 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalyzing the Fine Structure of Distributions
Paper and Code
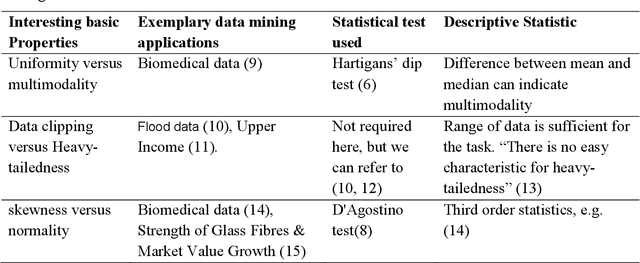
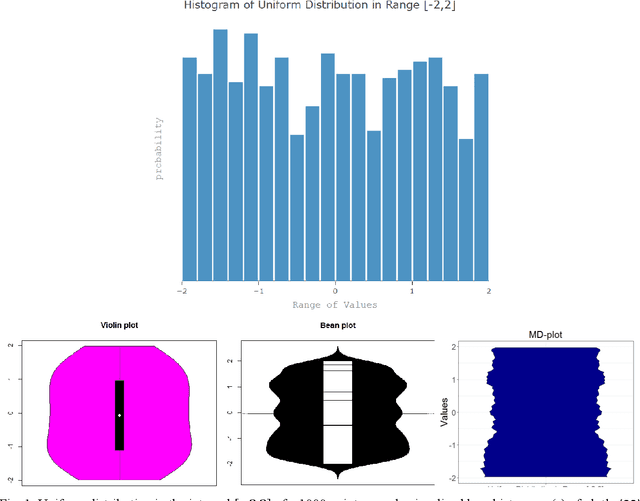
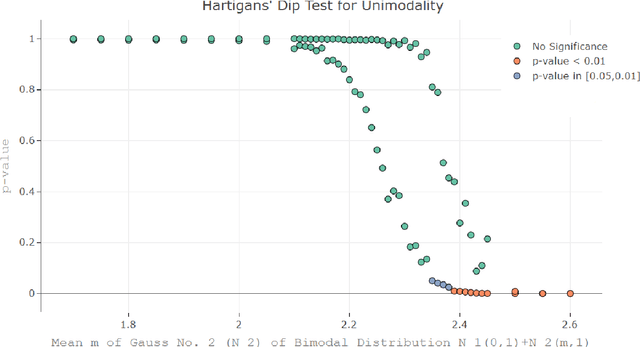
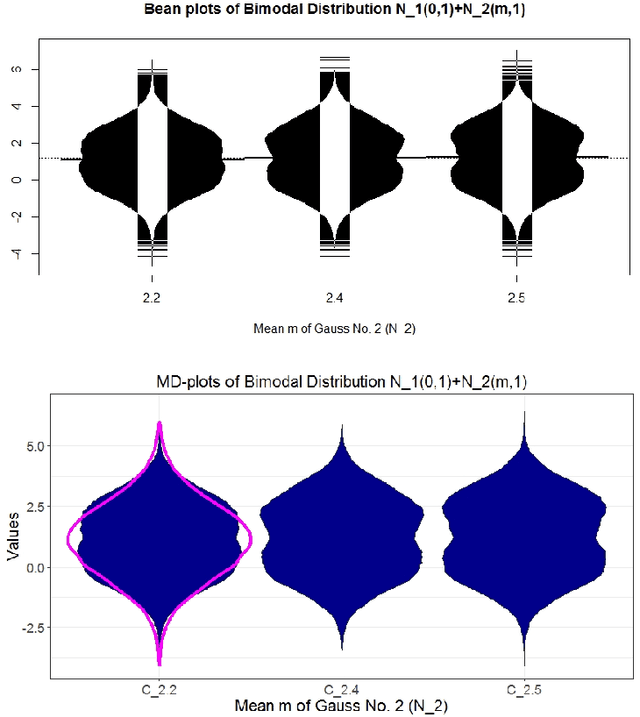
One aim of data mining is the identification of interesting structures in data. Basic properties of the empirical distribution, such as skewness and an eventual clipping, i.e., hard limits in value ranges, need to be assessed. Of particular interest is the question, whether the data originates from one process, or contains subsets related to different states of the data producing process. Data visualization tools should deliver a sensitive picture of the univariate probability density distribution (PDF) for each feature. Visualization tools for PDFs are typically kernel density estimates and range from the classical histogram to modern tools like bean or violin plots. Conventional methods have difficulties in visualizing the pdf in case of uniform, multimodal, skewed and clipped data if density estimation parameters remain in a default setting. As a consequence, a new visualization tool called Mirrored Density plot (MD plot) is proposed which is particularly designed to discover interesting structures in continuous features. The MD plot does not require any adjustments of parameters of density estimation which makes the usage compelling for non-experts. The visualization tools are evaluated in comparison to statistical tests for the typical challenges of explorative distribution analysis. The results are presented on bimodal Gaussian and skewed distributions as well as several features with published pdfs. In exploratory data analysis of 12 features describing the quarterly financial statements, when statistical testing becomes a demanding task, only the MD plots can identify the structure of their pdfs. Overall, the MD plot can outperform the methods mentioned above.