 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Unsupervised Sparsespeech Acoustic Models with Categorical Reparameterization
May 29, 2020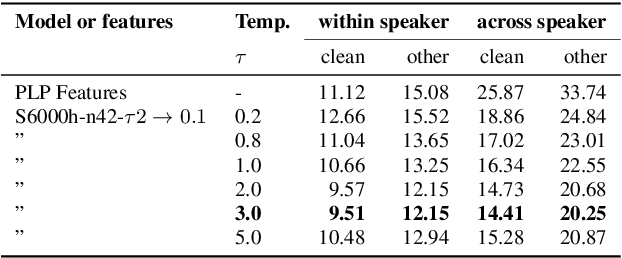
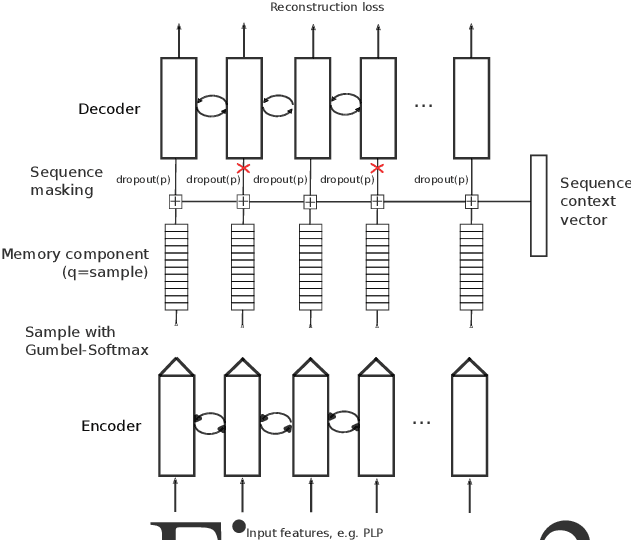
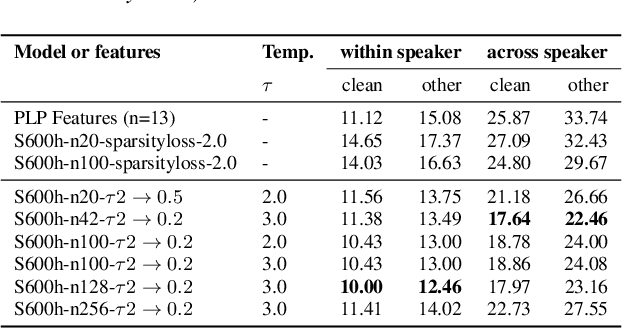
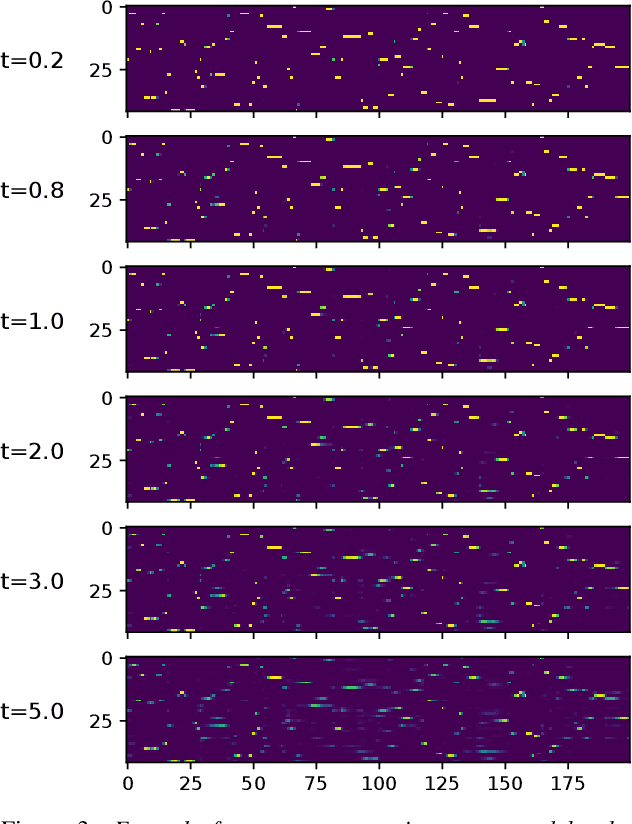
The Sparsespeech model is an unsupervised acoustic model that can generate discrete pseudo-labels for untranscribed speech. We extend the Sparsespeech model to allow for sampling over a random discrete variable, yielding pseudo-posteriorgrams. The degree of sparsity in this posteriorgram can be fully controlled after the model has been trained. We use the Gumbel-Softmax trick to approximately sample from a discrete distribution in the neural network and this allows us to train the network efficiently with standard backpropagation. The new and improved model is trained and evaluated on the Libri-Light corpus, a benchmark for ASR with limited or no supervision. The model is trained on 600h and 6000h of English read speech. We evaluate the improved model using the ABX error measure and a semi-supervised setting with 10h of transcribed speech. We observe a relative improvement of up to 31.4% on ABX error rates across speakers on the test set with the improved Sparsespeech model on 600h of speech data and further improvements when we scale the model to 6000h.
Unspeech: Unsupervised Speech Context Embeddings
Aug 23, 2018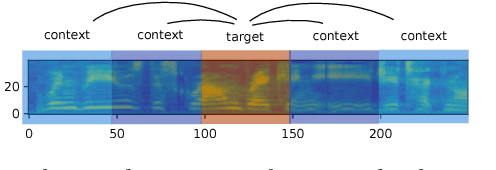
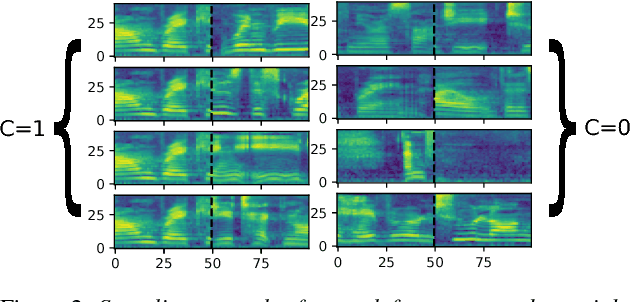
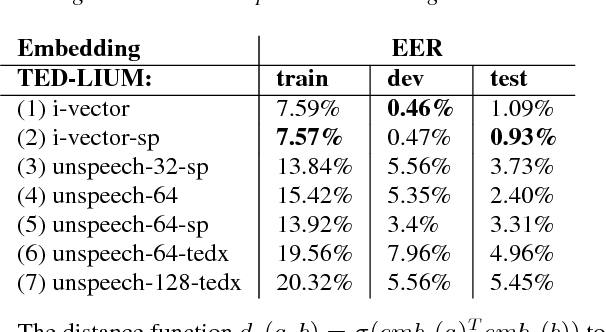
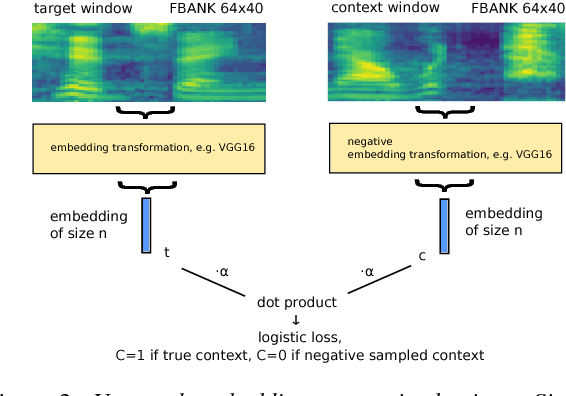
We introduce "Unspeech" embeddings, which are based on unsupervised learning of context feature representations for spoken language. The embeddings were trained on up to 9500 hours of crawled English speech data without transcriptions or speaker information, by using a straightforward learning objective based on context and non-context discrimination with negative sampling. We use a Siamese convolutional neural network architecture to train Unspeech embeddings and evaluate them on speaker comparison, utterance clustering and as a context feature in TDNN-HMM acoustic models trained on TED-LIUM, comparing it to i-vector baselines. Particularly decoding out-of-domain speech data from the recently released Common Voice corpus shows consistent WER reductions. We release our source code and pre-trained Unspeech models under a permissive open source license.
Open Source Automatic Speech Recognition for German
Jul 26, 2018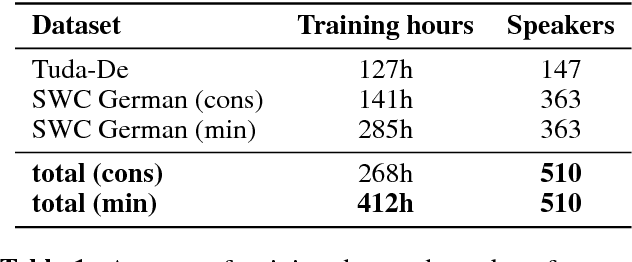
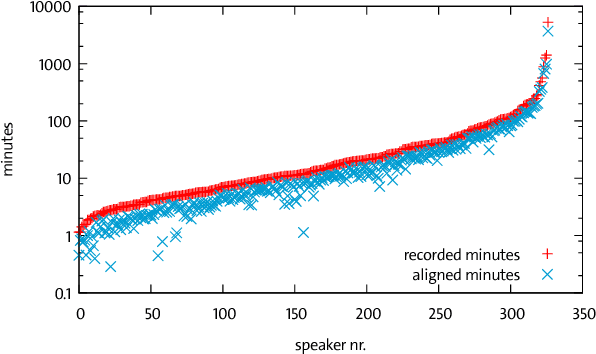
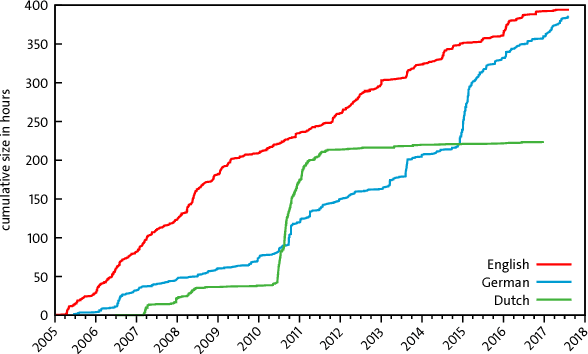
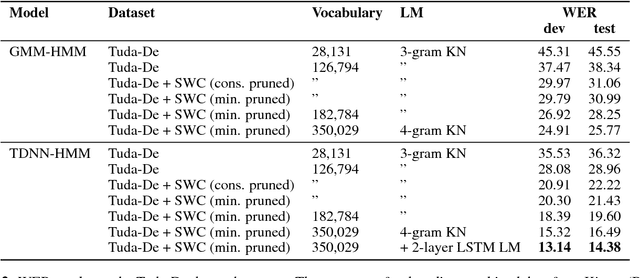
High quality Automatic Speech Recognition (ASR) is a prerequisite for speech-based applications and research. While state-of-the-art ASR software is freely available, the language dependent acoustic models are lacking for languages other than English, due to the limited amount of freely available training data. We train acoustic models for German with Kaldi on two datasets, which are both distributed under a Creative Commons license. The resulting model is freely redistributable, lowering the cost of entry for German ASR. The models are trained on a total of 412 hours of German read speech data and we achieve a relative word error reduction of 26% by adding data from the Spoken Wikipedia Corpus to the previously best freely available German acoustic model recipe and dataset. Our best model achieves a word error rate of 14.38 on the Tuda-De test set. Due to the large amount of speakers and the diversity of topics included in the training data, our model is robust against speaker variation and topic shift.