 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Systematic Evaluation of Large Language Models on Out-of-Distribution Logical Reasoning Tasks
Oct 18, 2023

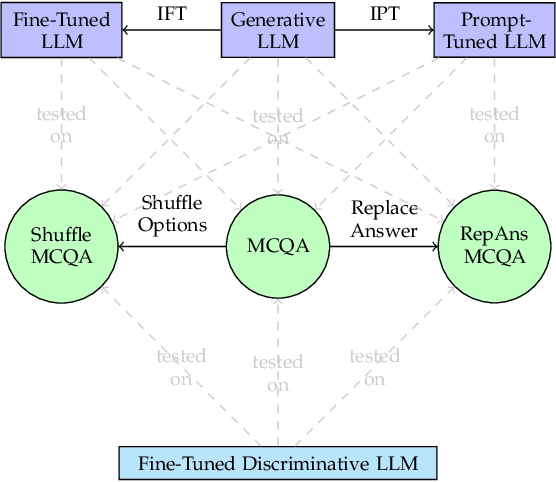

Large language models (LLMs), such as GPT-3.5 and GPT-4, have greatly advanced the performance of artificial systems on various natural language processing tasks to human-like levels. However, their generalisation and robustness to perform logical reasoning remain under-evaluated. To probe this ability, we propose three new logical reasoning datasets named "ReClor-plus", "LogiQA-plus" and "LogiQAv2-plus", each featuring three subsets: the first with randomly shuffled options, the second with the correct choices replaced by "none of the other options are correct", and a combination of the previous two subsets. We carry out experiments on these datasets with both discriminative and generative LLMs and show that these simple tricks greatly hinder the performance of the language models. Despite their superior performance on the original publicly available datasets, we find that all models struggle to answer our newly constructed datasets. We show that introducing task variations by perturbing a sizable training set can markedly improve the model's generalisation and robustness in logical reasoning tasks. Moreover, applying logic-driven data augmentation for fine-tuning, combined with prompting can enhance the generalisation performance of both discriminative large language models and generative large language models. These results offer insights into assessing and improving the generalisation and robustness of large language models for logical reasoning tasks. We make our source code and data publicly available \url{https://github.com/Strong-AI-Lab/Logical-and-abstract-reasoning}.
Teaching Smaller Language Models To Generalise To Unseen Compositional Questions
Aug 21, 2023We equip a smaller Language Model to generalise to answering challenging compositional questions that have not been seen in training. To do so we propose a combination of multitask supervised pretraining on up to 93 tasks designed to instill diverse reasoning abilities, and a dense retrieval system that aims to retrieve a set of evidential paragraph fragments. Recent progress in question-answering has been achieved either through prompting methods against very large pretrained Language Models in zero or few-shot fashion, or by fine-tuning smaller models, sometimes in conjunction with information retrieval. We focus on the less explored question of the extent to which zero-shot generalisation can be enabled in smaller models with retrieval against a corpus within which sufficient information to answer a particular question may not exist. We establish strong baselines in this setting for diverse evaluation datasets (StrategyQA, CommonsenseQA, IIRC, DROP, Musique and ARC-DA), and show that performance can be significantly improved by adding retrieval-augmented training datasets which are designed to expose our models to a variety of heuristic reasoning strategies such as weighing partial evidence or ignoring an irrelevant context.
Contrastive Learning with Logic-driven Data Augmentation for Logical Reasoning over Text
May 21, 2023Pre-trained large language model (LLM) is under exploration to perform NLP tasks that may require logical reasoning. Logic-driven data augmentation for representation learning has been shown to improve the performance of tasks requiring logical reasoning, but most of these data rely on designed templates and therefore lack generalization. In this regard, we propose an AMR-based logical equivalence-driven data augmentation method (AMR-LE) for generating logically equivalent data. Specifically, we first parse a text into the form of an AMR graph, next apply four logical equivalence laws (contraposition, double negation, commutative and implication laws) on the AMR graph to construct a logically equivalent/inequivalent AMR graph, and then convert it into a logically equivalent/inequivalent sentence. To help the model to better learn these logical equivalence laws, we propose a logical equivalence-driven contrastive learning training paradigm, which aims to distinguish the difference between logical equivalence and inequivalence. Our AMR-LE (Ensemble) achieves #2 on the ReClor leaderboard https://eval.ai/web/challenges/challenge-page/503/leaderboard/1347 . Our model shows better performance on seven downstream tasks, including ReClor, LogiQA, MNLI, MRPC, RTE, QNLI, and QQP. The source code and dataset are public at https://github.com/Strong-AI-Lab/Logical-Equivalence-driven-AMR-Data-Augmentation-for-Representation-Learning .
Multi-Step Deductive Reasoning Over Natural Language: An Empirical Study on Out-of-Distribution Generalisation
Jul 28, 2022
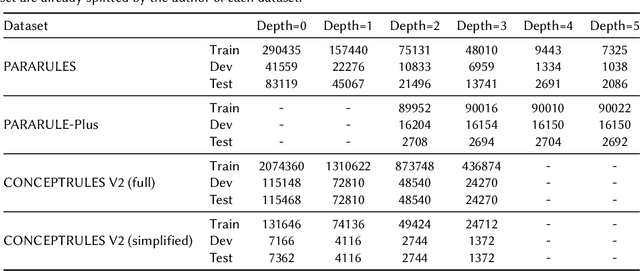
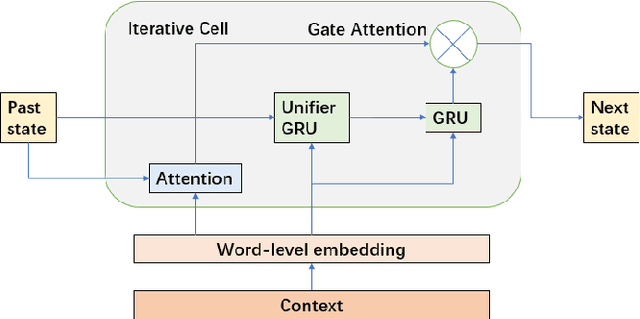
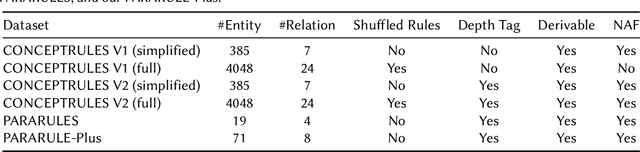
Combining deep learning with symbolic logic reasoning aims to capitalize on the success of both fields and is drawing increasing attention. Inspired by DeepLogic, an end-to-end model trained to perform inference on logic programs, we introduce IMA-GloVe-GA, an iterative neural inference network for multi-step reasoning expressed in natural language. In our model, reasoning is performed using an iterative memory neural network based on RNN with a gate attention mechanism. We evaluate IMA-GloVe-GA on three datasets: PARARULES, CONCEPTRULES V1 and CONCEPTRULES V2. Experimental results show DeepLogic with gate attention can achieve higher test accuracy than DeepLogic and other RNN baseline models. Our model achieves better out-of-distribution generalisation than RoBERTa-Large when the rules have been shuffled. Furthermore, to address the issue of unbalanced distribution of reasoning depths in the current multi-step reasoning datasets, we develop PARARULE-Plus, a large dataset with more examples that require deeper reasoning steps. Experimental results show that the addition of PARARULE-Plus can increase the model's performance on examples requiring deeper reasoning depths. The source code and data are available at https://github.com/Strong-AI-Lab/Multi-Step-Deductive-Reasoning-Over-Natural-Language.