 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Systematic Evaluation of Large Language Models on Out-of-Distribution Logical Reasoning Tasks
Paper and Code


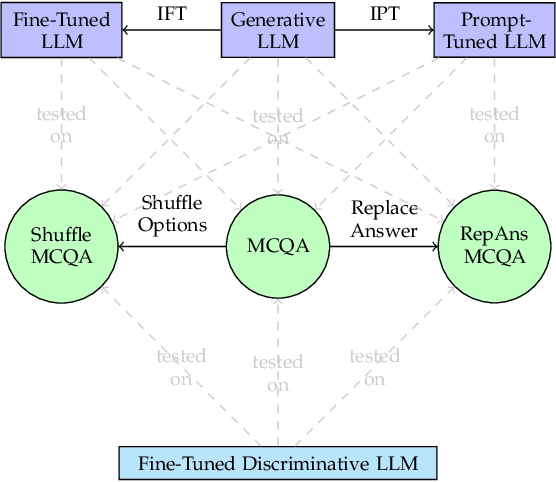

Large language models (LLMs), such as GPT-3.5 and GPT-4, have greatly advanced the performance of artificial systems on various natural language processing tasks to human-like levels. However, their generalisation and robustness to perform logical reasoning remain under-evaluated. To probe this ability, we propose three new logical reasoning datasets named "ReClor-plus", "LogiQA-plus" and "LogiQAv2-plus", each featuring three subsets: the first with randomly shuffled options, the second with the correct choices replaced by "none of the other options are correct", and a combination of the previous two subsets. We carry out experiments on these datasets with both discriminative and generative LLMs and show that these simple tricks greatly hinder the performance of the language models. Despite their superior performance on the original publicly available datasets, we find that all models struggle to answer our newly constructed datasets. We show that introducing task variations by perturbing a sizable training set can markedly improve the model's generalisation and robustness in logical reasoning tasks. Moreover, applying logic-driven data augmentation for fine-tuning, combined with prompting can enhance the generalisation performance of both discriminative large language models and generative large language models. These results offer insights into assessing and improving the generalisation and robustness of large language models for logical reasoning tasks. We make our source code and data publicly available \url{https://github.com/Strong-AI-Lab/Logical-and-abstract-reasoning}.