 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo Smaller Language Models Answer Contextualised Questions Through Memorisation Or Generalisation?
Nov 21, 2023

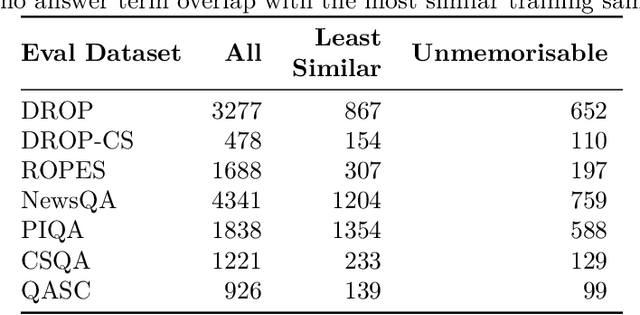

A distinction is often drawn between a model's ability to predict a label for an evaluation sample that is directly memorised from highly similar training samples versus an ability to predict the label via some method of generalisation. In the context of using Language Models for question-answering, discussion continues to occur as to the extent to which questions are answered through memorisation. We consider this issue for questions that would ideally be answered through reasoning over an associated context. We propose a method of identifying evaluation samples for which it is very unlikely our model would have memorised the answers. Our method is based on semantic similarity of input tokens and label tokens between training and evaluation samples. We show that our method offers advantages upon some prior approaches in that it is able to surface evaluation-train pairs that have overlap in either contiguous or discontiguous sequences of tokens. We use this method to identify unmemorisable subsets of our evaluation datasets. We train two Language Models in a multitask fashion whereby the second model differs from the first only in that it has two additional datasets added to the training regime that are designed to impart simple numerical reasoning strategies of a sort known to improve performance on some of our evaluation datasets but not on others. We then show that there is performance improvement between the two models on the unmemorisable subsets of the evaluation datasets that were expected to benefit from the additional training datasets. Specifically, performance on unmemorisable subsets of two of our evaluation datasets, DROP and ROPES significantly improves by 9.0%, and 25.7% respectively while other evaluation datasets have no significant change in performance.
Teaching Smaller Language Models To Generalise To Unseen Compositional Questions
Aug 21, 2023We equip a smaller Language Model to generalise to answering challenging compositional questions that have not been seen in training. To do so we propose a combination of multitask supervised pretraining on up to 93 tasks designed to instill diverse reasoning abilities, and a dense retrieval system that aims to retrieve a set of evidential paragraph fragments. Recent progress in question-answering has been achieved either through prompting methods against very large pretrained Language Models in zero or few-shot fashion, or by fine-tuning smaller models, sometimes in conjunction with information retrieval. We focus on the less explored question of the extent to which zero-shot generalisation can be enabled in smaller models with retrieval against a corpus within which sufficient information to answer a particular question may not exist. We establish strong baselines in this setting for diverse evaluation datasets (StrategyQA, CommonsenseQA, IIRC, DROP, Musique and ARC-DA), and show that performance can be significantly improved by adding retrieval-augmented training datasets which are designed to expose our models to a variety of heuristic reasoning strategies such as weighing partial evidence or ignoring an irrelevant context.
Answering Unseen Questions With Smaller Language Models Using Rationale Generation and Dense Retrieval
Aug 12, 2023
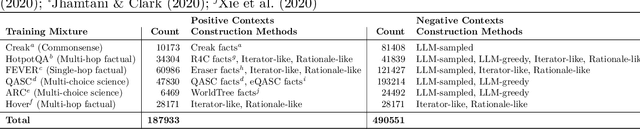

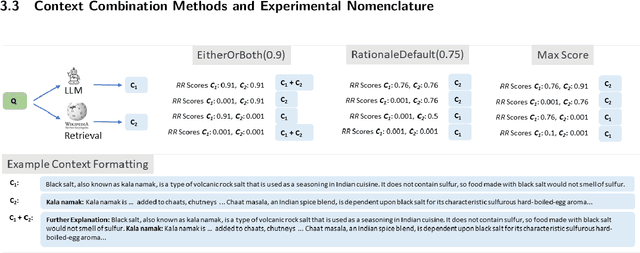
When provided with sufficient explanatory context, smaller Language Models have been shown to exhibit strong reasoning ability on challenging short-answer question-answering tasks where the questions are unseen in training. We evaluate two methods for further improvement in this setting. Both methods focus on combining rationales generated by a larger Language Model with longer contexts created from a multi-hop dense retrieval system. The first method ($\textit{RR}$) involves training a Rationale Ranking model to score both generated rationales and retrieved contexts with respect to relevance and truthfulness. We then use the scores to derive combined contexts from both knowledge sources using a number of combinatory strategies. For the second method ($\textit{RATD}$) we train a smaller Reasoning model using retrieval-augmented training datasets such that it becomes proficient at utilising relevant information from longer text sequences that may be only partially evidential and frequently contain many irrelevant sentences. Generally we find that both methods are effective but that the $\textit{RATD}$ method is more straightforward to apply and produces the strongest results in the unseen setting on which we focus. Our single best Reasoning model using only 440 million parameters materially improves upon strong comparable prior baselines for unseen evaluation datasets (StrategyQA 58.9 $\rightarrow$ 61.7 acc., CommonsenseQA 63.6 $\rightarrow$ 72.7 acc., ARC-DA 31.6 $\rightarrow$ 52.1 F1, IIRC 25.5 $\rightarrow$ 27.3 F1) and a version utilising our prior knowledge of each type of question in selecting a context combination strategy does even better. Our proposed models also generally outperform direct prompts against much larger models (BLOOM 175B and StableVicuna 13B) in both few-shot chain-of-thought and few-shot answer-only settings.
Input-length-shortening and text generation via attention values
Mar 14, 2023Identifying words that impact a task's performance more than others is a challenge in natural language processing. Transformers models have recently addressed this issue by incorporating an attention mechanism that assigns greater attention (i.e., relevance) scores to some words than others. Because of the attention mechanism's high computational cost, transformer models usually have an input-length limitation caused by hardware constraints. This limitation applies to many transformers, including the well-known bidirectional encoder representations of the transformer (BERT) model. In this paper, we examined BERT's attention assignment mechanism, focusing on two questions: (1) How can attention be employed to reduce input length? (2) How can attention be used as a control mechanism for conditional text generation? We investigated these questions in the context of a text classification task. We discovered that BERT's early layers assign more critical attention scores for text classification tasks compared to later layers. We demonstrated that the first layer's attention sums could be used to filter tokens in a given sequence, considerably decreasing the input length while maintaining good test accuracy. We also applied filtering, which uses a compute-efficient semantic similarities algorithm, and discovered that retaining approximately 6\% of the original sequence is sufficient to obtain 86.5\% accuracy. Finally, we showed that we could generate data in a stable manner and indistinguishable from the original one by only using a small percentage (10\%) of the tokens with high attention scores according to BERT's first layer.
Multi-Step Deductive Reasoning Over Natural Language: An Empirical Study on Out-of-Distribution Generalisation
Jul 28, 2022
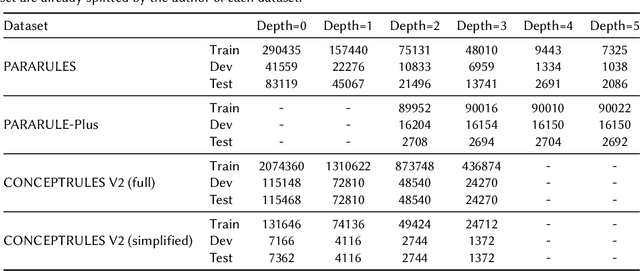
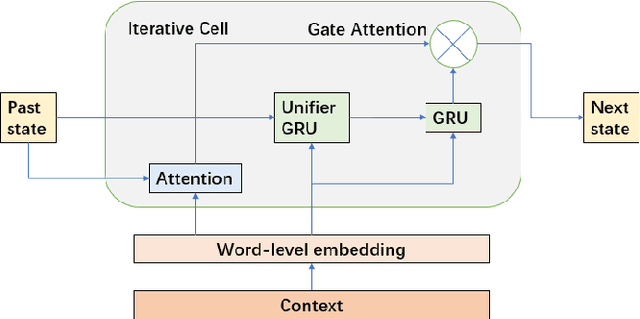
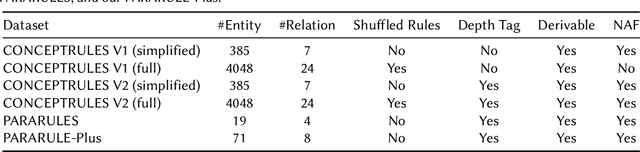
Combining deep learning with symbolic logic reasoning aims to capitalize on the success of both fields and is drawing increasing attention. Inspired by DeepLogic, an end-to-end model trained to perform inference on logic programs, we introduce IMA-GloVe-GA, an iterative neural inference network for multi-step reasoning expressed in natural language. In our model, reasoning is performed using an iterative memory neural network based on RNN with a gate attention mechanism. We evaluate IMA-GloVe-GA on three datasets: PARARULES, CONCEPTRULES V1 and CONCEPTRULES V2. Experimental results show DeepLogic with gate attention can achieve higher test accuracy than DeepLogic and other RNN baseline models. Our model achieves better out-of-distribution generalisation than RoBERTa-Large when the rules have been shuffled. Furthermore, to address the issue of unbalanced distribution of reasoning depths in the current multi-step reasoning datasets, we develop PARARULE-Plus, a large dataset with more examples that require deeper reasoning steps. Experimental results show that the addition of PARARULE-Plus can increase the model's performance on examples requiring deeper reasoning depths. The source code and data are available at https://github.com/Strong-AI-Lab/Multi-Step-Deductive-Reasoning-Over-Natural-Language.
Relating Blindsight and AI: A Review
Dec 09, 2021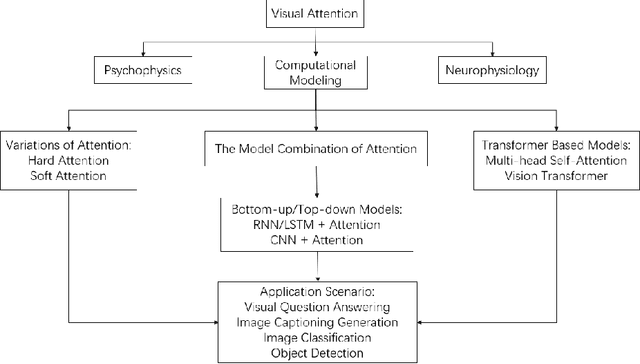
Processes occurring in brains, a.k.a. biological neural networks, can and have been modeled within artificial neural network architectures. Due to this, we have conducted a review of research on the phenomenon of blindsight in an attempt to generate ideas for artificial intelligence models. Blindsight can be considered as a diminished form of visual experience. If we assume that artificial networks have no form of visual experience, then deficits caused by blindsight give us insights into the processes occurring within visual experience that we can incorporate into artificial neural networks. This article has been structured into three parts. Section 2 is a review of blindsight research, looking specifically at the errors occurring during this condition compared to normal vision. Section 3 identifies overall patterns from Section 2 to generate insights for computational models of vision. Section 4 demonstrates the utility of examining biological research to inform artificial intelligence research by examining computation models of visual attention relevant to one of the insights generated in Section 3. The research covered in Section 4 shows that incorporating one of our insights into computational vision does benefit those models. Future research will be required to determine whether our other insights are as valuable.
* Preprint of an article published in Journal of Artificial Intelligence and Consciousness, 2021 doi.org/10.1142/S2705078521500156 \c{opyright} copyright World Scientific Publishing Company www.worldscientific.com/worldscinet/jaic