 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlow Matching for Conditional MRI-CT and CBCT-CT Image Synthesis
Oct 06, 2025
Generating synthetic CT (sCT) from MRI or CBCT plays a crucial role in enabling MRI-only and CBCT-based adaptive radiotherapy, improving treatment precision while reducing patient radiation exposure. To address this task, we adopt a fully 3D Flow Matching (FM) framework, motivated by recent work demonstrating FM's efficiency in producing high-quality images. In our approach, a Gaussian noise volume is transformed into an sCT image by integrating a learned FM velocity field, conditioned on features extracted from the input MRI or CBCT using a lightweight 3D encoder. We evaluated the method on the SynthRAD2025 Challenge benchmark, training separate models for MRI $\rightarrow$ sCT and CBCT $\rightarrow$ sCT across three anatomical regions: abdomen, head and neck, and thorax. Validation and testing were performed through the challenge submission system. The results indicate that the method accurately reconstructs global anatomical structures; however, preservation of fine details was limited, primarily due to the relatively low training resolution imposed by memory and runtime constraints. Future work will explore patch-based training and latent-space flow models to improve resolution and local structural fidelity.
Augmentation-based Domain Generalization and Joint Training from Multiple Source Domains for Whole Heart Segmentation
Aug 06, 2025As the leading cause of death worldwide, cardiovascular diseases motivate the development of more sophisticated methods to analyze the heart and its substructures from medical images like Computed Tomography (CT) and Magnetic Resonance (MR). Semantic segmentations of important cardiac structures that represent the whole heart are useful to assess patient-specific cardiac morphology and pathology. Furthermore, accurate semantic segmentations can be used to generate cardiac digital twin models which allows e.g. electrophysiological simulation and personalized therapy planning. Even though deep learning-based methods for medical image segmentation achieved great advancements over the last decade, retaining good performance under domain shift -- i.e. when training and test data are sampled from different data distributions -- remains challenging. In order to perform well on domains known at training-time, we employ a (1) balanced joint training approach that utilizes CT and MR data in equal amounts from different source domains. Further, aiming to alleviate domain shift towards domains only encountered at test-time, we rely on (2) strong intensity and spatial augmentation techniques to greatly diversify the available training data. Our proposed whole heart segmentation method, a 5-fold ensemble with our contributions, achieves the best performance for MR data overall and a performance similar to the best performance for CT data when compared to a model trained solely on CT. With 93.33% DSC and 0.8388 mm ASSD for CT and 89.30% DSC and 1.2411 mm ASSD for MR data, our method demonstrates great potential to efficiently obtain accurate semantic segmentations from which patient-specific cardiac twin models can be generated.
LA-CaRe-CNN: Cascading Refinement CNN for Left Atrial Scar Segmentation
Aug 06, 2025Atrial fibrillation (AF) represents the most prevalent type of cardiac arrhythmia for which treatment may require patients to undergo ablation therapy. In this surgery cardiac tissues are locally scarred on purpose to prevent electrical signals from causing arrhythmia. Patient-specific cardiac digital twin models show great potential for personalized ablation therapy, however, they demand accurate semantic segmentation of healthy and scarred tissue typically obtained from late gadolinium enhanced (LGE) magnetic resonance (MR) scans. In this work we propose the Left Atrial Cascading Refinement CNN (LA-CaRe-CNN), which aims to accurately segment the left atrium as well as left atrial scar tissue from LGE MR scans. LA-CaRe-CNN is a 2-stage CNN cascade that is trained end-to-end in 3D, where Stage 1 generates a prediction for the left atrium, which is then refined in Stage 2 in conjunction with the original image information to obtain a prediction for the left atrial scar tissue. To account for domain shift towards domains unknown during training, we employ strong intensity and spatial augmentation to increase the diversity of the training dataset. Our proposed method based on a 5-fold ensemble achieves great segmentation results, namely, 89.21% DSC and 1.6969 mm ASSD for the left atrium, as well as 64.59% DSC and 91.80% G-DSC for the more challenging left atrial scar tissue. Thus, segmentations obtained through LA-CaRe-CNN show great potential for the generation of patient-specific cardiac digital twin models and downstream tasks like personalized targeted ablation therapy to treat AF.
Gaussian Process Emulators for Few-Shot Segmentation in Cardiac MRI
Nov 12, 2024Segmentation of cardiac magnetic resonance images (MRI) is crucial for the analysis and assessment of cardiac function, helping to diagnose and treat various cardiovascular diseases. Most recent techniques rely on deep learning and usually require an extensive amount of labeled data. To overcome this problem, few-shot learning has the capability of reducing data dependency on labeled data. In this work, we introduce a new method that merges few-shot learning with a U-Net architecture and Gaussian Process Emulators (GPEs), enhancing data integration from a support set for improved performance. GPEs are trained to learn the relation between the support images and the corresponding masks in latent space, facilitating the segmentation of unseen query images given only a small labeled support set at inference. We test our model with the M&Ms-2 public dataset to assess its ability to segment the heart in cardiac magnetic resonance imaging from different orientations, and compare it with state-of-the-art unsupervised and few-shot methods. Our architecture shows higher DICE coefficients compared to these methods, especially in the more challenging setups where the size of the support set is considerably small.
Synthetic Augmentation for Anatomical Landmark Localization using DDPMs
Oct 17, 2024Deep learning techniques for anatomical landmark localization (ALL) have shown great success, but their reliance on large annotated datasets remains a problem due to the tedious and costly nature of medical data acquisition and annotation. While traditional data augmentation, variational autoencoders (VAEs), and generative adversarial networks (GANs) have already been used to synthetically expand medical datasets, diffusion-based generative models have recently started to gain attention for their ability to generate high-quality synthetic images. In this study, we explore the use of denoising diffusion probabilistic models (DDPMs) for generating medical images and their corresponding heatmaps of landmarks to enhance the training of a supervised deep learning model for ALL. Our novel approach involves a DDPM with a 2-channel input, incorporating both the original medical image and its heatmap of annotated landmarks. We also propose a novel way to assess the quality of the generated images using a Markov Random Field (MRF) model for landmark matching and a Statistical Shape Model (SSM) to check landmark plausibility, before we evaluate the DDPM-augmented dataset in the context of an ALL task involving hand X-Rays.
Feature graphs for interpretable unsupervised tree ensembles: centrality, interaction, and application in disease subtyping
Apr 27, 2024Interpretable machine learning has emerged as central in leveraging artificial intelligence within high-stakes domains such as healthcare, where understanding the rationale behind model predictions is as critical as achieving high predictive accuracy. In this context, feature selection assumes a pivotal role in enhancing model interpretability by identifying the most important input features in black-box models. While random forests are frequently used in biomedicine for their remarkable performance on tabular datasets, the accuracy gained from aggregating decision trees comes at the expense of interpretability. Consequently, feature selection for enhancing interpretability in random forests has been extensively explored in supervised settings. However, its investigation in the unsupervised regime remains notably limited. To address this gap, the study introduces novel methods to construct feature graphs from unsupervised random forests and feature selection strategies to derive effective feature combinations from these graphs. Feature graphs are constructed for the entire dataset as well as individual clusters leveraging the parent-child node splits within the trees, such that feature centrality captures their relevance to the clustering task, while edge weights reflect the discriminating power of feature pairs. Graph-based feature selection methods are extensively evaluated on synthetic and benchmark datasets both in terms of their ability to reduce dimensionality while improving clustering performance, as well as to enhance model interpretability. An application on omics data for disease subtyping identifies the top features for each cluster, showcasing the potential of the proposed approach to enhance interpretability in clustering analyses and its utility in a real-world biomedical application.
Federated unsupervised random forest for privacy-preserving patient stratification
Jan 29, 2024In the realm of precision medicine, effective patient stratification and disease subtyping demand innovative methodologies tailored for multi-omics data. Clustering techniques applied to multi-omics data have become instrumental in identifying distinct subgroups of patients, enabling a finer-grained understanding of disease variability. This work establishes a powerful framework for advancing precision medicine through unsupervised random-forest-based clustering and federated computing. We introduce a novel multi-omics clustering approach utilizing unsupervised random-forests. The unsupervised nature of the random forest enables the determination of cluster-specific feature importance, unraveling key molecular contributors to distinct patient groups. Moreover, our methodology is designed for federated execution, a crucial aspect in the medical domain where privacy concerns are paramount. We have validated our approach on machine learning benchmark data sets as well as on cancer data from The Cancer Genome Atlas (TCGA). Our method is competitive with the state-of-the-art in terms of disease subtyping, but at the same time substantially improves the cluster interpretability. Experiments indicate that local clustering performance can be improved through federated computing.
Teeth Localization and Lesion Segmentation in CBCT Images using SpatialConfiguration-Net and U-Net
Dec 19, 2023The localization of teeth and segmentation of periapical lesions in cone-beam computed tomography (CBCT) images are crucial tasks for clinical diagnosis and treatment planning, which are often time-consuming and require a high level of expertise. However, automating these tasks is challenging due to variations in shape, size, and orientation of lesions, as well as similar topologies among teeth. Moreover, the small volumes occupied by lesions in CBCT images pose a class imbalance problem that needs to be addressed. In this study, we propose a deep learning-based method utilizing two convolutional neural networks: the SpatialConfiguration-Net (SCN) and a modified version of the U-Net. The SCN accurately predicts the coordinates of all teeth present in an image, enabling precise cropping of teeth volumes that are then fed into the U-Net which detects lesions via segmentation. To address class imbalance, we compare the performance of three reweighting loss functions. After evaluation on 144 CBCT images, our method achieves a 97.3% accuracy for teeth localization, along with a promising sensitivity and specificity of 0.97 and 0.88, respectively, for subsequent lesion detection.
CaRe-CNN: Cascading Refinement CNN for Myocardial Infarct Segmentation with Microvascular Obstructions
Dec 19, 2023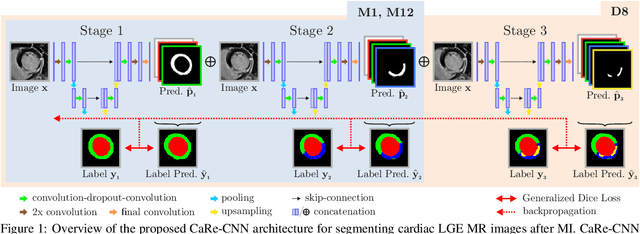
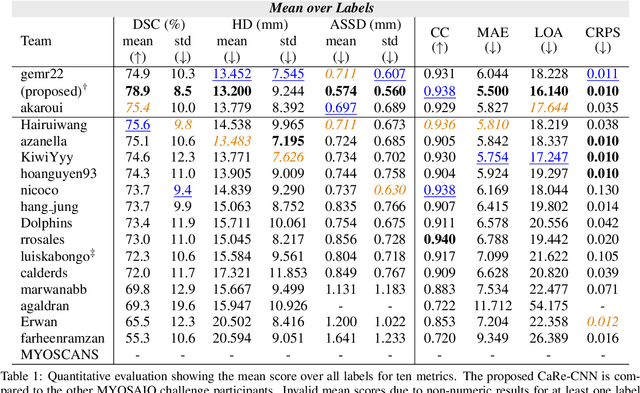
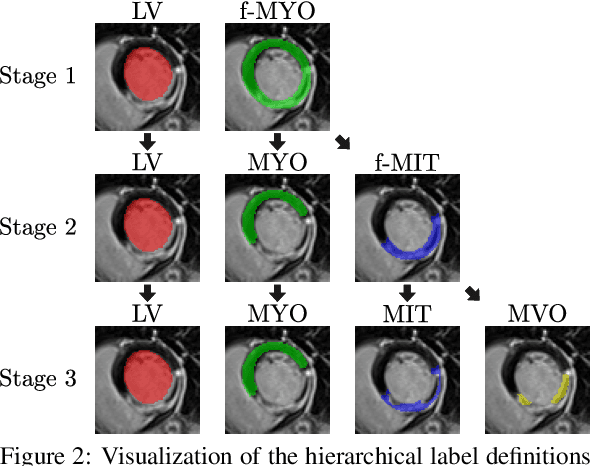
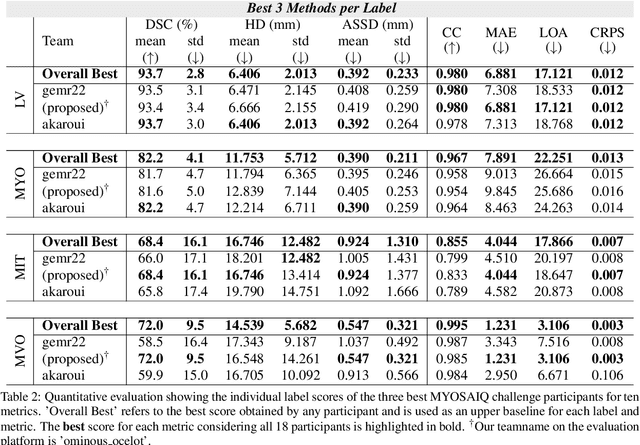
Late gadolinium enhanced (LGE) magnetic resonance (MR) imaging is widely established to assess the viability of myocardial tissue of patients after acute myocardial infarction (MI). We propose the Cascading Refinement CNN (CaRe-CNN), which is a fully 3D, end-to-end trained, 3-stage CNN cascade that exploits the hierarchical structure of such labeled cardiac data. Throughout the three stages of the cascade, the label definition changes and CaRe-CNN learns to gradually refine its intermediate predictions accordingly. Furthermore, to obtain more consistent qualitative predictions, we propose a series of post-processing steps that take anatomical constraints into account. Our CaRe-CNN was submitted to the FIMH 2023 MYOSAIQ challenge, where it ranked second out of 18 participating teams. CaRe-CNN showed great improvements most notably when segmenting the difficult but clinically most relevant myocardial infarct tissue (MIT) as well as microvascular obstructions (MVO). When computing the average scores over all labels, our method obtained the best score in eight out of ten metrics. Thus, accurate cardiac segmentation after acute MI via our CaRe-CNN allows generating patient-specific models of the heart serving as an important step towards personalized medicine.
Attacking the Loop: Adversarial Attacks on Graph-based Loop Closure Detection
Dec 12, 2023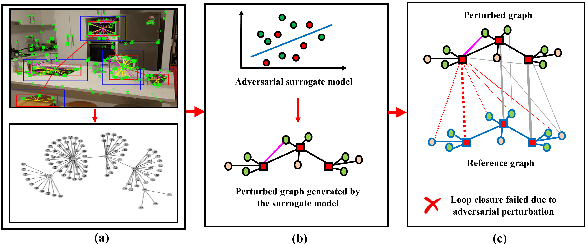
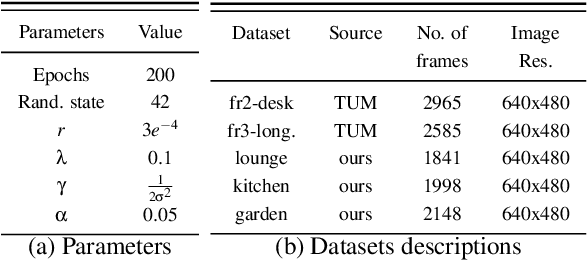
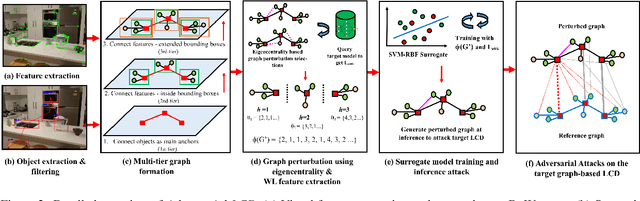
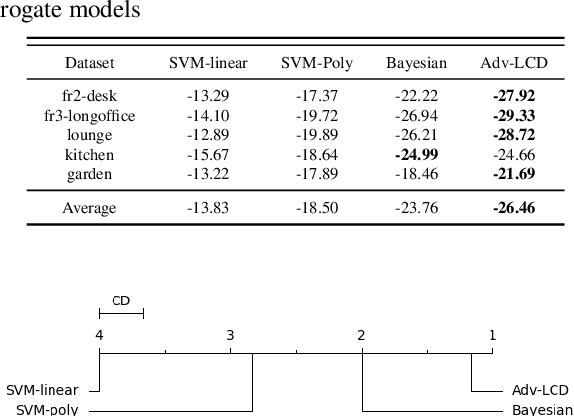
With the advancement in robotics, it is becoming increasingly common for large factories and warehouses to incorporate visual SLAM (vSLAM) enabled automated robots that operate closely next to humans. This makes any adversarial attacks on vSLAM components potentially detrimental to humans working alongside them. Loop Closure Detection (LCD) is a crucial component in vSLAM that minimizes the accumulation of drift in mapping, since even a small drift can accumulate into a significant drift over time. A prior work by Kim et al., SymbioLCD2, unified visual features and semantic objects into a single graph structure for finding loop closure candidates. While this provided a performance improvement over visual feature-based LCD, it also created a single point of vulnerability for potential graph-based adversarial attacks. Unlike previously reported visual-patch based attacks, small graph perturbations are far more challenging to detect, making them a more significant threat. In this paper, we present Adversarial-LCD, a novel black-box evasion attack framework that employs an eigencentrality-based perturbation method and an SVM-RBF surrogate model with a Weisfeiler-Lehman feature extractor for attacking graph-based LCD. Our evaluation shows that the attack performance of Adversarial-LCD with the SVM-RBF surrogate model was superior to that of other machine learning surrogate algorithms, including SVM-linear, SVM-polynomial, and Bayesian classifier, demonstrating the effectiveness of our attack framework. Furthermore, we show that our eigencentrality-based perturbation method outperforms other algorithms, such as Random-walk and Shortest-path, highlighting the efficiency of Adversarial-LCD's perturbation selection method.