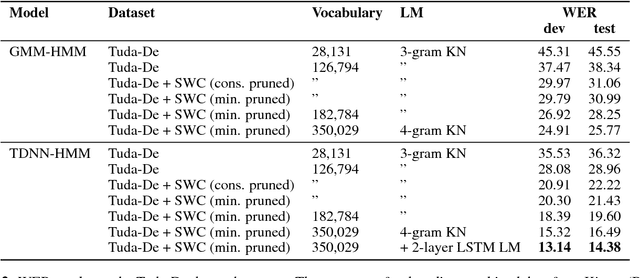
High quality Automatic Speech Recognition (ASR) is a prerequisite for speech-based applications and research. While state-of-the-art ASR software is freely available, the language dependent acoustic models are lacking for languages other than English, due to the limited amount of freely available training data. We train acoustic models for German with Kaldi on two datasets, which are both distributed under a Creative Commons license. The resulting model is freely redistributable, lowering the cost of entry for German ASR. The models are trained on a total of 412 hours of German read speech data and we achieve a relative word error reduction of 26% by adding data from the Spoken Wikipedia Corpus to the previously best freely available German acoustic model recipe and dataset. Our best model achieves a word error rate of 14.38 on the Tuda-De test set. Due to the large amount of speakers and the diversity of topics included in the training data, our model is robust against speaker variation and topic shift.
An Empirical Analysis of the Correlation of Syntax and Prosody
Jun 15, 2018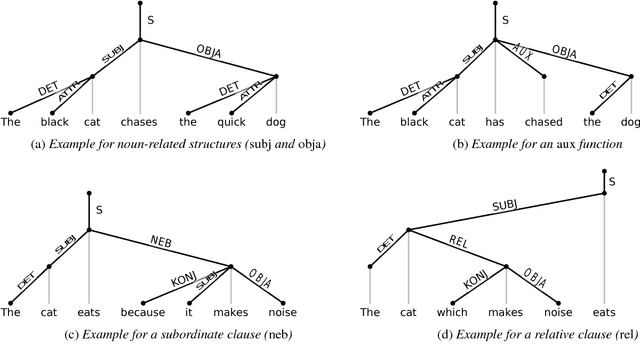
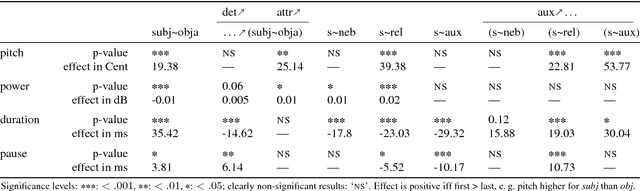
The relation of syntax and prosody (the syntax--prosody interface) has been an active area of research, mostly in linguistics and typically studied under controlled conditions. More recently, prosody has also been successfully used in the data-based training of syntax parsers. However, there is a gap between the controlled and detailed study of the individual effects between syntax and prosody and the large-scale application of prosody in syntactic parsing with only a shallow analysis of the respective influences. In this paper, we close the gap by investigating the significance of correlations of prosodic realization with specific syntactic functions using linear mixed effects models in a very large corpus of read-out German encyclopedic texts. Using this corpus, we are able to analyze prosodic structuring performed by a diverse set of speakers while they try to optimize factual content delivery. After normalization by speaker, we obtain significant effects, e.g. confirming that the subject function, as compared to the object function, has a positive effect on pitch and duration of a word, but a negative effect on loudness.
Incremental Natural Language Processing: Challenges, Strategies, and Evaluation
Jun 14, 2018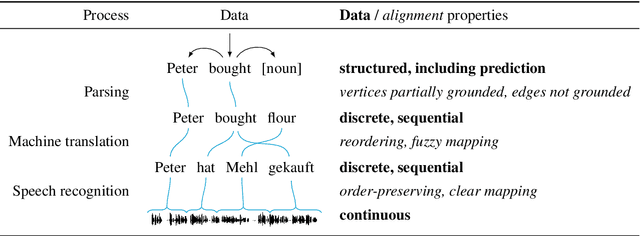


Incrementality is ubiquitous in human-human interaction and beneficial for human-computer interaction. It has been a topic of research in different parts of the NLP community, mostly with focus on the specific topic at hand even though incremental systems have to deal with similar challenges regardless of domain. In this survey, I consolidate and categorize the approaches, identifying similarities and differences in the computation and data, and show trade-offs that have to be considered. A focus lies on evaluating incremental systems because the standard metrics often fail to capture the incremental properties of a system and coming up with a suitable evaluation scheme is non-trivial.