 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePer-Domain Generalizing Policies: On Learning Efficient and Robust Q-Value Functions (Extended Version with Technical Appendix)
Mar 18, 2026Learning per-domain generalizing policies is a key challenge in learning for planning. Standard approaches learn state-value functions represented as graph neural networks using supervised learning on optimal plans generated by a teacher planner. In this work, we advocate for learning Q-value functions instead. Such policies are drastically cheaper to evaluate for a given state, as they need to process only the current state rather than every successor. Surprisingly, vanilla supervised learning of Q-values performs poorly as it does not learn to distinguish between the actions taken and those not taken by the teacher. We address this by using regularization terms that enforce this distinction, resulting in Q-value policies that consistently outperform state-value policies across a range of 10 domains and are competitive with the planner LAMA-first.
Intelligent support for Human Oversight: Integrating Reinforcement Learning with Gaze Simulation to Personalize Highlighting
Feb 09, 2026Interfaces for human oversight must effectively support users' situation awareness under time-critical conditions. We explore reinforcement learning (RL)-based UI adaptation to personalize alerting strategies that balance the benefits of highlighting critical events against the cognitive costs of interruptions. To enable learning without real-world deployment, we integrate models of users' gaze behavior to simulate attentional dynamics during monitoring. Using a delivery-drone oversight scenario, we present initial results suggesting that RL-based highlighting can outperform static, rule-based approaches and discuss challenges of intelligent oversight support.
Per-Domain Generalizing Policies: On Validation Instances and Scaling Behavior
May 01, 2025Recent work has shown that successful per-domain generalizing action policies can be learned. Scaling behavior, from small training instances to large test instances, is the key objective; and the use of validation instances larger than training instances is one key to achieve it. Prior work has used fixed validation sets. Here, we introduce a method generating the validation set dynamically, on the fly, increasing instance size so long as informative and feasible.We also introduce refined methodology for evaluating scaling behavior, generating test instances systematically to guarantee a given confidence in coverage performance for each instance size. In experiments, dynamic validation improves scaling behavior of GNN policies in all 9 domains used.
Specifying and Testing $k$-Safety Properties for Machine-Learning Models
Jun 13, 2022
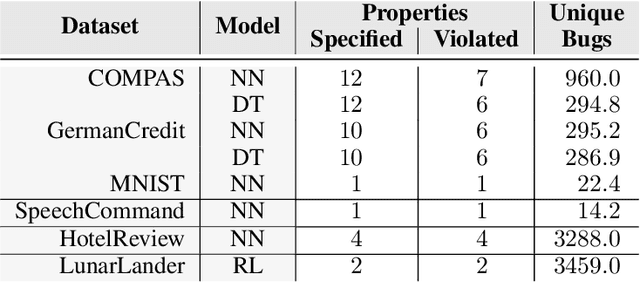

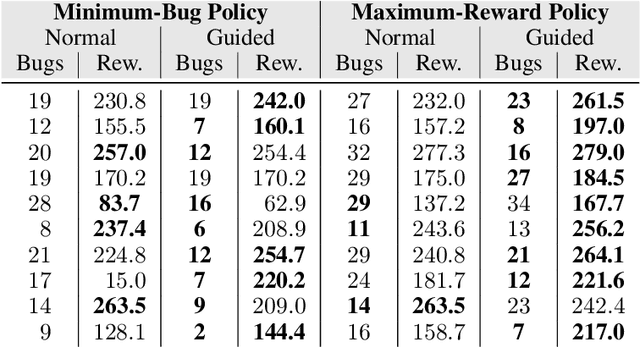
Machine-learning models are becoming increasingly prevalent in our lives, for instance assisting in image-classification or decision-making tasks. Consequently, the reliability of these models is of critical importance and has resulted in the development of numerous approaches for validating and verifying their robustness and fairness. However, beyond such specific properties, it is challenging to specify, let alone check, general functional-correctness expectations from models. In this paper, we take inspiration from specifications used in formal methods, expressing functional-correctness properties by reasoning about $k$ different executions, so-called $k$-safety properties. Considering a credit-screening model of a bank, the expected property that "if a person is denied a loan and their income decreases, they should still be denied the loan" is a 2-safety property. Here, we show the wide applicability of $k$-safety properties for machine-learning models and present the first specification language for expressing them. We also operationalize the language in a framework for automatically validating such properties using metamorphic testing. Our experiments show that our framework is effective in identifying property violations, and that detected bugs could be used to train better models.
Expressivity of Planning with Horn Description Logic Ontologies (Technical Report)
Mar 17, 2022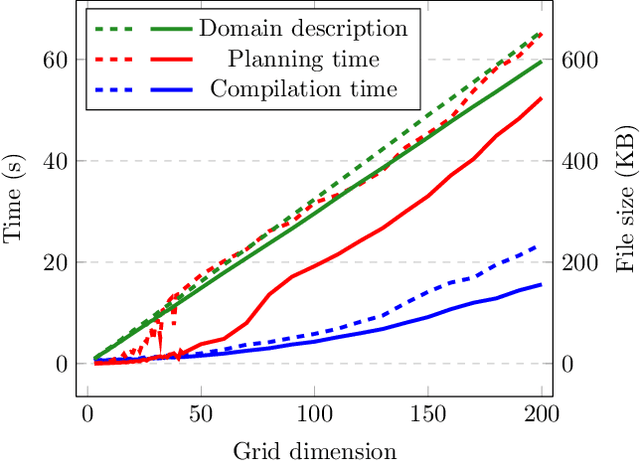

State constraints in AI Planning globally restrict the legal environment states. Standard planning languages make closed-domain and closed-world assumptions. Here we address open-world state constraints formalized by planning over a description logic (DL) ontology. Previously, this combination of DL and planning has been investigated for the light-weight DL DL-Lite. Here we propose a novel compilation scheme into standard PDDL with derived predicates, which applies to more expressive DLs and is based on the rewritability of DL queries into Datalog with stratified negation. We also provide a new rewritability result for the DL Horn-ALCHOIQ, which allows us to apply our compilation scheme to quite expressive ontologies. In contrast, we show that in the slight extension Horn-SROIQ no such compilation is possible unless the weak exponential hierarchy collapses. Finally, we show that our approach can outperform previous work on existing benchmarks for planning with DL ontologies, and is feasible on new benchmarks taking advantage of more expressive ontologies. That is an extended version of a paper accepted at AAAI 22.
An Explainable AI System for the Diagnosis of High Dimensional Biomedical Data
Jul 05, 2021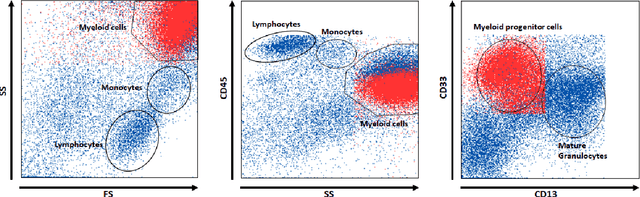
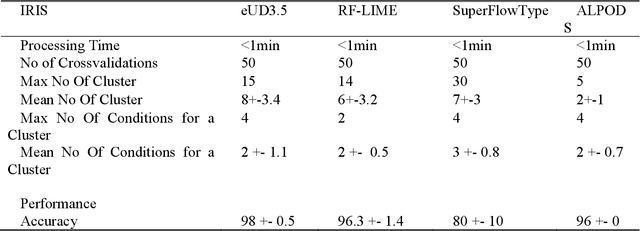

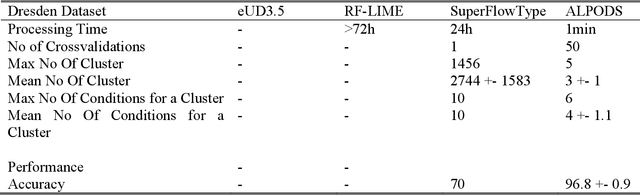
Typical state of the art flow cytometry data samples consists of measures of more than 100.000 cells in 10 or more features. AI systems are able to diagnose such data with almost the same accuracy as human experts. However, there is one central challenge in such systems: their decisions have far-reaching consequences for the health and life of people, and therefore, the decisions of AI systems need to be understandable and justifiable by humans. In this work, we present a novel explainable AI method, called ALPODS, which is able to classify (diagnose) cases based on clusters, i.e., subpopulations, in the high-dimensional data. ALPODS is able to explain its decisions in a form that is understandable for human experts. For the identified subpopulations, fuzzy reasoning rules expressed in the typical language of domain experts are generated. A visualization method based on these rules allows human experts to understand the reasoning used by the AI system. A comparison to a selection of state of the art explainable AI systems shows that ALPODS operates efficiently on known benchmark data and also on everyday routine case data.
Iterative Planning with Plan-Space Explanations: A Tool and User Study
Nov 19, 2020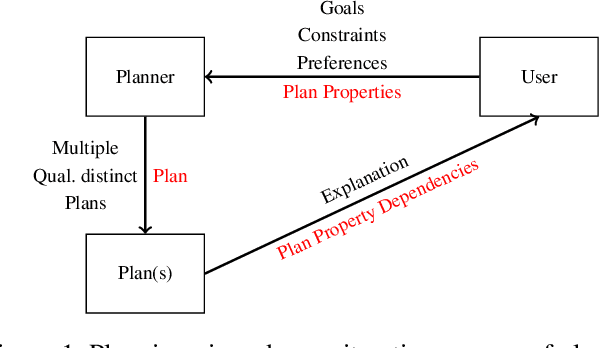
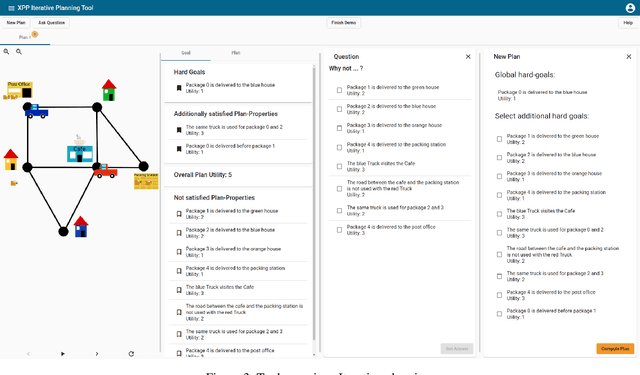

In a variety of application settings, the user preference for a planning task - the precise optimization objective - is difficult to elicit. One possible remedy is planning as an iterative process, allowing the user to iteratively refine and modify example plans. A key step to support such a process are explanations, answering user questions about the current plan. In particular, a relevant kind of question is "Why does the plan you suggest not satisfy $p$?", where p is a plan property desirable to the user. Note that such a question pertains to plan space, i.e., the set of possible alternative plans. Adopting the recent approach to answer such questions in terms of plan-property dependencies, here we implement a tool and user interface for human-guided iterative planning including plan-space explanations. The tool runs in standard Web browsers, and provides simple user interfaces for both developers and users. We conduct a first user study, whose outcome indicates the usefulness of plan-property dependency explanations in iterative planning.
Generating Instructions at Different Levels of Abstraction
Oct 08, 2020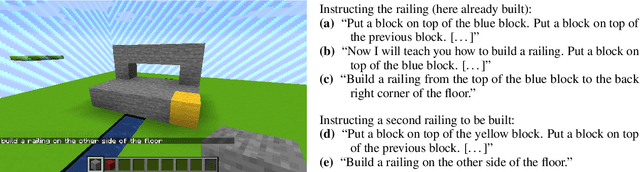
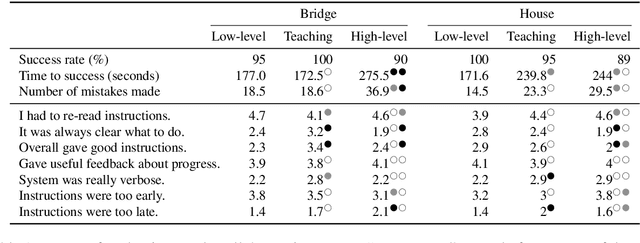


When generating technical instructions, it is often convenient to describe complex objects in the world at different levels of abstraction. A novice user might need an object explained piece by piece, while for an expert, talking about the complex object (e.g. a wall or railing) directly may be more succinct and efficient. We show how to generate building instructions at different levels of abstraction in Minecraft. We introduce the use of hierarchical planning to this end, a method from AI planning which can capture the structure of complex objects neatly. A crowdsourcing evaluation shows that the choice of abstraction level matters to users, and that an abstraction strategy which balances low-level and high-level object descriptions compares favorably to ones which don't.
Tracking the Race Between Deep Reinforcement Learning and Imitation Learning -- Extended Version
Aug 03, 2020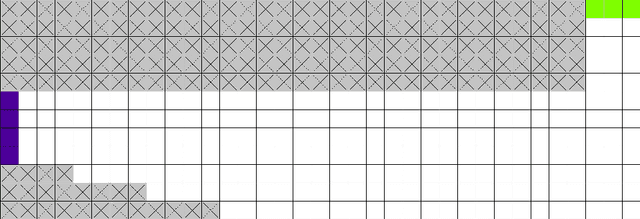


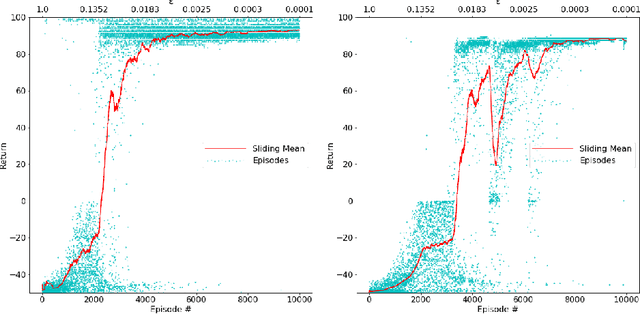
Learning-based approaches for solving large sequential decision making problems have become popular in recent years. The resulting agents perform differently and their characteristics depend on those of the underlying learning approach. Here, we consider a benchmark planning problem from the reinforcement learning domain, the Racetrack, to investigate the properties of agents derived from different deep (reinforcement) learning approaches. We compare the performance of deep supervised learning, in particular imitation learning, to reinforcement learning for the Racetrack model. We find that imitation learning yields agents that follow more risky paths. In contrast, the decisions of deep reinforcement learning are more foresighted, i.e., avoid states in which fatal decisions are more likely. Our evaluations show that for this sequential decision making problem, deep reinforcement learning performs best in many aspects even though for imitation learning optimal decisions are considered.
Simulated Penetration Testing and Mitigation Analysis
May 15, 2017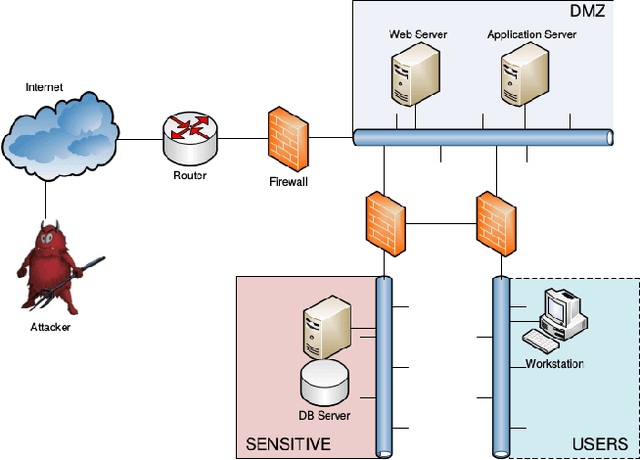

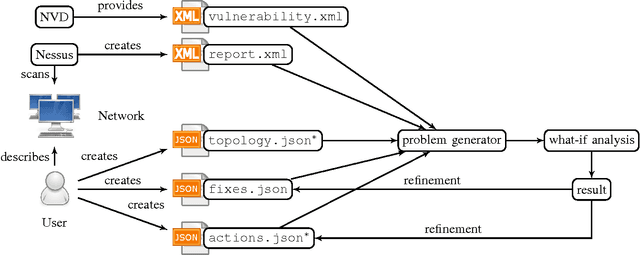
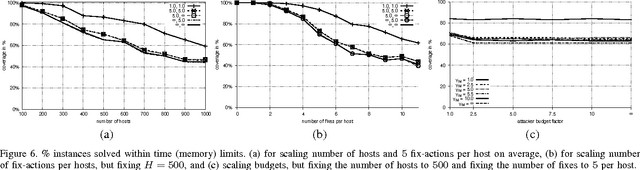
Penetration testing is a well-established practical concept for the identification of potentially exploitable security weaknesses and an important component of a security audit. Providing a holistic security assessment for networks consisting of several hundreds hosts is hardly feasible though without some sort of mechanization. Mitigation, prioritizing counter- measures subject to a given budget, currently lacks a solid theoretical understanding and is hence more art than science. In this work, we propose the first approach for conduct- ing comprehensive what-if analyses in order to reason about mitigation in a conceptually well-founded manner. To evaluate and compare mitigation strategies, we use simulated penetration testing, i.e., automated attack-finding, based on a network model to which a subset of a given set of mitigation actions, e.g., changes to the network topology, system updates, configuration changes etc. is applied. We determine optimal combinations that minimize the maximal attacker success (similar to a Stackelberg game), and thus provide a well-founded basis for a holistic mitigation strategy. We show that these what-if analysis models can largely be derived from network scan, public vulnerability databases and manual inspection with various degrees of automation and detail, and we simulate mitigation analysis on networks of different size and vulnerability.