 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnswering Unseen Questions With Smaller Language Models Using Rationale Generation and Dense Retrieval
Aug 12, 2023
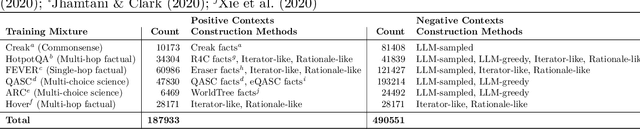

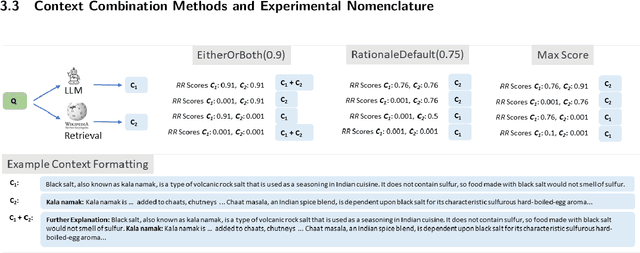
When provided with sufficient explanatory context, smaller Language Models have been shown to exhibit strong reasoning ability on challenging short-answer question-answering tasks where the questions are unseen in training. We evaluate two methods for further improvement in this setting. Both methods focus on combining rationales generated by a larger Language Model with longer contexts created from a multi-hop dense retrieval system. The first method ($\textit{RR}$) involves training a Rationale Ranking model to score both generated rationales and retrieved contexts with respect to relevance and truthfulness. We then use the scores to derive combined contexts from both knowledge sources using a number of combinatory strategies. For the second method ($\textit{RATD}$) we train a smaller Reasoning model using retrieval-augmented training datasets such that it becomes proficient at utilising relevant information from longer text sequences that may be only partially evidential and frequently contain many irrelevant sentences. Generally we find that both methods are effective but that the $\textit{RATD}$ method is more straightforward to apply and produces the strongest results in the unseen setting on which we focus. Our single best Reasoning model using only 440 million parameters materially improves upon strong comparable prior baselines for unseen evaluation datasets (StrategyQA 58.9 $\rightarrow$ 61.7 acc., CommonsenseQA 63.6 $\rightarrow$ 72.7 acc., ARC-DA 31.6 $\rightarrow$ 52.1 F1, IIRC 25.5 $\rightarrow$ 27.3 F1) and a version utilising our prior knowledge of each type of question in selecting a context combination strategy does even better. Our proposed models also generally outperform direct prompts against much larger models (BLOOM 175B and StableVicuna 13B) in both few-shot chain-of-thought and few-shot answer-only settings.
Neuromodulation Gated Transformer
May 11, 2023We introduce a novel architecture, the Neuromodulation Gated Transformer (NGT), which is a simple implementation of neuromodulation in transformers via a multiplicative effect. We compare it to baselines and show that it results in the best average performance on the SuperGLUE benchmark validation sets.
A Theory for Knowledge Transfer in Continual Learning
Aug 14, 2022

Continual learning of a stream of tasks is an active area in deep neural networks. The main challenge investigated has been the phenomenon of catastrophic forgetting or interference of newly acquired knowledge with knowledge from previous tasks. Recent work has investigated forward knowledge transfer to new tasks. Backward transfer for improving knowledge gained during previous tasks has received much less attention. There is in general limited understanding of how knowledge transfer could aid tasks learned continually. We present a theory for knowledge transfer in continual supervised learning, which considers both forward and backward transfer. We aim at understanding their impact for increasingly knowledgeable learners. We derive error bounds for each of these transfer mechanisms. These bounds are agnostic to specific implementations (e.g. deep neural networks). We demonstrate that, for a continual learner that observes related tasks, both forward and backward transfer can contribute to an increasing performance as more tasks are observed.