 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Exploitation of Distance Distributions for Clustering
Aug 22, 2021
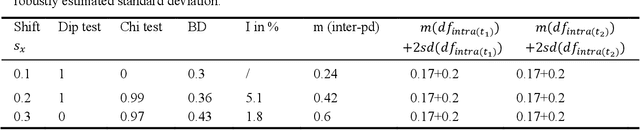


Although distance measures are used in many machine learning algorithms, the literature on the context-independent selection and evaluation of distance measures is limited in the sense that prior knowledge is used. In cluster analysis, current studies evaluate the choice of distance measure after applying unsupervised methods based on error probabilities, implicitly setting the goal of reproducing predefined partitions in data. Such studies use clusters of data that are often based on the context of the data as well as the custom goal of the specific study. Depending on the data context, different properties for distance distributions are judged to be relevant for appropriate distance selection. However, if cluster analysis is based on the task of finding similar partitions of data, then the intrapartition distances should be smaller than the interpartition distances. By systematically investigating this specification using distribution analysis through a mirrored-density plot, it is shown that multimodal distance distributions are preferable in cluster analysis. As a consequence, it is advantageous to model distance distributions with Gaussian mixtures prior to the evaluation phase of unsupervised methods. Experiments are performed on several artificial datasets and natural datasets for the task of clustering.
* 19 pages, 6 figures
An Explainable AI System for the Diagnosis of High Dimensional Biomedical Data
Jul 05, 2021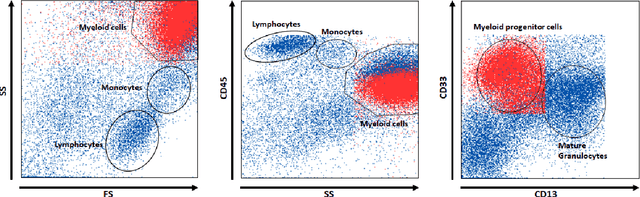
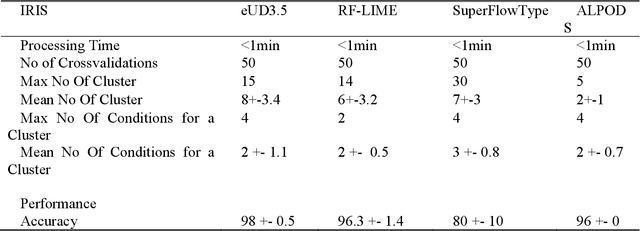

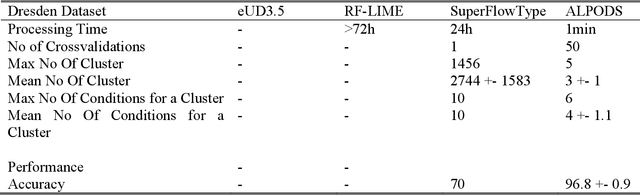
Typical state of the art flow cytometry data samples consists of measures of more than 100.000 cells in 10 or more features. AI systems are able to diagnose such data with almost the same accuracy as human experts. However, there is one central challenge in such systems: their decisions have far-reaching consequences for the health and life of people, and therefore, the decisions of AI systems need to be understandable and justifiable by humans. In this work, we present a novel explainable AI method, called ALPODS, which is able to classify (diagnose) cases based on clusters, i.e., subpopulations, in the high-dimensional data. ALPODS is able to explain its decisions in a form that is understandable for human experts. For the identified subpopulations, fuzzy reasoning rules expressed in the typical language of domain experts are generated. A visualization method based on these rules allows human experts to understand the reasoning used by the AI system. A comparison to a selection of state of the art explainable AI systems shows that ALPODS operates efficiently on known benchmark data and also on everyday routine case data.
Swarm Intelligence for Self-Organized Clustering
Jun 10, 2021
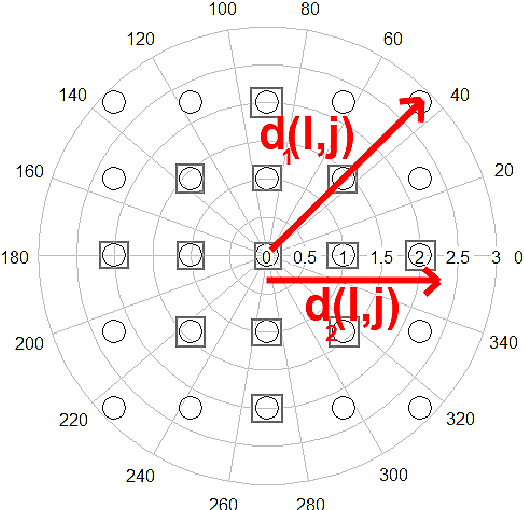
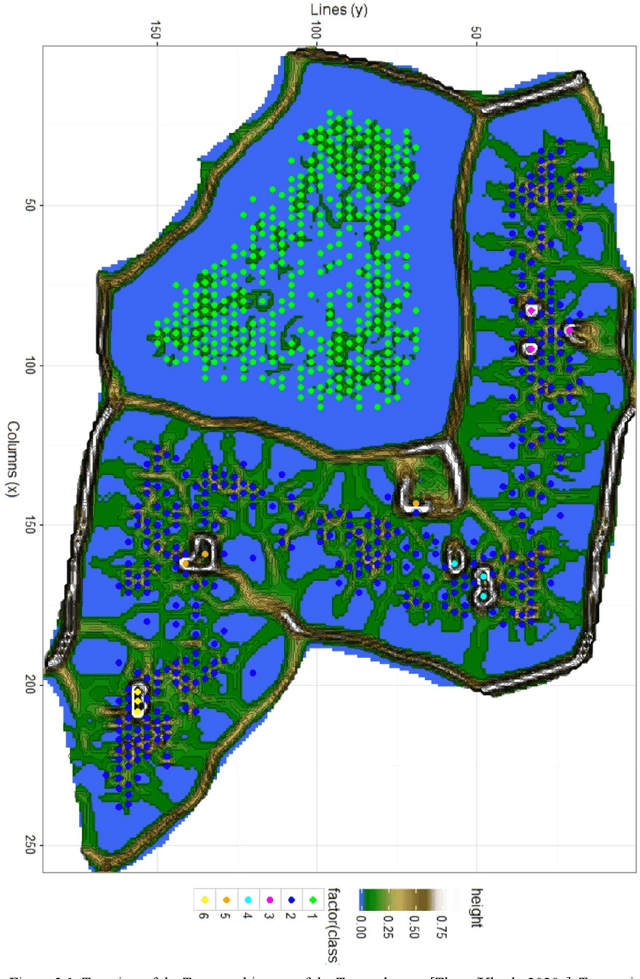
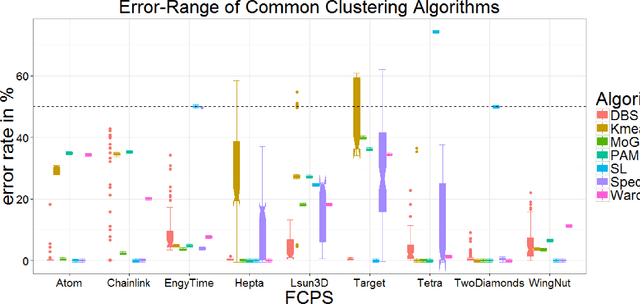
Algorithms implementing populations of agents which interact with one another and sense their environment may exhibit emergent behavior such as self-organization and swarm intelligence. Here a swarm system, called Databionic swarm (DBS), is introduced which is able to adapt itself to structures of high-dimensional data characterized by distance and/or density-based structures in the data space. By exploiting the interrelations of swarm intelligence, self-organization and emergence, DBS serves as an alternative approach to the optimization of a global objective function in the task of clustering. The swarm omits the usage of a global objective function and is parameter-free because it searches for the Nash equilibrium during its annealing process. To our knowledge, DBS is the first swarm combining these approaches. Its clustering can outperform common clustering methods such as K-means, PAM, single linkage, spectral clustering, model-based clustering, and Ward, if no prior knowledge about the data is available. A central problem in clustering is the correct estimation of the number of clusters. This is addressed by a DBS visualization called topographic map which allows assessing the number of clusters. It is known that all clustering algorithms construct clusters, irrespective of the data set contains clusters or not. In contrast to most other clustering algorithms, the topographic map identifies, that clustering of the data is meaningless if the data contains no (natural) clusters. The performance of DBS is demonstrated on a set of benchmark data, which are constructed to pose difficult clustering problems and in two real-world applications.
* 54 pages, 21 figures
Analyzing the Fine Structure of Distributions
Aug 15, 2019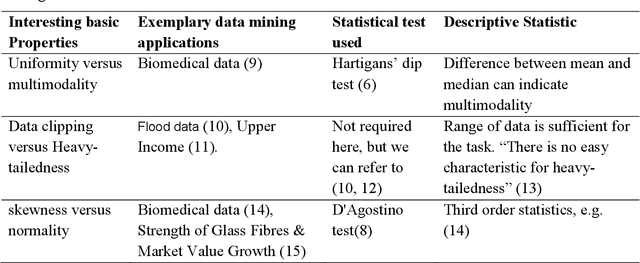
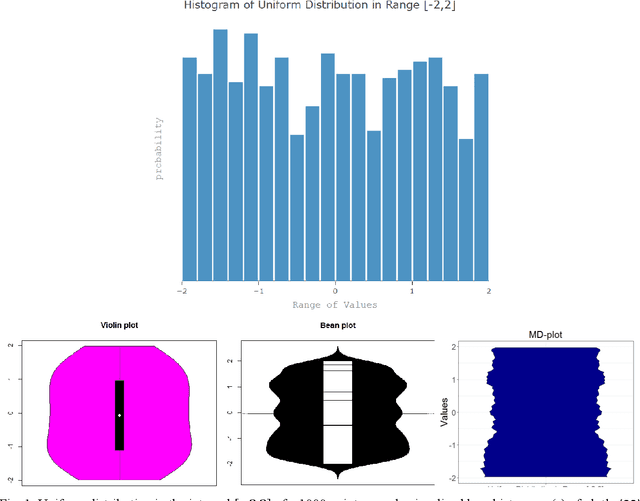
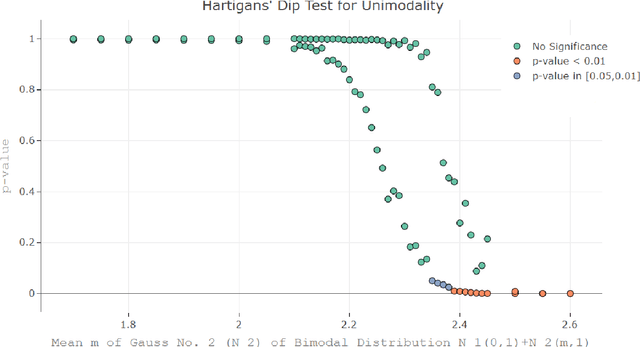
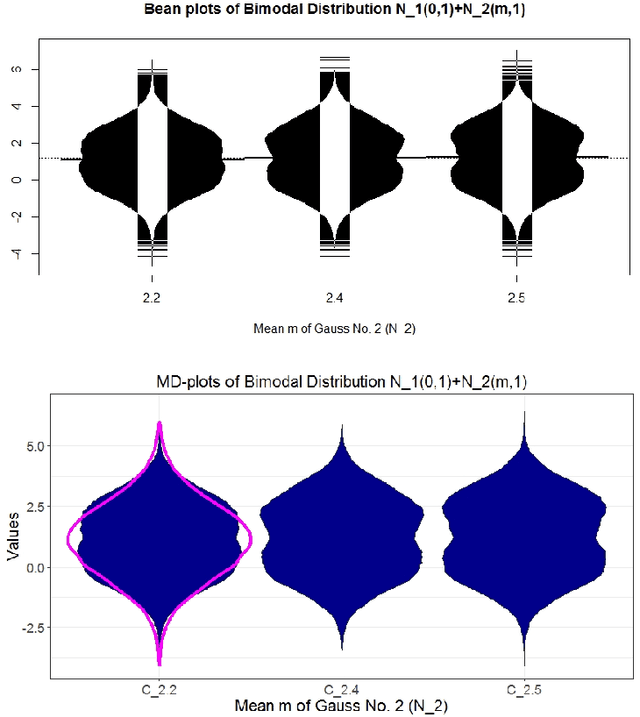
One aim of data mining is the identification of interesting structures in data. Basic properties of the empirical distribution, such as skewness and an eventual clipping, i.e., hard limits in value ranges, need to be assessed. Of particular interest is the question, whether the data originates from one process, or contains subsets related to different states of the data producing process. Data visualization tools should deliver a sensitive picture of the univariate probability density distribution (PDF) for each feature. Visualization tools for PDFs are typically kernel density estimates and range from the classical histogram to modern tools like bean or violin plots. Conventional methods have difficulties in visualizing the pdf in case of uniform, multimodal, skewed and clipped data if density estimation parameters remain in a default setting. As a consequence, a new visualization tool called Mirrored Density plot (MD plot) is proposed which is particularly designed to discover interesting structures in continuous features. The MD plot does not require any adjustments of parameters of density estimation which makes the usage compelling for non-experts. The visualization tools are evaluated in comparison to statistical tests for the typical challenges of explorative distribution analysis. The results are presented on bimodal Gaussian and skewed distributions as well as several features with published pdfs. In exploratory data analysis of 12 features describing the quarterly financial statements, when statistical testing becomes a demanding task, only the MD plots can identify the structure of their pdfs. Overall, the MD plot can outperform the methods mentioned above.