 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttacking the Loop: Adversarial Attacks on Graph-based Loop Closure Detection
Dec 12, 2023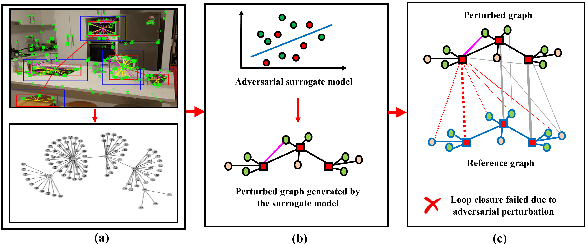
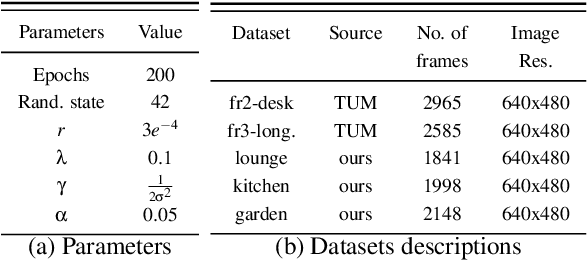
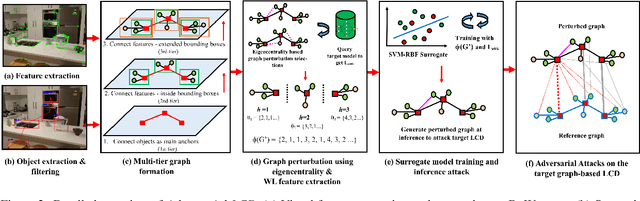
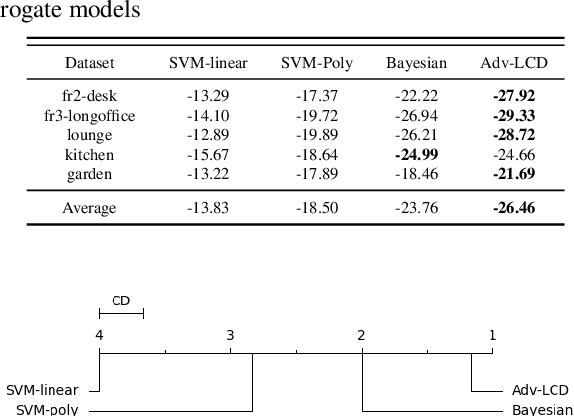
With the advancement in robotics, it is becoming increasingly common for large factories and warehouses to incorporate visual SLAM (vSLAM) enabled automated robots that operate closely next to humans. This makes any adversarial attacks on vSLAM components potentially detrimental to humans working alongside them. Loop Closure Detection (LCD) is a crucial component in vSLAM that minimizes the accumulation of drift in mapping, since even a small drift can accumulate into a significant drift over time. A prior work by Kim et al., SymbioLCD2, unified visual features and semantic objects into a single graph structure for finding loop closure candidates. While this provided a performance improvement over visual feature-based LCD, it also created a single point of vulnerability for potential graph-based adversarial attacks. Unlike previously reported visual-patch based attacks, small graph perturbations are far more challenging to detect, making them a more significant threat. In this paper, we present Adversarial-LCD, a novel black-box evasion attack framework that employs an eigencentrality-based perturbation method and an SVM-RBF surrogate model with a Weisfeiler-Lehman feature extractor for attacking graph-based LCD. Our evaluation shows that the attack performance of Adversarial-LCD with the SVM-RBF surrogate model was superior to that of other machine learning surrogate algorithms, including SVM-linear, SVM-polynomial, and Bayesian classifier, demonstrating the effectiveness of our attack framework. Furthermore, we show that our eigencentrality-based perturbation method outperforms other algorithms, such as Random-walk and Shortest-path, highlighting the efficiency of Adversarial-LCD's perturbation selection method.
Do Smaller Language Models Answer Contextualised Questions Through Memorisation Or Generalisation?
Nov 21, 2023

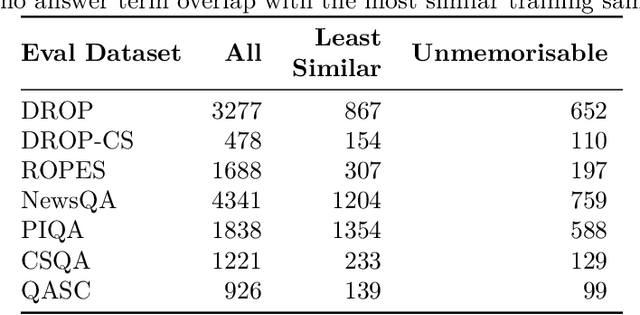

A distinction is often drawn between a model's ability to predict a label for an evaluation sample that is directly memorised from highly similar training samples versus an ability to predict the label via some method of generalisation. In the context of using Language Models for question-answering, discussion continues to occur as to the extent to which questions are answered through memorisation. We consider this issue for questions that would ideally be answered through reasoning over an associated context. We propose a method of identifying evaluation samples for which it is very unlikely our model would have memorised the answers. Our method is based on semantic similarity of input tokens and label tokens between training and evaluation samples. We show that our method offers advantages upon some prior approaches in that it is able to surface evaluation-train pairs that have overlap in either contiguous or discontiguous sequences of tokens. We use this method to identify unmemorisable subsets of our evaluation datasets. We train two Language Models in a multitask fashion whereby the second model differs from the first only in that it has two additional datasets added to the training regime that are designed to impart simple numerical reasoning strategies of a sort known to improve performance on some of our evaluation datasets but not on others. We then show that there is performance improvement between the two models on the unmemorisable subsets of the evaluation datasets that were expected to benefit from the additional training datasets. Specifically, performance on unmemorisable subsets of two of our evaluation datasets, DROP and ROPES significantly improves by 9.0%, and 25.7% respectively while other evaluation datasets have no significant change in performance.
Teaching Smaller Language Models To Generalise To Unseen Compositional Questions
Aug 21, 2023We equip a smaller Language Model to generalise to answering challenging compositional questions that have not been seen in training. To do so we propose a combination of multitask supervised pretraining on up to 93 tasks designed to instill diverse reasoning abilities, and a dense retrieval system that aims to retrieve a set of evidential paragraph fragments. Recent progress in question-answering has been achieved either through prompting methods against very large pretrained Language Models in zero or few-shot fashion, or by fine-tuning smaller models, sometimes in conjunction with information retrieval. We focus on the less explored question of the extent to which zero-shot generalisation can be enabled in smaller models with retrieval against a corpus within which sufficient information to answer a particular question may not exist. We establish strong baselines in this setting for diverse evaluation datasets (StrategyQA, CommonsenseQA, IIRC, DROP, Musique and ARC-DA), and show that performance can be significantly improved by adding retrieval-augmented training datasets which are designed to expose our models to a variety of heuristic reasoning strategies such as weighing partial evidence or ignoring an irrelevant context.
Answering Unseen Questions With Smaller Language Models Using Rationale Generation and Dense Retrieval
Aug 12, 2023
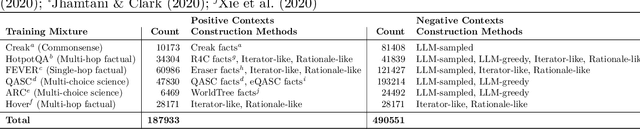

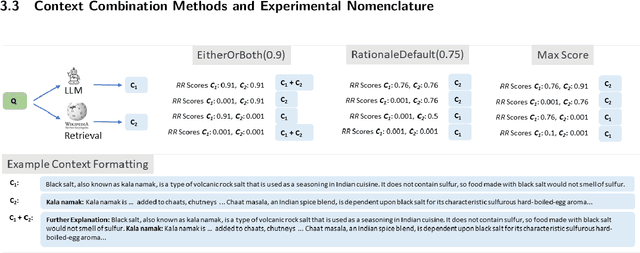
When provided with sufficient explanatory context, smaller Language Models have been shown to exhibit strong reasoning ability on challenging short-answer question-answering tasks where the questions are unseen in training. We evaluate two methods for further improvement in this setting. Both methods focus on combining rationales generated by a larger Language Model with longer contexts created from a multi-hop dense retrieval system. The first method ($\textit{RR}$) involves training a Rationale Ranking model to score both generated rationales and retrieved contexts with respect to relevance and truthfulness. We then use the scores to derive combined contexts from both knowledge sources using a number of combinatory strategies. For the second method ($\textit{RATD}$) we train a smaller Reasoning model using retrieval-augmented training datasets such that it becomes proficient at utilising relevant information from longer text sequences that may be only partially evidential and frequently contain many irrelevant sentences. Generally we find that both methods are effective but that the $\textit{RATD}$ method is more straightforward to apply and produces the strongest results in the unseen setting on which we focus. Our single best Reasoning model using only 440 million parameters materially improves upon strong comparable prior baselines for unseen evaluation datasets (StrategyQA 58.9 $\rightarrow$ 61.7 acc., CommonsenseQA 63.6 $\rightarrow$ 72.7 acc., ARC-DA 31.6 $\rightarrow$ 52.1 F1, IIRC 25.5 $\rightarrow$ 27.3 F1) and a version utilising our prior knowledge of each type of question in selecting a context combination strategy does even better. Our proposed models also generally outperform direct prompts against much larger models (BLOOM 175B and StableVicuna 13B) in both few-shot chain-of-thought and few-shot answer-only settings.
Closing the Loop: Graph Networks to Unify Semantic Objects and Visual Features for Multi-object Scenes
Sep 24, 2022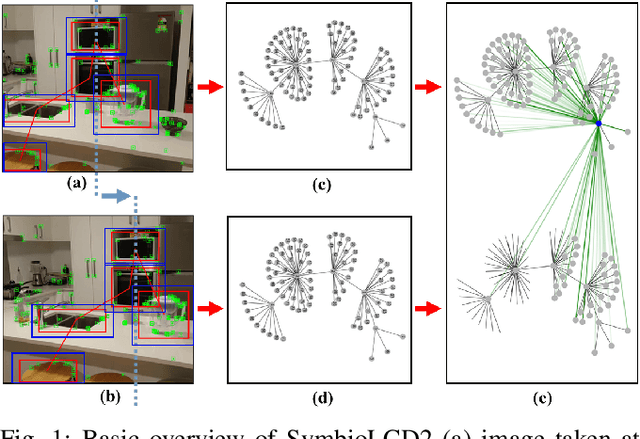
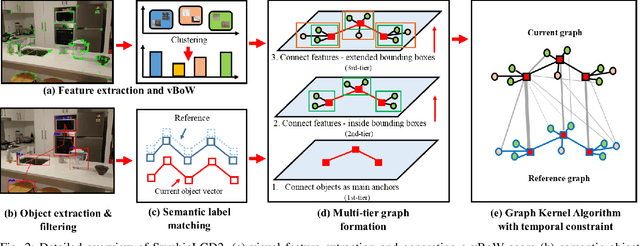

In Simultaneous Localization and Mapping (SLAM), Loop Closure Detection (LCD) is essential to minimize drift when recognizing previously visited places. Visual Bag-of-Words (vBoW) has been an LCD algorithm of choice for many state-of-the-art SLAM systems. It uses a set of visual features to provide robust place recognition but fails to perceive the semantics or spatial relationship between feature points. Previous work has mainly focused on addressing these issues by combining vBoW with semantic and spatial information from objects in the scene. However, they are unable to exploit spatial information of local visual features and lack a structure that unifies semantic objects and visual features, therefore limiting the symbiosis between the two components. This paper proposes SymbioLCD2, which creates a unified graph structure to integrate semantic objects and visual features symbiotically. Our novel graph-based LCD system utilizes the unified graph structure by applying a Weisfeiler-Lehman graph kernel with temporal constraints to robustly predict loop closure candidates. Evaluation of the proposed system shows that having a unified graph structure incorporating semantic objects and visual features improves LCD prediction accuracy, illustrating that the proposed graph structure provides a strong symbiosis between these two complementary components. It also outperforms other Machine Learning algorithms - such as SVM, Decision Tree, Random Forest, Neural Network and GNN based Graph Matching Networks. Furthermore, it has shown good performance in detecting loop closure candidates earlier than state-of-the-art SLAM systems, demonstrating that extended semantic and spatial awareness from the unified graph structure significantly impacts LCD performance.
SymbioLCD: Ensemble-Based Loop Closure Detection using CNN-Extracted Objects and Visual Bag-of-Words
Oct 21, 2021


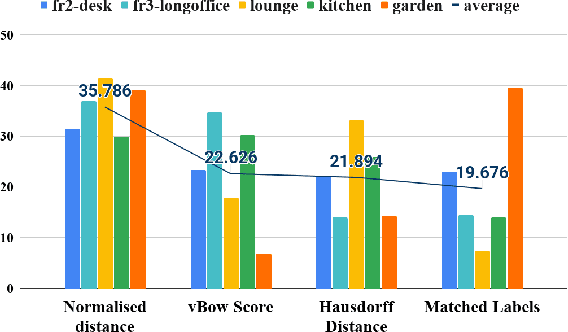
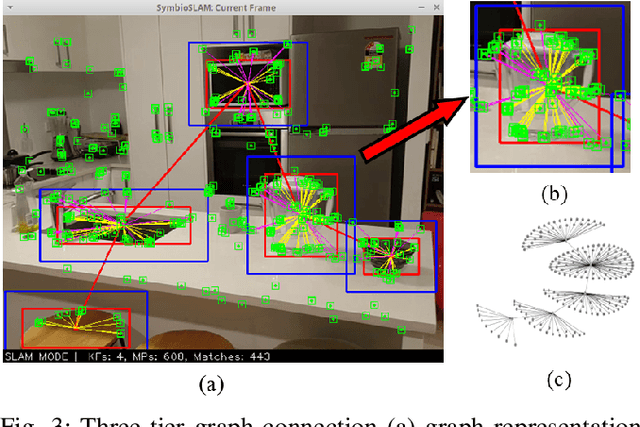
Loop closure detection is an essential tool of Simultaneous Localization and Mapping (SLAM) to minimize drift in its localization. Many state-of-the-art loop closure detection (LCD) algorithms use visual Bag-of-Words (vBoW), which is robust against partial occlusions in a scene but cannot perceive the semantics or spatial relationships between feature points. CNN object extraction can address those issues, by providing semantic labels and spatial relationships between objects in a scene. Previous work has mainly focused on replacing vBoW with CNN-derived features. In this paper, we propose SymbioLCD, a novel ensemble-based LCD that utilizes both CNN-extracted objects and vBoW features for LCD candidate prediction. When used in tandem, the added elements of object semantics and spatial-awareness create a more robust and symbiotic loop closure detection system. The proposed SymbioLCD uses scale-invariant spatial and semantic matching, Hausdorff distance with temporal constraints, and a Random Forest that utilizes combined information from both CNN-extracted objects and vBoW features for predicting accurate loop closure candidates. Evaluation of the proposed method shows it outperforms other Machine Learning (ML) algorithms - such as SVM, Decision Tree and Neural Network, and demonstrates that there is a strong symbiosis between CNN-extracted object information and vBoW features which assists accurate LCD candidate prediction. Furthermore, it is able to perceive loop closure candidates earlier than state-of-the-art SLAM algorithms, utilizing added spatial and semantic information from CNN-extracted objects.