 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChange Summarization of Diachronic Scholarly Paper Collections by Semantic Evolution Analysis
Dec 07, 2021


The amount of scholarly data has been increasing dramatically over the last years. For newcomers to a particular science domain (e.g., IR, physics, NLP) it is often difficult to spot larger trends and to position the latest research in the context of prior scientific achievements and breakthroughs. Similarly, researchers in the history of science are interested in tools that allow them to analyze and visualize changes in particular scientific domains. Temporal summarization and related methods should be then useful for making sense of large volumes of scientific discourse data aggregated over time. We demonstrate a novel approach to analyze the collections of research papers published over longer time periods to provide a high-level overview of important semantic changes that occurred over the progress of time. Our approach is based on comparing word semantic representations over time and aims to support users in a better understanding of large domain-focused archives of scholarly publications. As an example dataset we use the ACL Anthology Reference Corpus that spans from 1979 to 2015 and contains 22,878 scholarly articles.
Hate-Alert@DravidianLangTech-EACL2021: Ensembling strategies for Transformer-based Offensive language Detection
Feb 19, 2021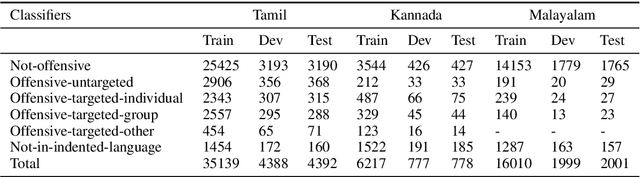
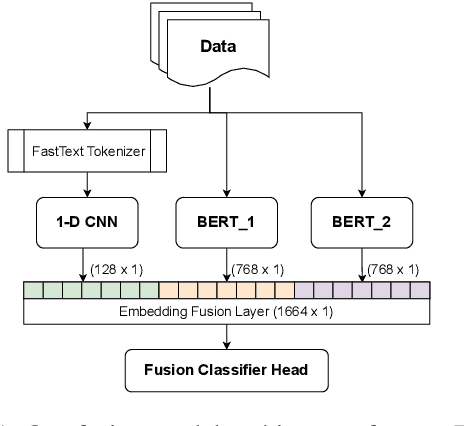
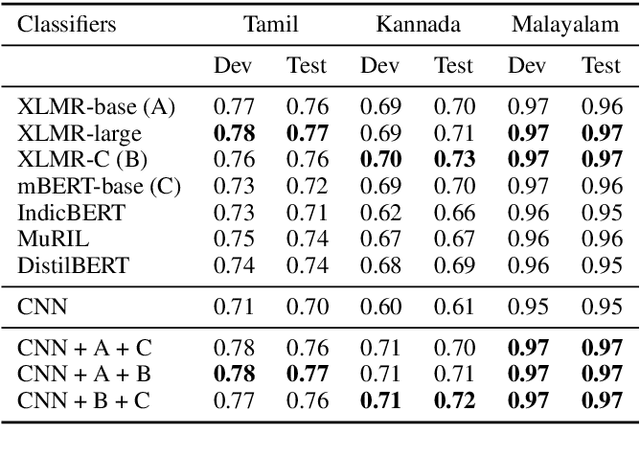
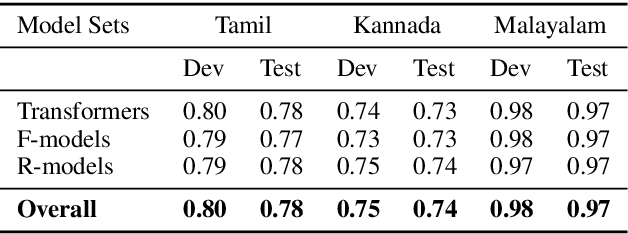
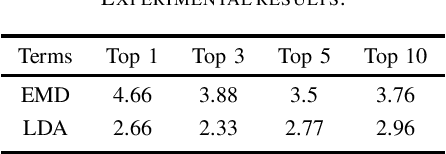
Social media often acts as breeding grounds for different forms of offensive content. For low resource languages like Tamil, the situation is more complex due to the poor performance of multilingual or language-specific models and lack of proper benchmark datasets. Based on this shared task, Offensive Language Identification in Dravidian Languages at EACL 2021, we present an exhaustive exploration of different transformer models, We also provide a genetic algorithm technique for ensembling different models. Our ensembled models trained separately for each language secured the first position in Tamil, the second position in Kannada, and the first position in Malayalam sub-tasks. The models and codes are provided.