 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Exploitation of Distance Distributions for Clustering
Paper and Code
Aug 22, 2021
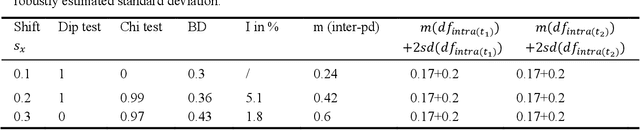


Although distance measures are used in many machine learning algorithms, the literature on the context-independent selection and evaluation of distance measures is limited in the sense that prior knowledge is used. In cluster analysis, current studies evaluate the choice of distance measure after applying unsupervised methods based on error probabilities, implicitly setting the goal of reproducing predefined partitions in data. Such studies use clusters of data that are often based on the context of the data as well as the custom goal of the specific study. Depending on the data context, different properties for distance distributions are judged to be relevant for appropriate distance selection. However, if cluster analysis is based on the task of finding similar partitions of data, then the intrapartition distances should be smaller than the interpartition distances. By systematically investigating this specification using distribution analysis through a mirrored-density plot, it is shown that multimodal distance distributions are preferable in cluster analysis. As a consequence, it is advantageous to model distance distributions with Gaussian mixtures prior to the evaluation phase of unsupervised methods. Experiments are performed on several artificial datasets and natural datasets for the task of clustering.