 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Automatic Verification of Image-Text Claims (AVerImaTeC) Shared Task
Feb 11, 2026The Automatic Verification of Image-Text Claims (AVerImaTeC) shared task aims to advance system development for retrieving evidence and verifying real-world image-text claims. Participants were allowed to either employ external knowledge sources, such as web search engines, or leverage the curated knowledge store provided by the organizers. System performance was evaluated using the AVerImaTeC score, defined as a conditional verdict accuracy in which a verdict is considered correct only when the associated evidence score exceeds a predefined threshold. The shared task attracted 14 submissions during the development phase and 6 submissions during the testing phase. All participating systems in the testing phase outperformed the baseline provided. The winning team, HUMANE, achieved an AVerImaTeC score of 0.5455. This paper provides a detailed description of the shared task, presents the complete evaluation results, and discusses key insights and lessons learned.
Counterfactual Samples Constructing and Training for Commonsense Statements Estimation
Dec 29, 2024



Plausibility Estimation (PE) plays a crucial role for enabling language models to objectively comprehend the real world. While large language models (LLMs) demonstrate remarkable capabilities in PE tasks but sometimes produce trivial commonsense errors due to the complexity of commonsense knowledge. They lack two key traits of an ideal PE model: a) Language-explainable: relying on critical word segments for decisions, and b) Commonsense-sensitive: detecting subtle linguistic variations in commonsense. To address these issues, we propose a novel model-agnostic method, referred to as Commonsense Counterfactual Samples Generating (CCSG). By training PE models with CCSG, we encourage them to focus on critical words, thereby enhancing both their language-explainable and commonsense-sensitive capabilities. Specifically, CCSG generates counterfactual samples by strategically replacing key words and introducing low-level dropout within sentences. These counterfactual samples are then incorporated into a sentence-level contrastive training framework to further enhance the model's learning process. Experimental results across nine diverse datasets demonstrate the effectiveness of CCSG in addressing commonsense reasoning challenges, with our CCSG method showing 3.07% improvement against the SOTA methods.
The Automated Verification of Textual Claims (AVeriTeC) Shared Task
Oct 31, 2024



The Automated Verification of Textual Claims (AVeriTeC) shared task asks participants to retrieve evidence and predict veracity for real-world claims checked by fact-checkers. Evidence can be found either via a search engine, or via a knowledge store provided by the organisers. Submissions are evaluated using AVeriTeC score, which considers a claim to be accurately verified if and only if both the verdict is correct and retrieved evidence is considered to meet a certain quality threshold. The shared task received 21 submissions, 18 of which surpassed our baseline. The winning team was TUDA_MAI with an AVeriTeC score of 63%. In this paper we describe the shared task, present the full results, and highlight key takeaways from the shared task.
Document-level Claim Extraction and Decontextualisation for Fact-Checking
Jun 05, 2024
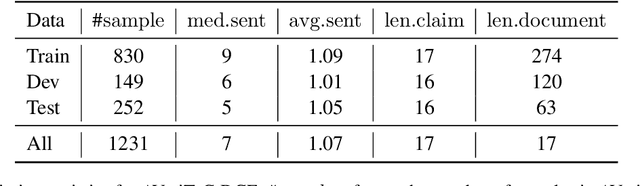

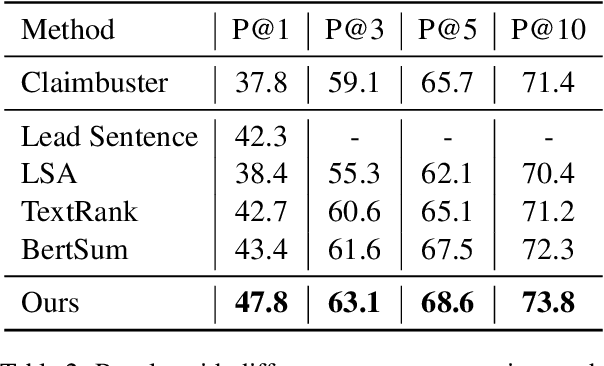
Selecting which claims to check is a time-consuming task for human fact-checkers, especially from documents consisting of multiple sentences and containing multiple claims. However, existing claim extraction approaches focus more on identifying and extracting claims from individual sentences, e.g., identifying whether a sentence contains a claim or the exact boundaries of the claim within a sentence. In this paper, we propose a method for document-level claim extraction for fact-checking, which aims to extract check-worthy claims from documents and decontextualise them so that they can be understood out of context. Specifically, we first recast claim extraction as extractive summarization in order to identify central sentences from documents, then rewrite them to include necessary context from the originating document through sentence decontextualisation. Evaluation with both automatic metrics and a fact-checking professional shows that our method is able to extract check-worthy claims from documents more accurately than previous work, while also improving evidence retrieval.
Contrastive Learning with Logic-driven Data Augmentation for Logical Reasoning over Text
May 21, 2023Pre-trained large language model (LLM) is under exploration to perform NLP tasks that may require logical reasoning. Logic-driven data augmentation for representation learning has been shown to improve the performance of tasks requiring logical reasoning, but most of these data rely on designed templates and therefore lack generalization. In this regard, we propose an AMR-based logical equivalence-driven data augmentation method (AMR-LE) for generating logically equivalent data. Specifically, we first parse a text into the form of an AMR graph, next apply four logical equivalence laws (contraposition, double negation, commutative and implication laws) on the AMR graph to construct a logically equivalent/inequivalent AMR graph, and then convert it into a logically equivalent/inequivalent sentence. To help the model to better learn these logical equivalence laws, we propose a logical equivalence-driven contrastive learning training paradigm, which aims to distinguish the difference between logical equivalence and inequivalence. Our AMR-LE (Ensemble) achieves #2 on the ReClor leaderboard https://eval.ai/web/challenges/challenge-page/503/leaderboard/1347 . Our model shows better performance on seven downstream tasks, including ReClor, LogiQA, MNLI, MRPC, RTE, QNLI, and QQP. The source code and dataset are public at https://github.com/Strong-AI-Lab/Logical-Equivalence-driven-AMR-Data-Augmentation-for-Representation-Learning .
Prompt-based Conservation Learning for Multi-hop Question Answering
Sep 14, 2022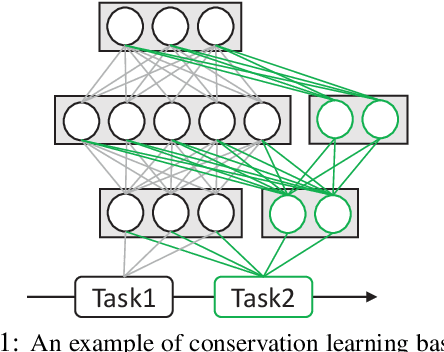
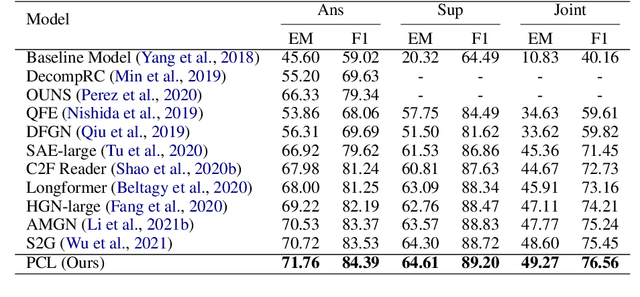
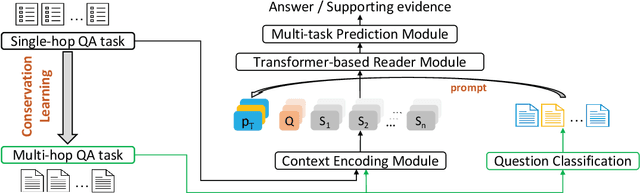
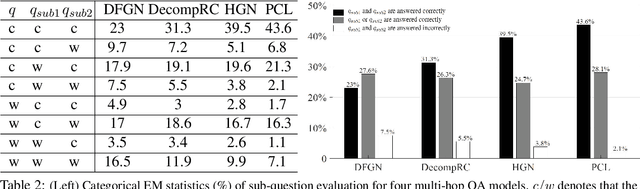
Multi-hop question answering (QA) requires reasoning over multiple documents to answer a complex question and provide interpretable supporting evidence. However, providing supporting evidence is not enough to demonstrate that a model has performed the desired reasoning to reach the correct answer. Most existing multi-hop QA methods fail to answer a large fraction of sub-questions, even if their parent questions are answered correctly. In this paper, we propose the Prompt-based Conservation Learning (PCL) framework for multi-hop QA, which acquires new knowledge from multi-hop QA tasks while conserving old knowledge learned on single-hop QA tasks, mitigating forgetting. Specifically, we first train a model on existing single-hop QA tasks, and then freeze this model and expand it by allocating additional sub-networks for the multi-hop QA task. Moreover, to condition pre-trained language models to stimulate the kind of reasoning required for specific multi-hop questions, we learn soft prompts for the novel sub-networks to perform type-specific reasoning. Experimental results on the HotpotQA benchmark show that PCL is competitive for multi-hop QA and retains good performance on the corresponding single-hop sub-questions, demonstrating the efficacy of PCL in mitigating knowledge loss by forgetting.
Multi-Step Deductive Reasoning Over Natural Language: An Empirical Study on Out-of-Distribution Generalisation
Jul 28, 2022
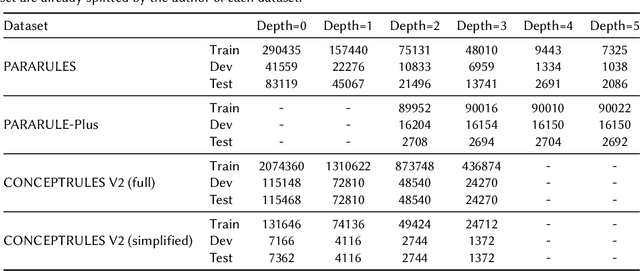
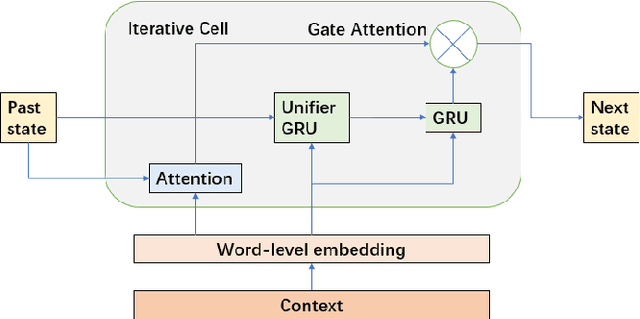
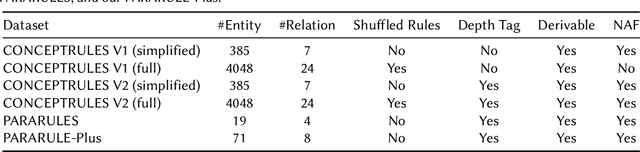
Combining deep learning with symbolic logic reasoning aims to capitalize on the success of both fields and is drawing increasing attention. Inspired by DeepLogic, an end-to-end model trained to perform inference on logic programs, we introduce IMA-GloVe-GA, an iterative neural inference network for multi-step reasoning expressed in natural language. In our model, reasoning is performed using an iterative memory neural network based on RNN with a gate attention mechanism. We evaluate IMA-GloVe-GA on three datasets: PARARULES, CONCEPTRULES V1 and CONCEPTRULES V2. Experimental results show DeepLogic with gate attention can achieve higher test accuracy than DeepLogic and other RNN baseline models. Our model achieves better out-of-distribution generalisation than RoBERTa-Large when the rules have been shuffled. Furthermore, to address the issue of unbalanced distribution of reasoning depths in the current multi-step reasoning datasets, we develop PARARULE-Plus, a large dataset with more examples that require deeper reasoning steps. Experimental results show that the addition of PARARULE-Plus can increase the model's performance on examples requiring deeper reasoning depths. The source code and data are available at https://github.com/Strong-AI-Lab/Multi-Step-Deductive-Reasoning-Over-Natural-Language.
Interpretable AMR-Based Question Decomposition for Multi-hop Question Answering
Jun 16, 2022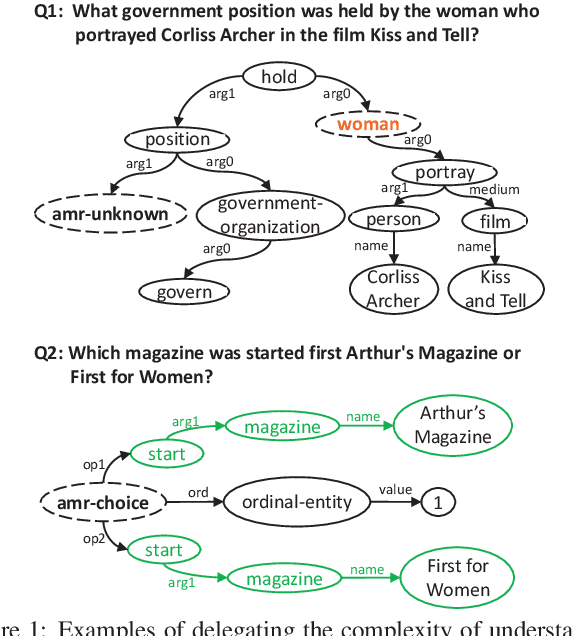
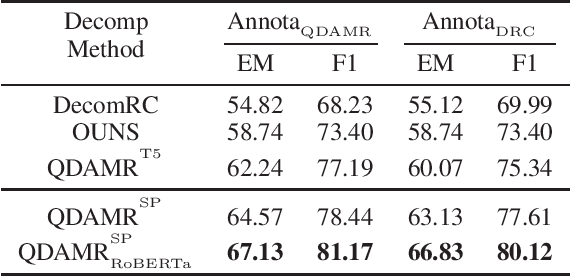
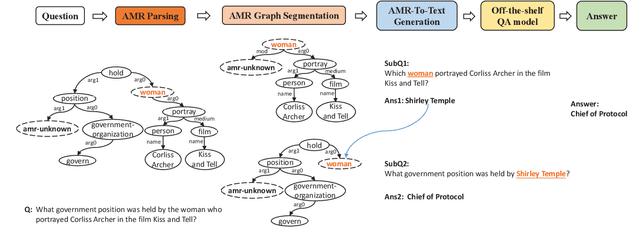
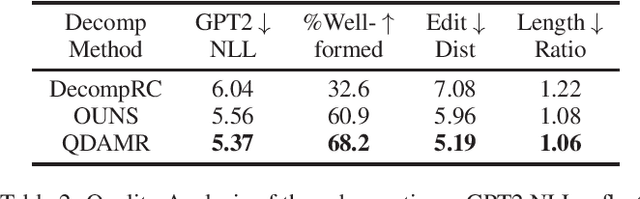
Effective multi-hop question answering (QA) requires reasoning over multiple scattered paragraphs and providing explanations for answers. Most existing approaches cannot provide an interpretable reasoning process to illustrate how these models arrive at an answer. In this paper, we propose a Question Decomposition method based on Abstract Meaning Representation (QDAMR) for multi-hop QA, which achieves interpretable reasoning by decomposing a multi-hop question into simpler sub-questions and answering them in order. Since annotating the decomposition is expensive, we first delegate the complexity of understanding the multi-hop question to an AMR parser. We then achieve the decomposition of a multi-hop question via segmentation of the corresponding AMR graph based on the required reasoning type. Finally, we generate sub-questions using an AMR-to-Text generation model and answer them with an off-the-shelf QA model. Experimental results on HotpotQA demonstrate that our approach is competitive for interpretable reasoning and that the sub-questions generated by QDAMR are well-formed, outperforming existing question-decomposition-based multi-hop QA approaches.