 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Open-Vocabulary Object Detection through Multi-Level Fine-Grained Visual-Language Alignment
Jan 31, 2026Traditional object detection systems are typically constrained to predefined categories, limiting their applicability in dynamic environments. In contrast, open-vocabulary object detection (OVD) enables the identification of objects from novel classes not present in the training set. Recent advances in visual-language modeling have led to significant progress of OVD. However, prior works face challenges in either adapting the single-scale image backbone from CLIP to the detection framework or ensuring robust visual-language alignment. We propose Visual-Language Detection (VLDet), a novel framework that revamps feature pyramid for fine-grained visual-language alignment, leading to improved OVD performance. With the VL-PUB module, VLDet effectively exploits the visual-language knowledge from CLIP and adapts the backbone for object detection through feature pyramid. In addition, we introduce the SigRPN block, which incorporates a sigmoid-based anchor-text contrastive alignment loss to improve detection of novel categories. Through extensive experiments, our approach achieves 58.7 AP for novel classes on COCO2017 and 24.8 AP on LVIS, surpassing all state-of-the-art methods and achieving significant improvements of 27.6% and 6.9%, respectively. Furthermore, VLDet also demonstrates superior zero-shot performance on closed-set object detection.
Scaling Reinforcement Learning for Content Moderation with Large Language Models
Dec 23, 2025
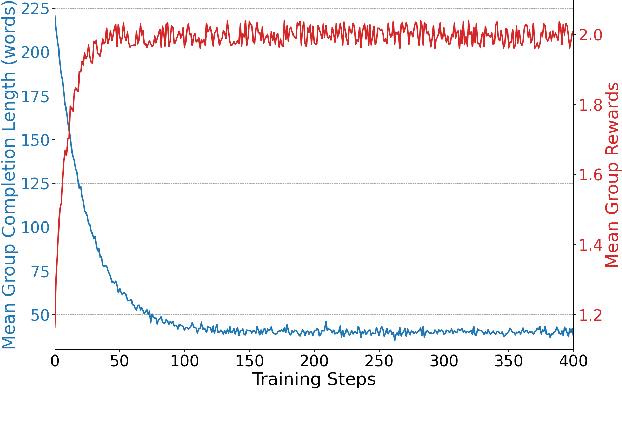
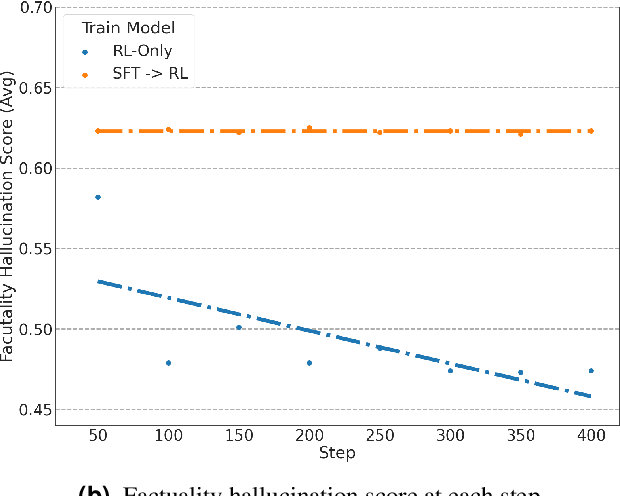
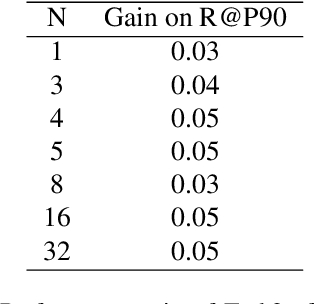
Content moderation at scale remains one of the most pressing challenges in today's digital ecosystem, where billions of user- and AI-generated artifacts must be continuously evaluated for policy violations. Although recent advances in large language models (LLMs) have demonstrated strong potential for policy-grounded moderation, the practical challenges of training these systems to achieve expert-level accuracy in real-world settings remain largely unexplored, particularly in regimes characterized by label sparsity, evolving policy definitions, and the need for nuanced reasoning beyond shallow pattern matching. In this work, we present a comprehensive empirical investigation of scaling reinforcement learning (RL) for content classification, systematically evaluating multiple RL training recipes and reward-shaping strategies-including verifiable rewards and LLM-as-judge frameworks-to transform general-purpose language models into specialized, policy-aligned classifiers across three real-world content moderation tasks. Our findings provide actionable insights for industrial-scale moderation systems, demonstrating that RL exhibits sigmoid-like scaling behavior in which performance improves smoothly with increased training data, rollouts, and optimization steps before gradually saturating. Moreover, we show that RL substantially improves performance on tasks requiring complex policy-grounded reasoning while achieving up to 100x higher data efficiency than supervised fine-tuning, making it particularly effective in domains where expert annotations are scarce or costly.
The Automated Verification of Textual Claims (AVeriTeC) Shared Task
Oct 31, 2024



The Automated Verification of Textual Claims (AVeriTeC) shared task asks participants to retrieve evidence and predict veracity for real-world claims checked by fact-checkers. Evidence can be found either via a search engine, or via a knowledge store provided by the organisers. Submissions are evaluated using AVeriTeC score, which considers a claim to be accurately verified if and only if both the verdict is correct and retrieved evidence is considered to meet a certain quality threshold. The shared task received 21 submissions, 18 of which surpassed our baseline. The winning team was TUDA_MAI with an AVeriTeC score of 63%. In this paper we describe the shared task, present the full results, and highlight key takeaways from the shared task.
CHIP: Contrastive Hierarchical Image Pretraining
Oct 12, 2023



Few-shot object classification is the task of classifying objects in an image with limited number of examples as supervision. We propose a one-shot/few-shot classification model that can classify an object of any unseen class into a relatively general category in an hierarchically based classification. Our model uses a three-level hierarchical contrastive loss based ResNet152 classifier for classifying an object based on its features extracted from Image embedding, not used during the training phase. For our experimentation, we have used a subset of the ImageNet (ILSVRC-12) dataset that contains only the animal classes for training our model and created our own dataset of unseen classes for evaluating our trained model. Our model provides satisfactory results in classifying the unknown objects into a generic category which has been later discussed in greater detail.
Emotion-Cause Pair Extraction in Customer Reviews
Dec 07, 2021
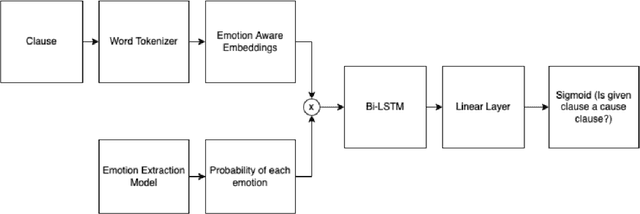
Emotion-Cause Pair Extraction (ECPE) is a complex yet popular area in Natural Language Processing due to its importance and potential applications in various domains. In this report , we aim to present our work in ECPE in the domain of online reviews. With a manually annotated dataset, we explore an algorithm to extract emotion cause pairs using a neural network. In addition, we propose a model using previous reference materials and combining emotion-cause pair extraction with research in the domain of emotion-aware word embeddings, where we send these embeddings into a Bi-LSTM layer which gives us the emotionally relevant clauses. With the constraint of a limited dataset, we achieved . The overall scope of our report comprises of a comprehensive literature review, implementation of referenced methods for dataset construction and initial model training, and modifying previous work in ECPE by proposing an improvement to the pipeline, as well as algorithm development and implementation for the specific domain of reviews.
FEVEROUS: Fact Extraction and VERification Over Unstructured and Structured information
Jun 10, 2021
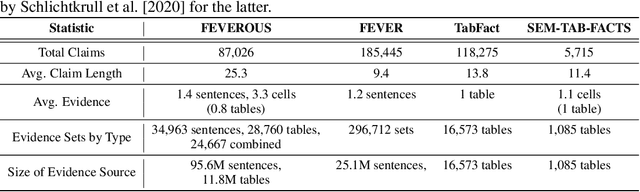
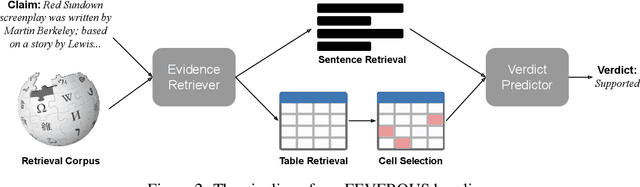
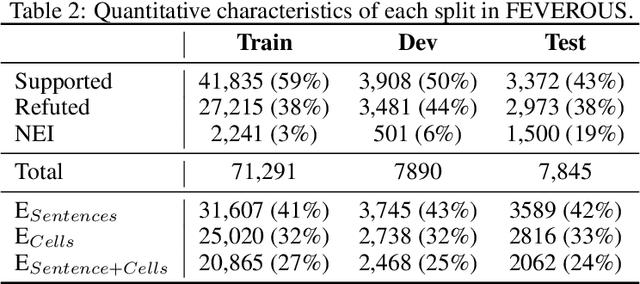
Fact verification has attracted a lot of attention in the machine learning and natural language processing communities, as it is one of the key methods for detecting misinformation. Existing large-scale benchmarks for this task have focused mostly on textual sources, i.e. unstructured information, and thus ignored the wealth of information available in structured formats, such as tables. In this paper we introduce a novel dataset and benchmark, Fact Extraction and VERification Over Unstructured and Structured information (FEVEROUS), which consists of 87,026 verified claims. Each claim is annotated with evidence in the form of sentences and/or cells from tables in Wikipedia, as well as a label indicating whether this evidence supports, refutes, or does not provide enough information to reach a verdict. Furthermore, we detail our efforts to track and minimize the biases present in the dataset and could be exploited by models, e.g. being able to predict the label without using evidence. Finally, we develop a baseline for verifying claims against text and tables which predicts both the correct evidence and verdict for 18% of the claims.
Using Pairwise Occurrence Information to Improve Knowledge Graph Completion on Large-Scale Datasets
Oct 25, 2019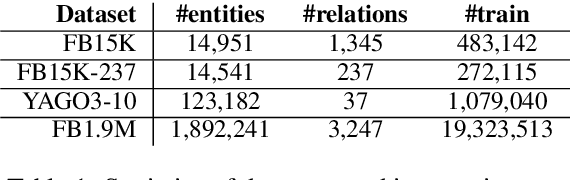
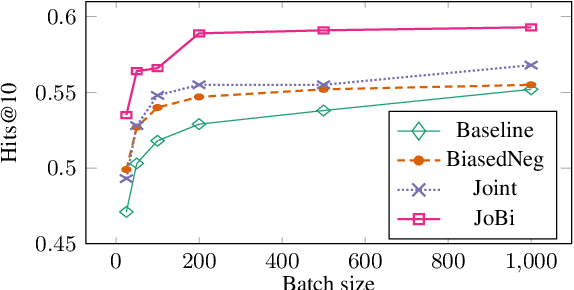
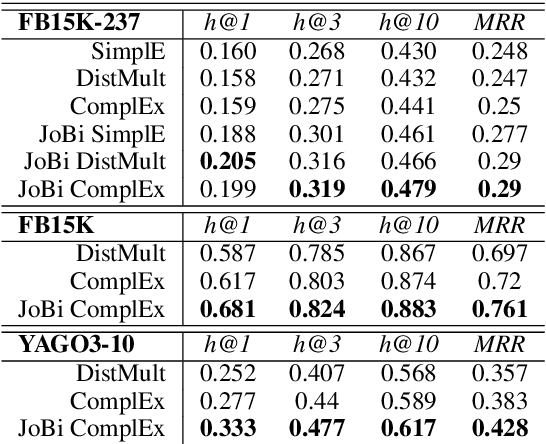
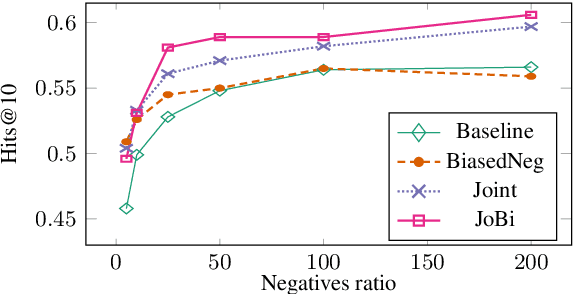
Bilinear models such as DistMult and ComplEx are effective methods for knowledge graph (KG) completion. However, they require large batch sizes, which becomes a performance bottleneck when training on large scale datasets due to memory constraints. In this paper we use occurrences of entity-relation pairs in the dataset to construct a joint learning model and to increase the quality of sampled negatives during training. We show on three standard datasets that when these two techniques are combined, they give a significant improvement in performance, especially when the batch size and the number of generated negative examples are low relative to the size of the dataset. We then apply our techniques to a dataset containing 2 million entities and demonstrate that our model outperforms the baseline by 2.8% absolute on hits@1.
Large Scale Question Paraphrase Retrieval with Smoothed Deep Metric Learning
May 29, 2019
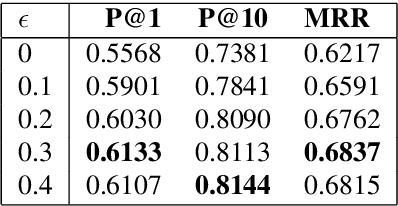
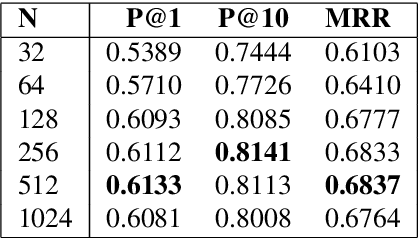
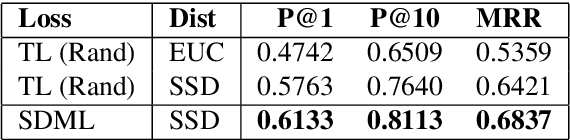
The goal of a Question Paraphrase Retrieval (QPR) system is to retrieve equivalent questions that result in the same answer as the original question. Such a system can be used to understand and answer rare and noisy reformulations of common questions by mapping them to a set of canonical forms. This has large-scale applications for community Question Answering (cQA) and open-domain spoken language question answering systems. In this paper we describe a new QPR system implemented as a Neural Information Retrieval (NIR) system consisting of a neural network sentence encoder and an approximate k-Nearest Neighbour index for efficient vector retrieval. We also describe our mechanism to generate an annotated dataset for question paraphrase retrieval experiments automatically from question-answer logs via distant supervision. We show that the standard loss function in NIR, triplet loss, does not perform well with noisy labels. We propose smoothed deep metric loss (SDML) and with our experiments on two QPR datasets we show that it significantly outperforms triplet loss in the noisy label setting.
Generating Token-Level Explanations for Natural Language Inference
Apr 24, 2019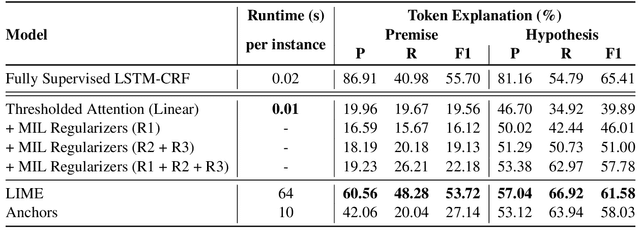
The task of Natural Language Inference (NLI) is widely modeled as supervised sentence pair classification. While there has been a lot of work recently on generating explanations of the predictions of classifiers on a single piece of text, there have been no attempts to generate explanations of classifiers operating on pairs of sentences. In this paper, we show that it is possible to generate token-level explanations for NLI without the need for training data explicitly annotated for this purpose. We use a simple LSTM architecture and evaluate both LIME and Anchor explanations for this task. We compare these to a Multiple Instance Learning (MIL) method that uses thresholded attention make token-level predictions. The approach we present in this paper is a novel extension of zero-shot single-sentence tagging to sentence pairs for NLI. We conduct our experiments on the well-studied SNLI dataset that was recently augmented with manually annotation of the tokens that explain the entailment relation. We find that our white-box MIL-based method, while orders of magnitude faster, does not reach the same accuracy as the black-box methods.
Learning When Not to Answer: A Ternary Reward Structure for Reinforcement Learning based Question Answering
Apr 03, 2019



In this paper, we investigate the challenges of using reinforcement learning agents for question-answering over knowledge graphs for real-world applications. We examine the performance metrics used by state-of-the-art systems and determine that they are inadequate for such settings. More specifically, they do not evaluate the systems correctly for situations when there is no answer available and thus agents optimized for these metrics are poor at modeling confidence. We introduce a simple new performance metric for evaluating question-answering agents that is more representative of practical usage conditions, and optimize for this metric by extending the binary reward structure used in prior work to a ternary reward structure which also rewards an agent for not answering a question rather than giving an incorrect answer. We show that this can drastically improve the precision of answered questions while only not answering a limited number of previously correctly answered questions. Employing a supervised learning strategy using depth-first-search paths to bootstrap the reinforcement learning algorithm further improves performance.