 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeControlled Diversity: Length-optimized Natural Language Generation
Feb 26, 2025LLMs are not generally able to adjust the length of their outputs based on strict length requirements, a capability that would improve their usefulness in applications that require adherence to diverse user and system requirements. We present an approach to train LLMs to acquire this capability by augmenting existing data and applying existing fine-tuning techniques, which we compare based on the trained models' adherence to the length requirement and overall response quality relative to the baseline model. Our results demonstrate that these techniques can be successfully applied to train LLMs to adhere to length requirements, with the trained models generating texts which better align to the length requirements. Our results indicate that our method may change the response quality when using training data that was not generated by the baseline model. This allows simultaneous alignment to another training objective in certain scenarios, but is undesirable otherwise. Training on a dataset containing the model's own responses eliminates this issue.
Merkel Podcast Corpus: A Multimodal Dataset Compiled from 16 Years of Angela Merkel's Weekly Video Podcasts
May 24, 2022
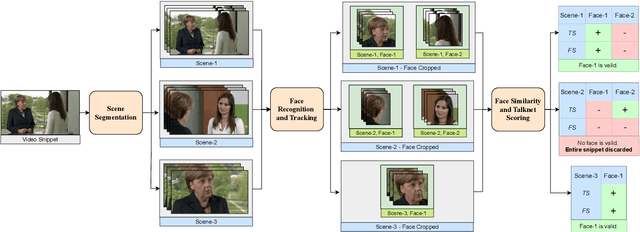
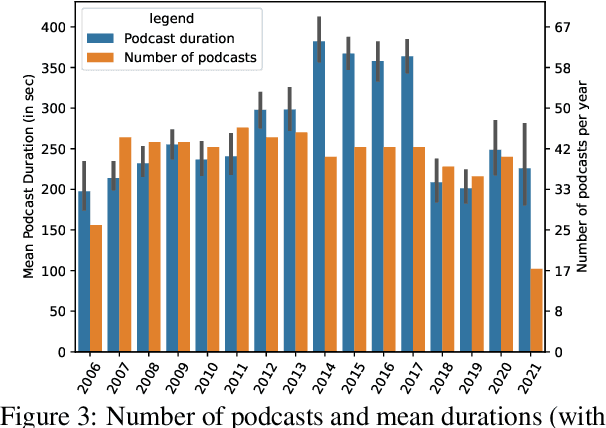
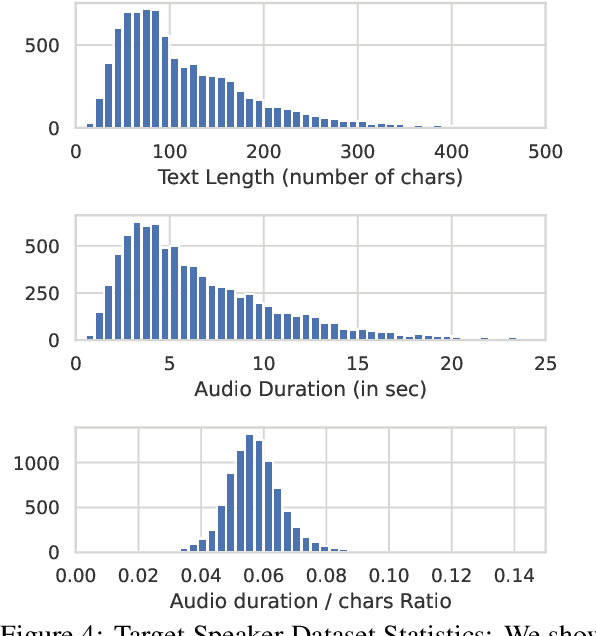
We introduce the Merkel Podcast Corpus, an audio-visual-text corpus in German collected from 16 years of (almost) weekly Internet podcasts of former German chancellor Angela Merkel. To the best of our knowledge, this is the first single speaker corpus in the German language consisting of audio, visual and text modalities of comparable size and temporal extent. We describe the methods used with which we have collected and edited the data which involves downloading the videos, transcripts and other metadata, forced alignment, performing active speaker recognition and face detection to finally curate the single speaker dataset consisting of utterances spoken by Angela Merkel. The proposed pipeline is general and can be used to curate other datasets of similar nature, such as talk show contents. Through various statistical analyses and applications of the dataset in talking face generation and TTS, we show the utility of the dataset. We argue that it is a valuable contribution to the research community, in particular, due to its realistic and challenging material at the boundary between prepared and spontaneous speech.
An Empirical Analysis of the Correlation of Syntax and Prosody
Jun 15, 2018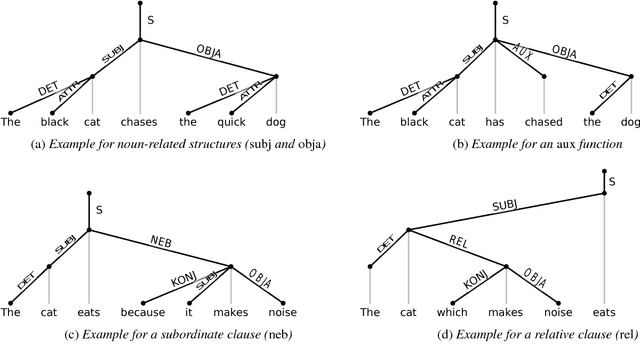
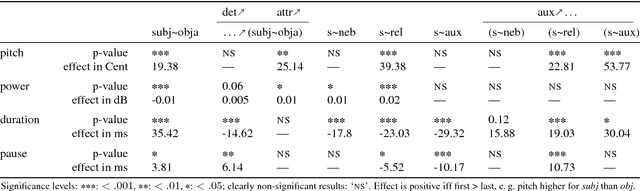
The relation of syntax and prosody (the syntax--prosody interface) has been an active area of research, mostly in linguistics and typically studied under controlled conditions. More recently, prosody has also been successfully used in the data-based training of syntax parsers. However, there is a gap between the controlled and detailed study of the individual effects between syntax and prosody and the large-scale application of prosody in syntactic parsing with only a shallow analysis of the respective influences. In this paper, we close the gap by investigating the significance of correlations of prosodic realization with specific syntactic functions using linear mixed effects models in a very large corpus of read-out German encyclopedic texts. Using this corpus, we are able to analyze prosodic structuring performed by a diverse set of speakers while they try to optimize factual content delivery. After normalization by speaker, we obtain significant effects, e.g. confirming that the subject function, as compared to the object function, has a positive effect on pitch and duration of a word, but a negative effect on loudness.