 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMerkel Podcast Corpus: A Multimodal Dataset Compiled from 16 Years of Angela Merkel's Weekly Video Podcasts
May 24, 2022
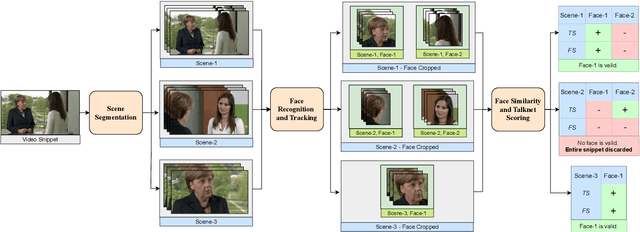
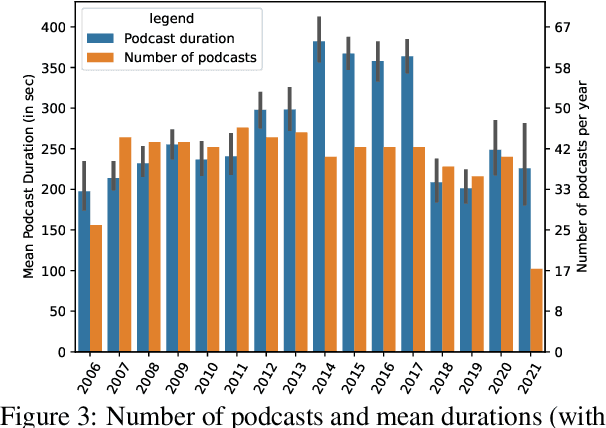
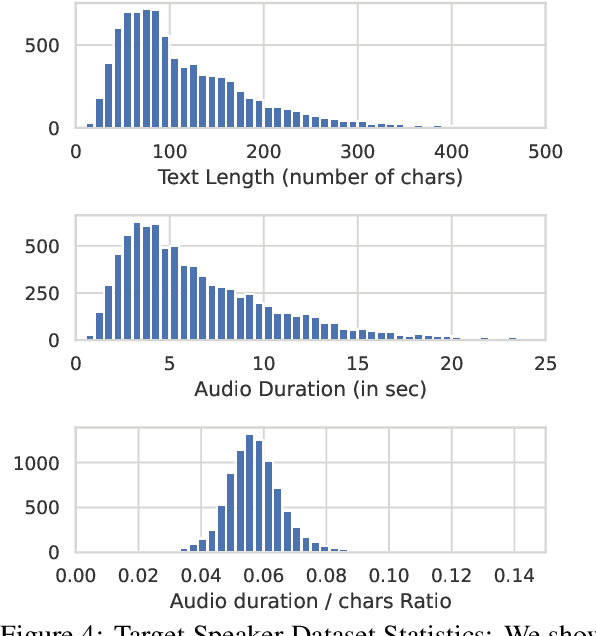
We introduce the Merkel Podcast Corpus, an audio-visual-text corpus in German collected from 16 years of (almost) weekly Internet podcasts of former German chancellor Angela Merkel. To the best of our knowledge, this is the first single speaker corpus in the German language consisting of audio, visual and text modalities of comparable size and temporal extent. We describe the methods used with which we have collected and edited the data which involves downloading the videos, transcripts and other metadata, forced alignment, performing active speaker recognition and face detection to finally curate the single speaker dataset consisting of utterances spoken by Angela Merkel. The proposed pipeline is general and can be used to curate other datasets of similar nature, such as talk show contents. Through various statistical analyses and applications of the dataset in talking face generation and TTS, we show the utility of the dataset. We argue that it is a valuable contribution to the research community, in particular, due to its realistic and challenging material at the boundary between prepared and spontaneous speech.
A Study on Prompt-based Few-Shot Learning Methods for Belief State Tracking in Task-oriented Dialog Systems
Apr 18, 2022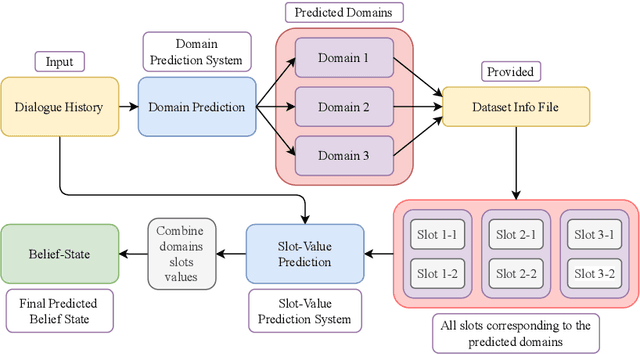
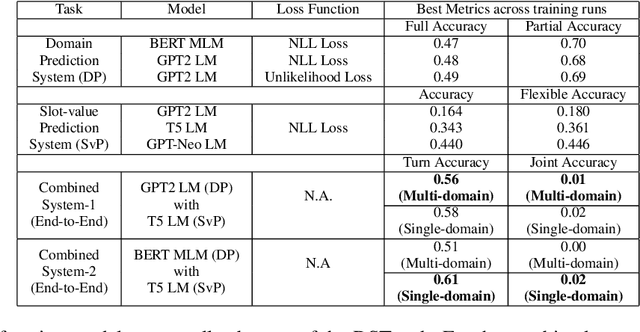
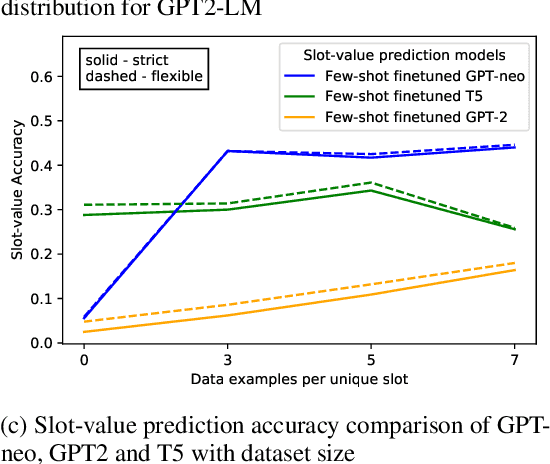
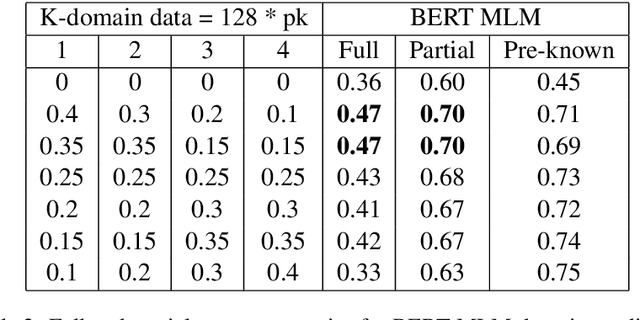
We tackle the Dialogue Belief State Tracking(DST) problem of task-oriented conversational systems. Recent approaches to this problem leveraging Transformer-based models have yielded great results. However, training these models is expensive, both in terms of computational resources and time. Additionally, collecting high quality annotated dialogue datasets remains a challenge for researchers because of the extensive annotation required for training these models. Driven by the recent success of pre-trained language models and prompt-based learning, we explore prompt-based few-shot learning for Dialogue Belief State Tracking. We formulate the DST problem as a 2-stage prompt-based language modelling task and train language models for both tasks and present a comprehensive empirical analysis of their separate and joint performance. We demonstrate the potential of prompt-based methods in few-shot learning for DST and provide directions for future improvement.
Hate-Alert@DravidianLangTech-EACL2021: Ensembling strategies for Transformer-based Offensive language Detection
Feb 19, 2021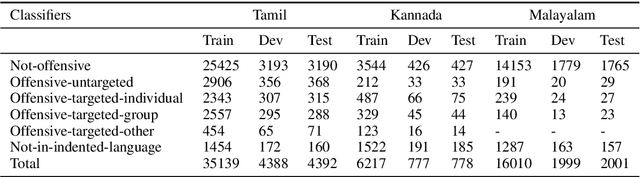
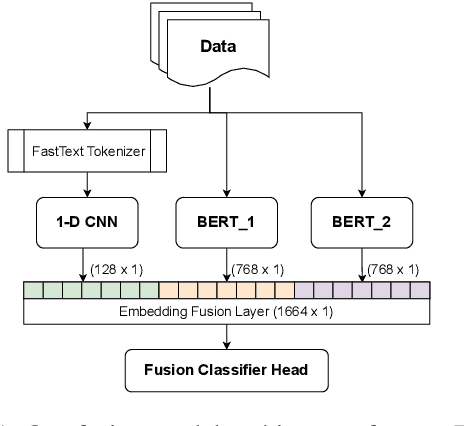
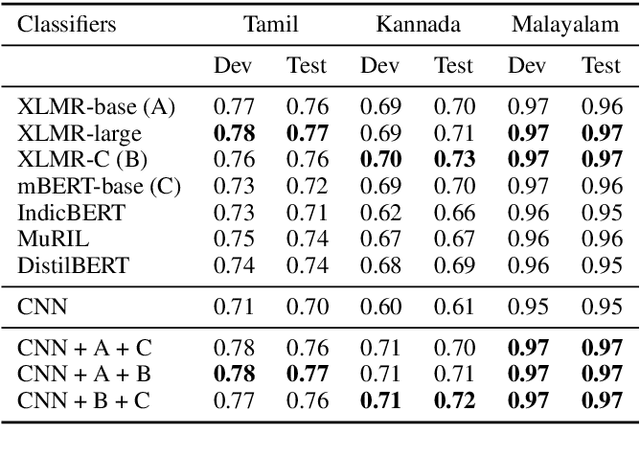
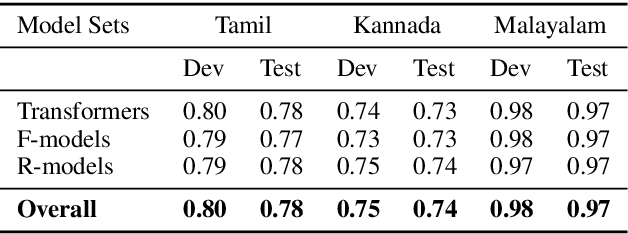
Social media often acts as breeding grounds for different forms of offensive content. For low resource languages like Tamil, the situation is more complex due to the poor performance of multilingual or language-specific models and lack of proper benchmark datasets. Based on this shared task, Offensive Language Identification in Dravidian Languages at EACL 2021, we present an exhaustive exploration of different transformer models, We also provide a genetic algorithm technique for ensembling different models. Our ensembled models trained separately for each language secured the first position in Tamil, the second position in Kannada, and the first position in Malayalam sub-tasks. The models and codes are provided.