 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIdentification of NMF by choosing maximum-volume basis vectors
Mar 25, 2026In nonnegative matrix factorization (NMF), minimum-volume-constrained NMF is a widely used framework for identifying the solution of NMF by making basis vectors as similar as possible. This typically induces sparsity in the coefficient matrix, with each row containing zero entries. Consequently, minimum-volume-constrained NMF may fail for highly mixed data, where such sparsity does not hold. Moreover, the estimated basis vectors in minimum-volume-constrained NMF may be difficult to interpret as they may be mixtures of the ground truth basis vectors. To address these limitations, in this paper we propose a new NMF framework, called maximum-volume-constrained NMF, which makes the basis vectors as distinct as possible. We further establish an identifiability theorem for maximum-volume-constrained NMF and provide an algorithm to estimate it. Experimental results demonstrate the effectiveness of the proposed method.
A review of NMF, PLSA, LBA, EMA, and LCA with a focus on the identifiability issue
Dec 25, 2025Across fields such as machine learning, social science, geography, considerable attention has been given to models that factorize a nonnegative matrix into the product of two or three matrices, subject to nonnegative or row-sum-to-1 constraints. Although these models are to a large extend similar or even equivalent, they are presented under different names, and their similarity is not well known. This paper highlights similarities among five popular models, latent budget analysis (LBA), latent class analysis (LCA), end-member analysis (EMA), probabilistic latent semantic analysis (PLSA), and nonnegative matrix factorization (NMF). We focus on an essential issue-identifiability-of these models and prove that the solution of LBA, EMA, LCA, PLSA is unique if and only if the solution of NMF is unique. We also provide a brief review for algorithms of these models. We illustrate the models with a time budget dataset from social science, and end the paper with a discussion of closely related models such as archetypal analysis.
A comparison of correspondence analysis with PMI-based word embedding methods
May 31, 2024



Popular word embedding methods such as GloVe and Word2Vec are related to the factorization of the pointwise mutual information (PMI) matrix. In this paper, we link correspondence analysis (CA) to the factorization of the PMI matrix. CA is a dimensionality reduction method that uses singular value decomposition (SVD), and we show that CA is mathematically close to the weighted factorization of the PMI matrix. In addition, we present variants of CA that turn out to be successful in the factorization of the word-context matrix, i.e. CA applied to a matrix where the entries undergo a square-root transformation (ROOT-CA) and a root-root transformation (ROOTROOT-CA). An empirical comparison among CA- and PMI-based methods shows that overall results of ROOT-CA and ROOTROOT-CA are slightly better than those of the PMI-based methods.
Improving information retrieval through correspondence analysis instead of latent semantic analysis
Mar 14, 2023Both latent semantic analysis (LSA) and correspondence analysis (CA) are dimensionality reduction techniques that use singular value decomposition (SVD) for information retrieval. Theoretically, the results of LSA display both the association between documents and terms, and marginal effects; in comparison, CA only focuses on the associations between documents and terms. Marginal effects are usually not relevant for information retrieval, and therefore, from a theoretical perspective CA is more suitable for information retrieval. In this paper, we empirically compare LSA and CA. The elements of the raw document-term matrix are weighted, and the weighting exponent of singular values is adjusted to improve the performance of LSA. We explore whether these two weightings also improve the performance of CA. In addition, we compare the optimal singular value weighting exponents for LSA and CA to identify what the initial dimensions in LSA correspond to. The results for four empirical datasets show that CA always performs better than LSA. Weighting the elements of the raw data matrix can improve CA; however, it is data dependent and the improvement is small. Adjusting the singular value weighting exponent usually improves the performance of CA; however, the extent of the improved performance depends on the dataset and number of dimensions. In general, CA needs a larger singular value weighting exponent than LSA to obtain the optimal performance. This indicates that CA emphasizes initial dimensions more than LSA, and thus, margins play an important role in the initial dimensions in LSA.
Prompt-based Conservation Learning for Multi-hop Question Answering
Sep 14, 2022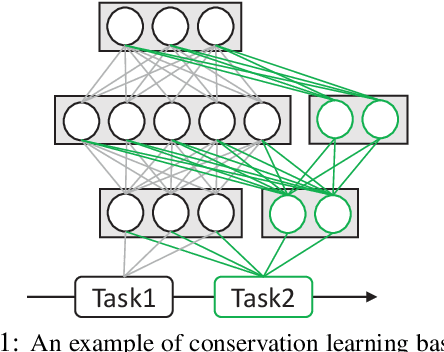
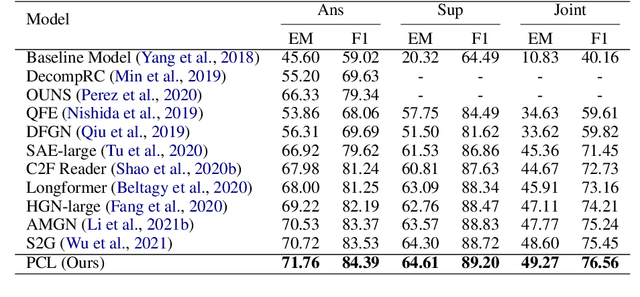
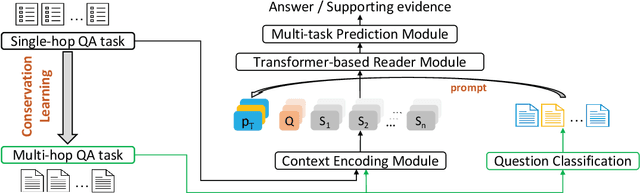
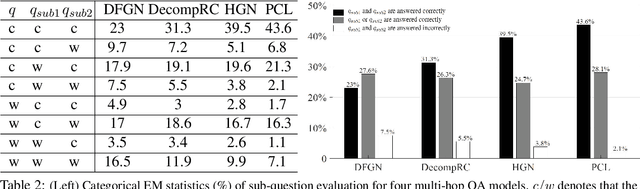
Multi-hop question answering (QA) requires reasoning over multiple documents to answer a complex question and provide interpretable supporting evidence. However, providing supporting evidence is not enough to demonstrate that a model has performed the desired reasoning to reach the correct answer. Most existing multi-hop QA methods fail to answer a large fraction of sub-questions, even if their parent questions are answered correctly. In this paper, we propose the Prompt-based Conservation Learning (PCL) framework for multi-hop QA, which acquires new knowledge from multi-hop QA tasks while conserving old knowledge learned on single-hop QA tasks, mitigating forgetting. Specifically, we first train a model on existing single-hop QA tasks, and then freeze this model and expand it by allocating additional sub-networks for the multi-hop QA task. Moreover, to condition pre-trained language models to stimulate the kind of reasoning required for specific multi-hop questions, we learn soft prompts for the novel sub-networks to perform type-specific reasoning. Experimental results on the HotpotQA benchmark show that PCL is competitive for multi-hop QA and retains good performance on the corresponding single-hop sub-questions, demonstrating the efficacy of PCL in mitigating knowledge loss by forgetting.
DeepQR: Neural-based Quality Ratings for Learnersourced Multiple-Choice Questions
Nov 19, 2021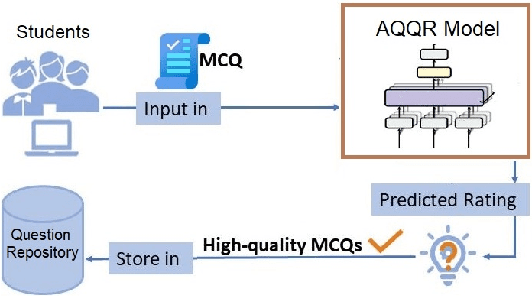
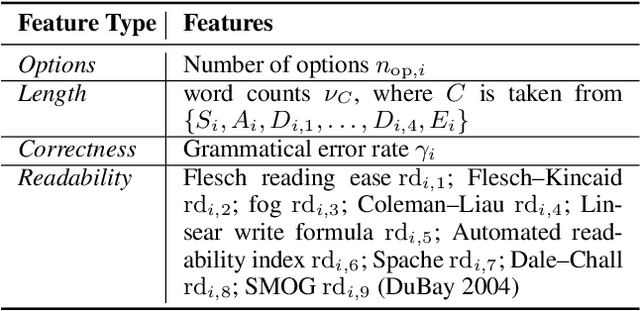
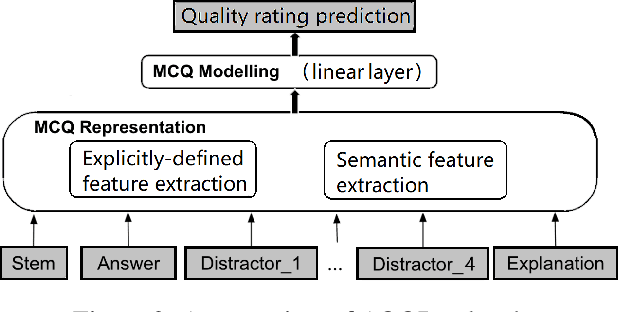
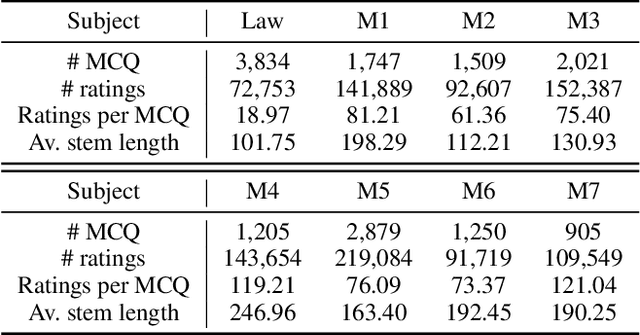
Automated question quality rating (AQQR) aims to evaluate question quality through computational means, thereby addressing emerging challenges in online learnersourced question repositories. Existing methods for AQQR rely solely on explicitly-defined criteria such as readability and word count, while not fully utilising the power of state-of-the-art deep-learning techniques. We propose DeepQR, a novel neural-network model for AQQR that is trained using multiple-choice-question (MCQ) datasets collected from PeerWise, a widely-used learnersourcing platform. Along with designing DeepQR, we investigate models based on explicitly-defined features, or semantic features, or both. We also introduce a self-attention mechanism to capture semantic correlations between MCQ components, and a contrastive-learning approach to acquire question representations using quality ratings. Extensive experiments on datasets collected from eight university-level courses illustrate that DeepQR has superior performance over six comparative models.
A Comparison of Latent Semantic Analysis and Correspondence Analysis for Text Mining
Jul 25, 2021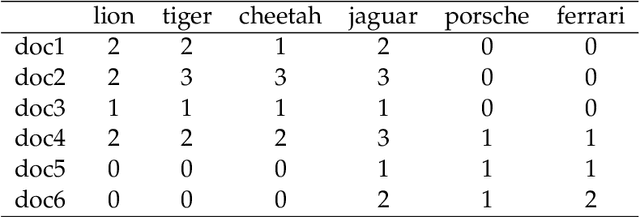
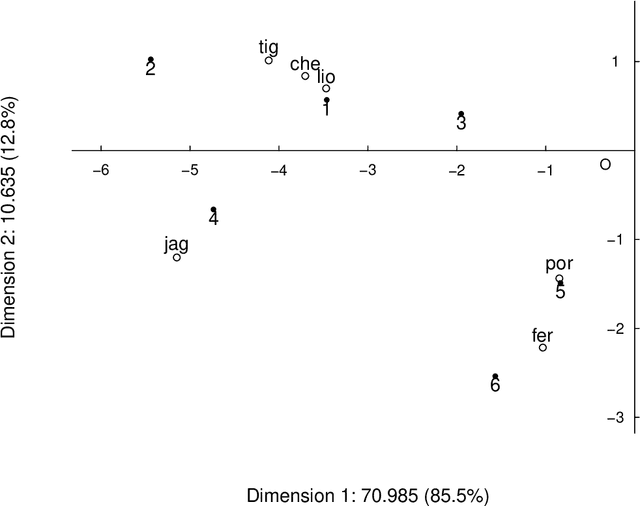
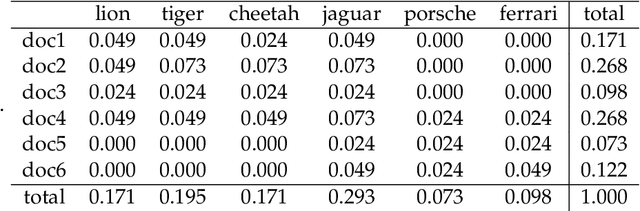
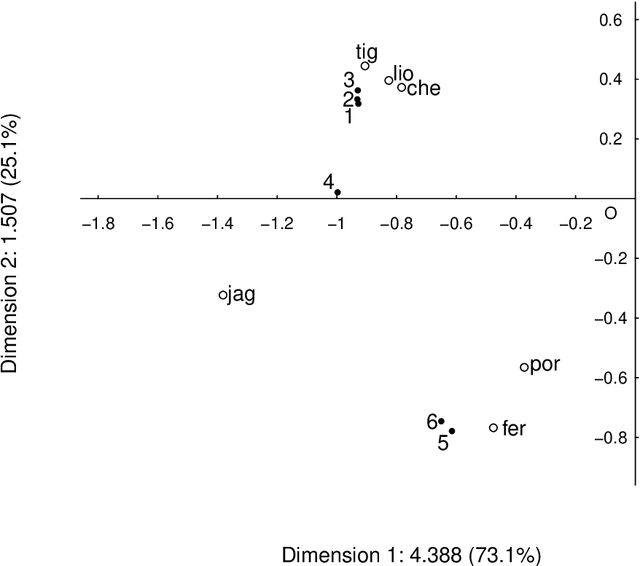
Both latent semantic analysis (LSA) and correspondence analysis (CA) use a singular value decomposition (SVD) for dimensionality reduction. In this article, LSA and CA are compared from a theoretical point of view and applied in both a toy example and an authorship attribution example. In text mining interest goes out to the relationships among documents and terms: for example, what terms are more often used in what documents. However, the LSA solution displays a mix of marginal effects and these relationships. It appears that CA has more attractive properties than LSA. One such property is that, in CA, the effect of the margins is effectively eliminated, so that the CA solution is optimally suited to focus on the relationships among documents and terms. Three mechanisms are distinguished to weight documents and terms, and a unifying framework is proposed that includes these three mechanisms and includes both CA and LSA as special cases. In the authorship attribution example, the national anthem of the Netherlands, the application of the discussed methods is illustrated.